 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn with Generative Models of Neural Network Checkpoints
Sep 26, 2022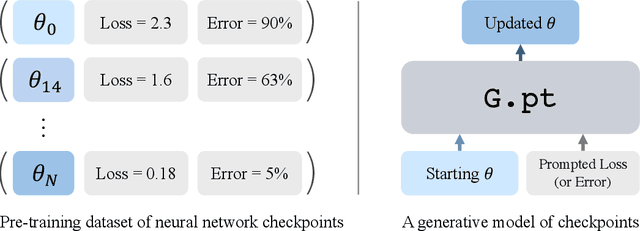
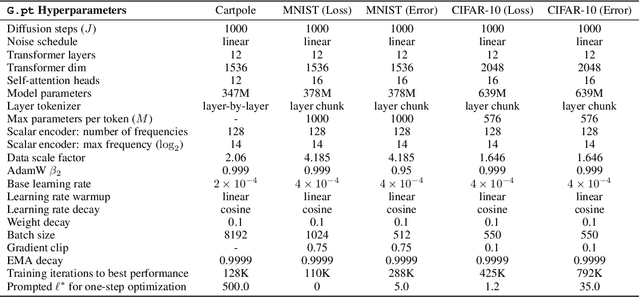
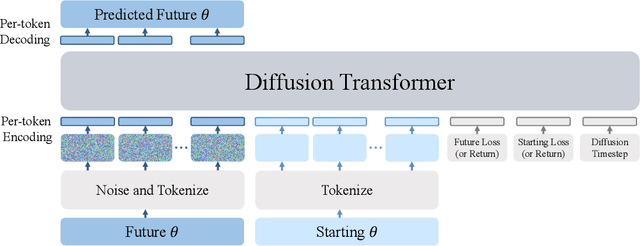
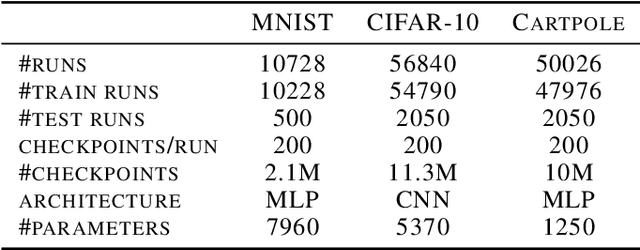
We explore a data-driven approach for learning to optimize neural networks. We construct a dataset of neural network checkpoints and train a generative model on the parameters. In particular, our model is a conditional diffusion transformer that, given an initial input parameter vector and a prompted loss, error, or return, predicts the distribution over parameter updates that achieve the desired metric. At test time, it can optimize neural networks with unseen parameters for downstream tasks in just one update. We find that our approach successfully generates parameters for a wide range of loss prompts. Moreover, it can sample multimodal parameter solutions and has favorable scaling properties. We apply our method to different neural network architectures and tasks in supervised and reinforcement learning.
Masked Visual Pre-training for Motor Control
Mar 11, 2022
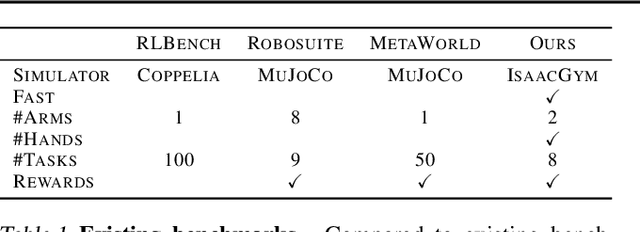
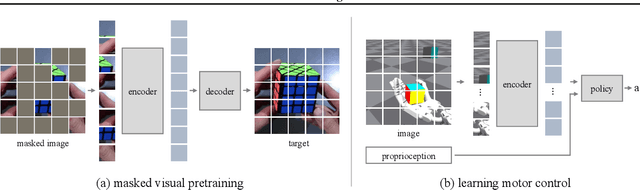

This paper shows that self-supervised visual pre-training from real-world images is effective for learning motor control tasks from pixels. We first train the visual representations by masked modeling of natural images. We then freeze the visual encoder and train neural network controllers on top with reinforcement learning. We do not perform any task-specific fine-tuning of the encoder; the same visual representations are used for all motor control tasks. To the best of our knowledge, this is the first self-supervised model to exploit real-world images at scale for motor control. To accelerate progress in learning from pixels, we contribute a benchmark suite of hand-designed tasks varying in movements, scenes, and robots. Without relying on labels, state-estimation, or expert demonstrations, we consistently outperform supervised encoders by up to 80% absolute success rate, sometimes even matching the oracle state performance. We also find that in-the-wild images, e.g., from YouTube or Egocentric videos, lead to better visual representations for various manipulation tasks than ImageNet images.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Reconstructing Hand-Object Interactions in the Wild
Dec 17, 2020

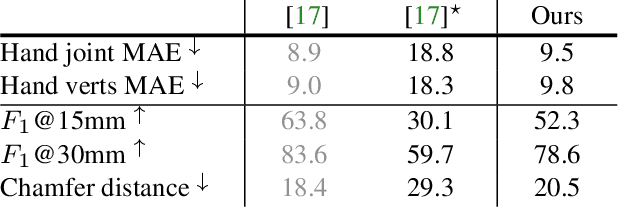
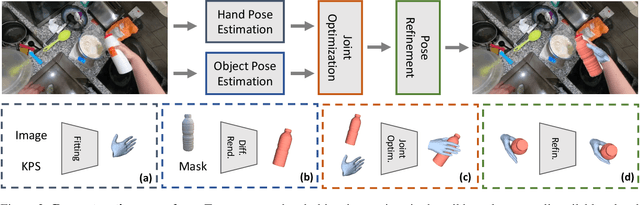
In this work we explore reconstructing hand-object interactions in the wild. The core challenge of this problem is the lack of appropriate 3D labeled data. To overcome this issue, we propose an optimization-based procedure which does not require direct 3D supervision. The general strategy we adopt is to exploit all available related data (2D bounding boxes, 2D hand keypoints, 2D instance masks, 3D object models, 3D in-the-lab MoCap) to provide constraints for the 3D reconstruction. Rather than optimizing the hand and object individually, we optimize them jointly which allows us to impose additional constraints based on hand-object contact, collision, and occlusion. Our method produces compelling reconstructions on the challenging in-the-wild data from the EPIC Kitchens and the 100 Days of Hands datasets, across a range of object categories. Quantitatively, we demonstrate that our approach compares favorably to existing approaches in the lab settings where ground truth 3D annotations are available.
State-Only Imitation Learning for Dexterous Manipulation
Apr 07, 2020
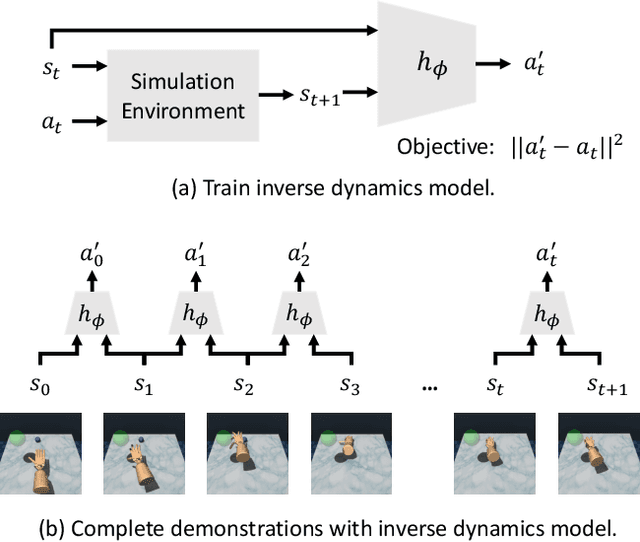

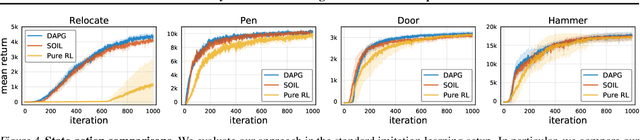
Dexterous manipulation has been a long-standing challenge in robotics. Recently, modern model-free RL has demonstrated impressive results on a number of problems. However, complex domains like dexterous manipulation remain a challenge for RL due to the poor sample complexity. To address this, current approaches employ expert demonstrations in the form of state-action pairs, which are difficult to obtain for real-world settings such as learning from videos. In this work, we move toward a more realistic setting and explore state-only imitation learning. To tackle this setting, we train an inverse dynamics model and use it to predict actions for state-only demonstrations. The inverse dynamics model and the policy are trained jointly. Our method performs on par with state-action approaches and considerably outperforms RL alone. By not relying on expert actions, we are able to learn from demonstrations with different dynamics, morphologies, and objects.
Designing Network Design Spaces
Mar 30, 2020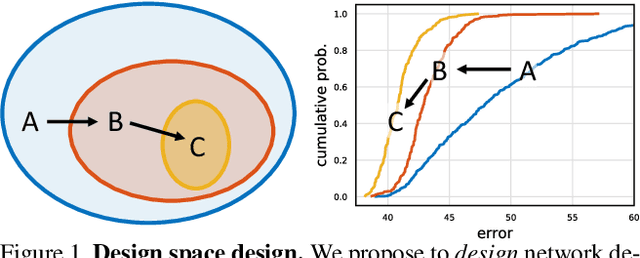
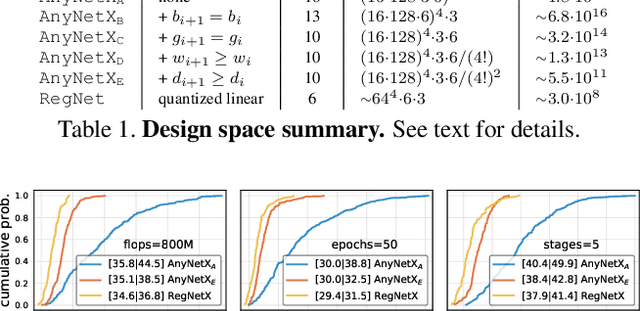
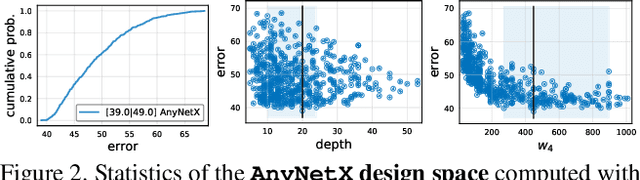
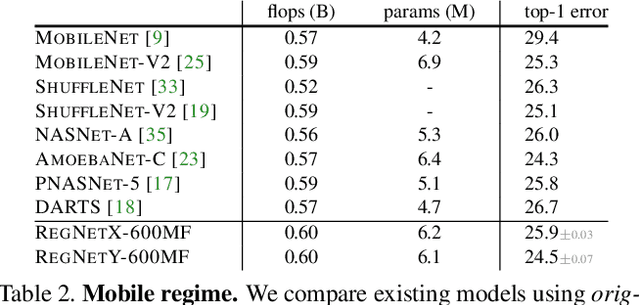
In this work, we present a new network design paradigm. Our goal is to help advance the understanding of network design and discover design principles that generalize across settings. Instead of focusing on designing individual network instances, we design network design spaces that parametrize populations of networks. The overall process is analogous to classic manual design of networks, but elevated to the design space level. Using our methodology we explore the structure aspect of network design and arrive at a low-dimensional design space consisting of simple, regular networks that we call RegNet. The core insight of the RegNet parametrization is surprisingly simple: widths and depths of good networks can be explained by a quantized linear function. We analyze the RegNet design space and arrive at interesting findings that do not match the current practice of network design. The RegNet design space provides simple and fast networks that work well across a wide range of flop regimes. Under comparable training settings and flops, the RegNet models outperform the popular EfficientNet models while being up to 5x faster on GPUs.
On Network Design Spaces for Visual Recognition
May 30, 2019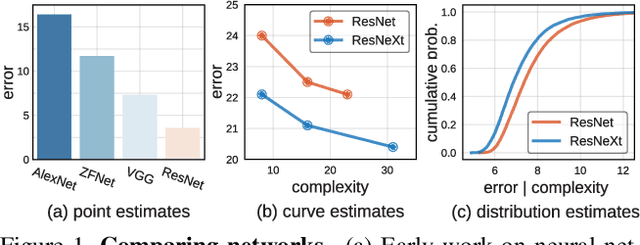

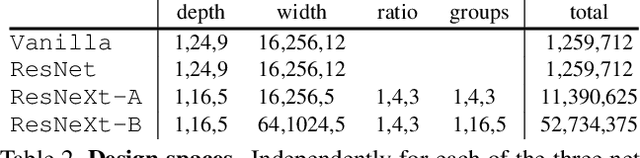
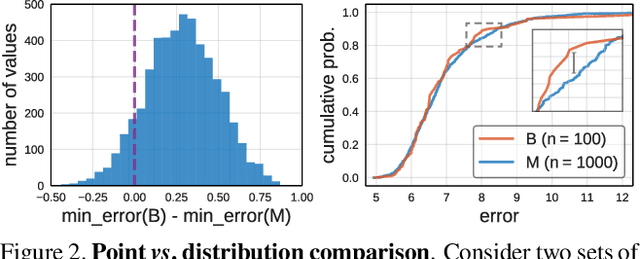
Over the past several years progress in designing better neural network architectures for visual recognition has been substantial. To help sustain this rate of progress, in this work we propose to reexamine the methodology for comparing network architectures. In particular, we introduce a new comparison paradigm of distribution estimates, in which network design spaces are compared by applying statistical techniques to populations of sampled models, while controlling for confounding factors like network complexity. Compared to current methodologies of comparing point and curve estimates of model families, distribution estimates paint a more complete picture of the entire design landscape. As a case study, we examine design spaces used in neural architecture search (NAS). We find significant statistical differences between recent NAS design space variants that have been largely overlooked. Furthermore, our analysis reveals that the design spaces for standard model families like ResNeXt can be comparable to the more complex ones used in recent NAS work. We hope these insights into distribution analysis will enable more robust progress toward discovering better networks for visual recognition.
Attentive Single-Tasking of Multiple Tasks
Apr 18, 2019

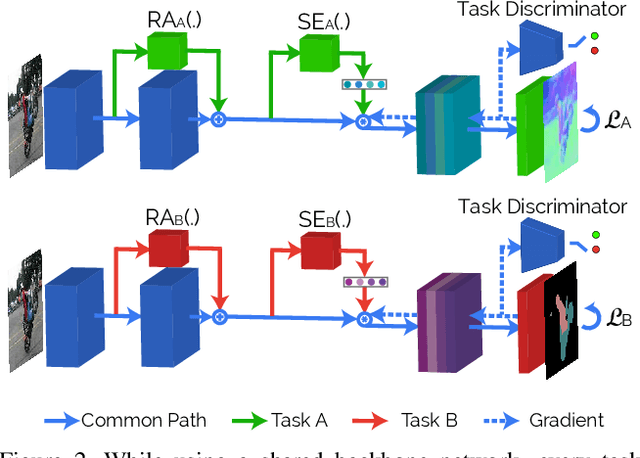
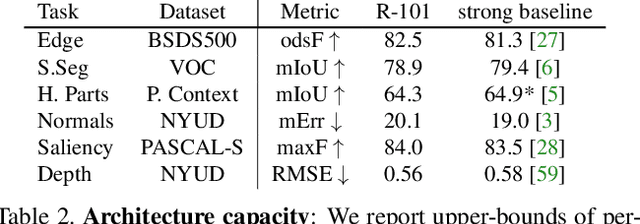
In this work we address task interference in universal networks by considering that a network is trained on multiple tasks, but performs one task at a time, an approach we refer to as "single-tasking multiple tasks". The network thus modifies its behaviour through task-dependent feature adaptation, or task attention. This gives the network the ability to accentuate the features that are adapted to a task, while shunning irrelevant ones. We further reduce task interference by forcing the task gradients to be statistically indistinguishable through adversarial training, ensuring that the common backbone architecture serving all tasks is not dominated by any of the task-specific gradients. Results in three multi-task dense labelling problems consistently show: (i) a large reduction in the number of parameters while preserving, or even improving performance and (ii) a smooth trade-off between computation and multi-task accuracy. We provide our system's code and pre-trained models at http://vision.ee.ethz.ch/~kmaninis/astmt/.
Data Distillation: Towards Omni-Supervised Learning
Dec 12, 2017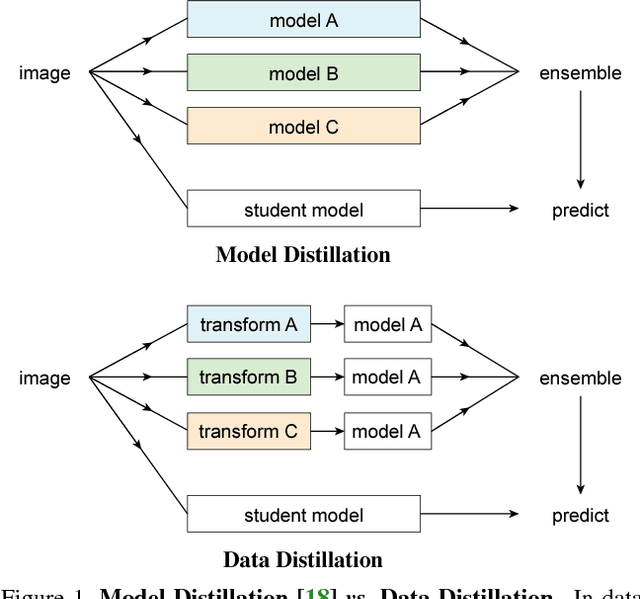
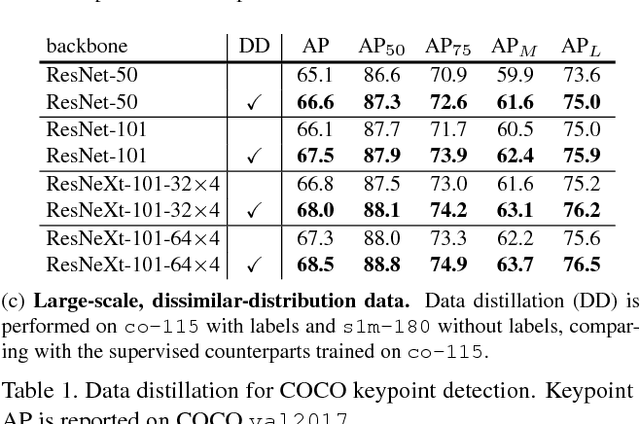

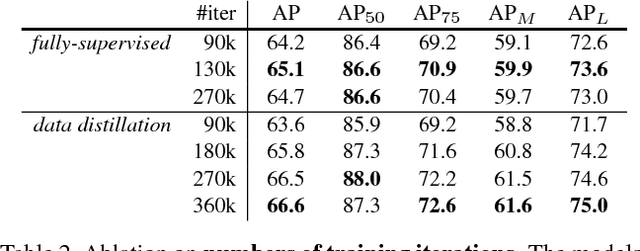
We investigate omni-supervised learning, a special regime of semi-supervised learning in which the learner exploits all available labeled data plus internet-scale sources of unlabeled data. Omni-supervised learning is lower-bounded by performance on existing labeled datasets, offering the potential to surpass state-of-the-art fully supervised methods. To exploit the omni-supervised setting, we propose data distillation, a method that ensembles predictions from multiple transformations of unlabeled data, using a single model, to automatically generate new training annotations. We argue that visual recognition models have recently become accurate enough that it is now possible to apply classic ideas about self-training to challenging real-world data. Our experimental results show that in the cases of human keypoint detection and general object detection, state-of-the-art models trained with data distillation surpass the performance of using labeled data from the COCO dataset alone.