 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Cropping under Design Constraints
Oct 13, 2023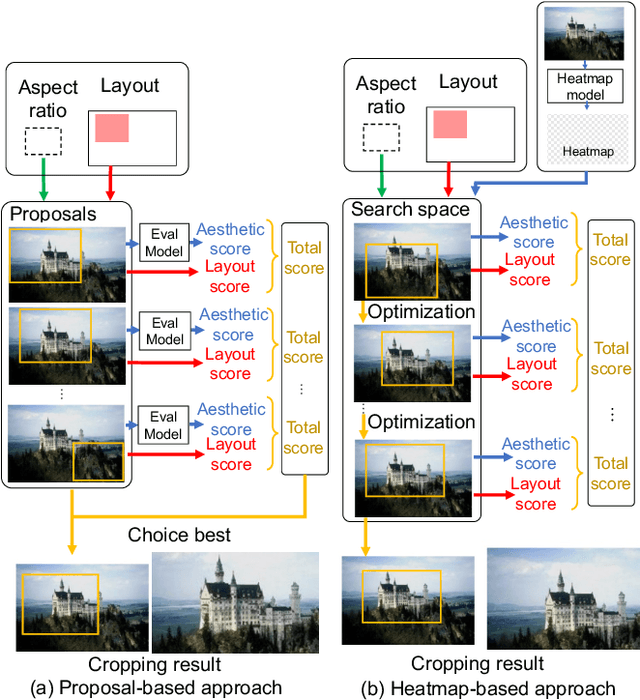
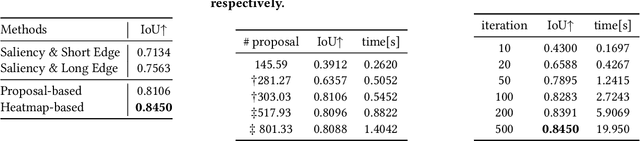

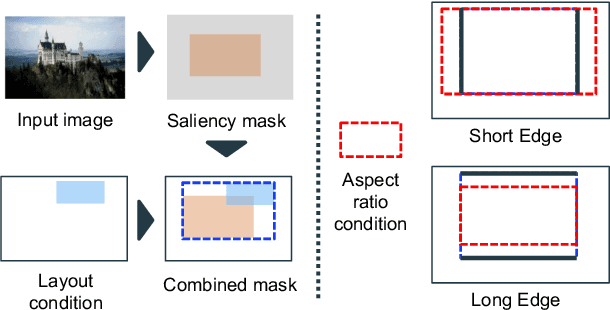
Image cropping is essential in image editing for obtaining a compositionally enhanced image. In display media, image cropping is a prospective technique for automatically creating media content. However, image cropping for media contents is often required to satisfy various constraints, such as an aspect ratio and blank regions for placing texts or objects. We call this problem image cropping under design constraints. To achieve image cropping under design constraints, we propose a score function-based approach, which computes scores for cropped results whether aesthetically plausible and satisfies design constraints. We explore two derived approaches, a proposal-based approach, and a heatmap-based approach, and we construct a dataset for evaluating the performance of the proposed approaches on image cropping under design constraints. In experiments, we demonstrate that the proposed approaches outperform a baseline, and we observe that the proposal-based approach is better than the heatmap-based approach under the same computation cost, but the heatmap-based approach leads to better scores by increasing computation cost. The experimental results indicate that balancing aesthetically plausible regions and satisfying design constraints is not a trivial problem and requires sensitive balance, and both proposed approaches are reasonable alternatives.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
GO-Finder: A Registration-Free Wearable System for Assisting Users in Finding Lost Objects via Hand-Held Object Discovery
Feb 12, 2021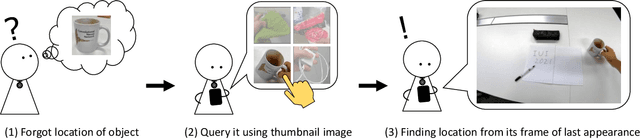
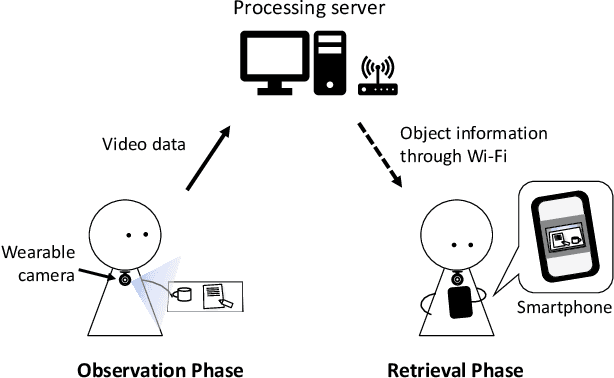
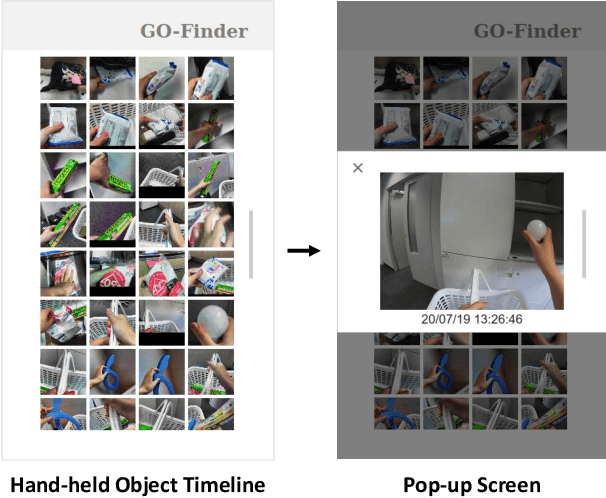
People spend an enormous amount of time and effort looking for lost objects. To help remind people of the location of lost objects, various computational systems that provide information on their locations have been developed. However, prior systems for assisting people in finding objects require users to register the target objects in advance. This requirement imposes a cumbersome burden on the users, and the system cannot help remind them of unexpectedly lost objects. We propose GO-Finder ("Generic Object Finder"), a registration-free wearable camera based system for assisting people in finding an arbitrary number of objects based on two key features: automatic discovery of hand-held objects and image-based candidate selection. Given a video taken from a wearable camera, Go-Finder automatically detects and groups hand-held objects to form a visual timeline of the objects. Users can retrieve the last appearance of the object by browsing the timeline through a smartphone app. We conducted a user study to investigate how users benefit from using GO-Finder and confirmed improved accuracy and reduced mental load regarding the object search task by providing clear visual cues on object locations.