 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Caption-Based Queries for Video Moment Retrieval
Mar 02, 2026In this work, we investigate the degradation of existing VMR methods, particularly of DETR architectures, when trained on caption-based queries but evaluated on search queries. For this, we introduce three benchmarks by modifying the textual queries in three public VMR datasets -- i.e., HD-EPIC, YouCook2 and ActivityNet-Captions. Our analysis reveals two key generalization challenges: (i) A language gap, arising from the linguistic under-specification of search queries, and (ii) a multi-moment gap, caused by the shift from single-moment to multi-moment queries. We also identify a critical issue in these architectures -- an active decoder-query collapse -- as a primary cause of the poor generalization to multi-moment instances. We mitigate this issue with architectural modifications that effectively increase the number of active decoder queries. Extensive experiments demonstrate that our approach improves performance on search queries by up to 14.82% mAP_m, and up to 21.83% mAP_m on multi-moment search queries. The code, models and data are available in the project webpage: https://davidpujol.github.io/beyond-vmr/
Towards Egocentric 3D Hand Pose Estimation in Unseen Domains
Jan 10, 2026We present V-HPOT, a novel approach for improving the cross-domain performance of 3D hand pose estimation from egocentric images across diverse, unseen domains. State-of-the-art methods demonstrate strong performance when trained and tested within the same domain. However, they struggle to generalise to new environments due to limited training data and depth perception -- overfitting to specific camera intrinsics. Our method addresses this by estimating keypoint z-coordinates in a virtual camera space, normalised by focal length and image size, enabling camera-agnostic depth prediction. We further leverage this invariance to camera intrinsics to propose a self-supervised test-time optimisation strategy that refines the model's depth perception during inference. This is achieved by applying a 3D consistency loss between predicted and in-space scale-transformed hand poses, allowing the model to adapt to target domain characteristics without requiring ground truth annotations. V-HPOT significantly improves 3D hand pose estimation performance in cross-domain scenarios, achieving a 71% reduction in mean pose error on the H2O dataset and a 41% reduction on the AssemblyHands dataset. Compared to state-of-the-art methods, V-HPOT outperforms all single-stage approaches across all datasets and competes closely with two-stage methods, despite needing approximately x3.5 to x14 less data.
From Detection to Anticipation: Online Understanding of Struggles across Various Tasks and Activities
Dec 10, 2025



Understanding human skill performance is essential for intelligent assistive systems, with struggle recognition offering a natural cue for identifying user difficulties. While prior work focuses on offline struggle classification and localization, real-time applications require models capable of detecting and anticipating struggle online. We reformulate struggle localization as an online detection task and further extend it to anticipation, predicting struggle moments before they occur. We adapt two off-the-shelf models as baselines for online struggle detection and anticipation. Online struggle detection achieves 70-80% per-frame mAP, while struggle anticipation up to 2 seconds ahead yields comparable performance with slight drops. We further examine generalization across tasks and activities and analyse the impact of skill evolution. Despite larger domain gaps in activity-level generalization, models still outperform random baselines by 4-20%. Our feature-based models run at up to 143 FPS, and the whole pipeline, including feature extraction, operates at around 20 FPS, sufficient for real-time assistive applications.
EvoStruggle: A Dataset Capturing the Evolution of Struggle across Activities and Skill Levels
Oct 01, 2025The ability to determine when a person struggles during skill acquisition is crucial for both optimizing human learning and enabling the development of effective assistive systems. As skills develop, the type and frequency of struggles tend to change, and understanding this evolution is key to determining the user's current stage of learning. However, existing manipulation datasets have not focused on how struggle evolves over time. In this work, we collect a dataset for struggle determination, featuring 61.68 hours of video recordings, 2,793 videos, and 5,385 annotated temporal struggle segments collected from 76 participants. The dataset includes 18 tasks grouped into four diverse activities -- tying knots, origami, tangram puzzles, and shuffling cards, representing different task variations. In addition, participants repeated the same task five times to capture their evolution of skill. We define the struggle determination problem as a temporal action localization task, focusing on identifying and precisely localizing struggle segments with start and end times. Experimental results show that Temporal Action Localization models can successfully learn to detect struggle cues, even when evaluated on unseen tasks or activities. The models attain an overall average mAP of 34.56% when generalizing across tasks and 19.24% across activities, indicating that struggle is a transferable concept across various skill-based tasks while still posing challenges for further improvement in struggle detection. Our dataset is available at https://github.com/FELIXFENG2019/EvoStruggle.
Evaluating Compositional Generalisation in VLMs and Diffusion Models
Aug 28, 2025



A fundamental aspect of the semantics of natural language is that novel meanings can be formed from the composition of previously known parts. Vision-language models (VLMs) have made significant progress in recent years, however, there is evidence that they are unable to perform this kind of composition. For example, given an image of a red cube and a blue cylinder, a VLM such as CLIP is likely to incorrectly label the image as a red cylinder or a blue cube, indicating it represents the image as a `bag-of-words' and fails to capture compositional semantics. Diffusion models have recently gained significant attention for their impressive generative abilities, and zero-shot classifiers based on diffusion models have been shown to perform competitively with CLIP in certain compositional tasks. In this work we explore whether the generative Diffusion Classifier has improved compositional generalisation abilities compared to discriminative models. We assess three models -- Diffusion Classifier, CLIP, and ViLT -- on their ability to bind objects with attributes and relations in both zero-shot learning (ZSL) and generalised zero-shot learning (GZSL) settings. Our results show that the Diffusion Classifier and ViLT perform well at concept binding tasks, but that all models struggle significantly with the relational GZSL task, underscoring the broader challenges VLMs face with relational reasoning. Analysis of CLIP embeddings suggests that the difficulty may stem from overly similar representations of relational concepts such as left and right. Code and dataset are available at: https://github.com/otmive/diffusion_classifier_clip
Video, How Do Your Tokens Merge?
Jun 04, 2025



Video transformer models require huge amounts of compute resources due to the spatio-temporal scaling of the input. Tackling this, recent methods have proposed to drop or merge tokens for image models, whether randomly or via learned methods. Merging tokens has many benefits: it can be plugged into any vision transformer, does not require model re-training, and it propagates information that would otherwise be dropped through the model. Before now, video token merging has not been evaluated on temporally complex datasets for video understanding. In this work, we explore training-free token merging for video to provide comprehensive experiments and find best practices across four video transformers on three datasets that exhibit coarse and fine-grained action recognition. Our results showcase the benefits of video token merging with a speedup of around $2.5$X while maintaining accuracy (avg. $-0.55\%$ for ViViT). Code available at https://github.com/sjpollard/video-how-do-your-tokens-merge.
Leveraging Auxiliary Information in Text-to-Video Retrieval: A Review
May 29, 2025



Text-to-Video (T2V) retrieval aims to identify the most relevant item from a gallery of videos based on a user's text query. Traditional methods rely solely on aligning video and text modalities to compute the similarity and retrieve relevant items. However, recent advancements emphasise incorporating auxiliary information extracted from video and text modalities to improve retrieval performance and bridge the semantic gap between these modalities. Auxiliary information can include visual attributes, such as objects; temporal and spatial context; and textual descriptions, such as speech and rephrased captions. This survey comprehensively reviews 81 research papers on Text-to-Video retrieval that utilise such auxiliary information. It provides a detailed analysis of their methodologies; highlights state-of-the-art results on benchmark datasets; and discusses available datasets and their auxiliary information. Additionally, it proposes promising directions for future research, focusing on different ways to further enhance retrieval performance using this information.
Leveraging Modality Tags for Enhanced Cross-Modal Video Retrieval
Apr 03, 2025



Video retrieval requires aligning visual content with corresponding natural language descriptions. In this paper, we introduce Modality Auxiliary Concepts for Video Retrieval (MAC-VR), a novel approach that leverages modality-specific tags -- automatically extracted from foundation models -- to enhance video retrieval. We propose to align modalities in a latent space, along with learning and aligning auxiliary latent concepts, derived from the features of a video and its corresponding caption. We introduce these auxiliary concepts to improve the alignment of visual and textual latent concepts, and so are able to distinguish concepts from one other. We conduct extensive experiments on five diverse datasets: MSR-VTT, DiDeMo, TGIF, Charades and YouCook2. The experimental results consistently demonstrate that modality-specific tags improve cross-modal alignment, outperforming current state-of-the-art methods across three datasets and performing comparably or better across the other two.
Moment of Untruth: Dealing with Negative Queries in Video Moment Retrieval
Feb 12, 2025Video Moment Retrieval is a common task to evaluate the performance of visual-language models - it involves localising start and end times of moments in videos from query sentences. The current task formulation assumes that the queried moment is present in the video, resulting in false positive moment predictions when irrelevant query sentences are provided. In this paper we propose the task of Negative-Aware Video Moment Retrieval (NA-VMR), which considers both moment retrieval accuracy and negative query rejection accuracy. We make the distinction between In-Domain and Out-of-Domain negative queries and provide new evaluation benchmarks for two popular video moment retrieval datasets: QVHighlights and Charades-STA. We analyse the ability of current SOTA video moment retrieval approaches to adapt to Negative-Aware Video Moment Retrieval and propose UniVTG-NA, an adaptation of UniVTG designed to tackle NA-VMR. UniVTG-NA achieves high negative rejection accuracy (avg. $98.4\%$) scores while retaining moment retrieval scores to within $3.87\%$ Recall@1. Dataset splits and code are available at https://github.com/keflanagan/MomentofUntruth
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025
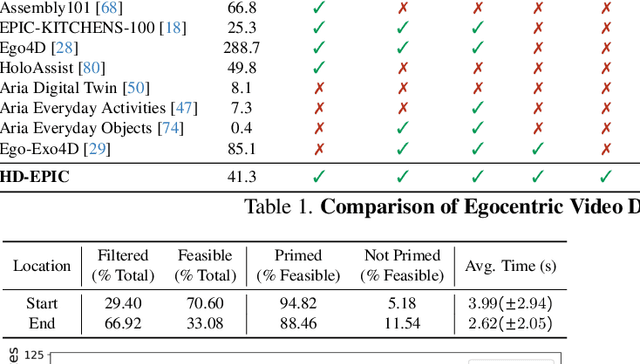


We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.