 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
District-scale surface temperatures generated from high-resolution longitudinal thermal infrared images
May 03, 2023The paper describes a dataset that was collected by infrared thermography, which is a non-contact, non-intrusive technique to collect data and analyze the built environment in various aspects. While most studies focus on the city and building scales, the rooftop observatory provides high temporal and spatial resolution observations with dynamic interactions on the district scale. The rooftop infrared thermography observatory with a multi-modal platform that is capable of assessing a wide range of dynamic processes in urban systems was deployed in Singapore. It was placed on the top of two buildings that overlook the outdoor context of the campus of the National University of Singapore. The platform collects remote sensing data from tropical areas on a temporal scale, allowing users to determine the temperature trend of individual features such as buildings, roads, and vegetation. The dataset includes 1,365,921 thermal images collected on average at approximately 10 seconds intervals from two locations during ten months.
Longitudinal thermal imaging for scalable non-residential HVAC and occupant behaviour characterization
Nov 17, 2022This work presents a study on the characterization of the air-conditioning (AC) usage pattern of non-residential buildings from thermal images collected from an urban-scale infrared (IR) observatory. To achieve this first, an image processing scheme, for cleaning and extraction of the temperature time series from the thermal images is implemented. To test the accuracy of the thermal measurements using IR camera, the extracted temperature is compared against the ground truth surface temperature measurements. It is observed that the detrended thermal measurements match well with the ground truth surface temperature measurements. Subsequently, the operational pattern of the water-cooled systems and window AC units are extracted from the analysis of the thermal signature. It is observed that for the water-cooled system, the difference between the rate of change of the window and wall can be used to extract the operational pattern. While, in the case of the window AC units, wavelet transform of the AC unit temperature is used to extract the frequency and time domain information of the AC unit operation. The results of the analysis are compared against the indoor temperature sensors installed in the office spaces of the building. It is realized that the accuracy in the prediction of the operational pattern is highest between 8 pm to 10 am, and it reduces during the day because of solar radiation and high daytime temperature. Subsequently, a characterization study is conducted for eight window/split AC units from the thermal image collected during the nighttime. This forms one of the first studies on the operational behavior of HVAC systems for non-residential buildings using the longitudinal thermal imaging technique. The output from this study can be used to better understand the operational and occupant behavior, without requiring to deploy a large array of sensors in the building space.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Investigating sanity checks for saliency maps with image and text classification
Jun 08, 2021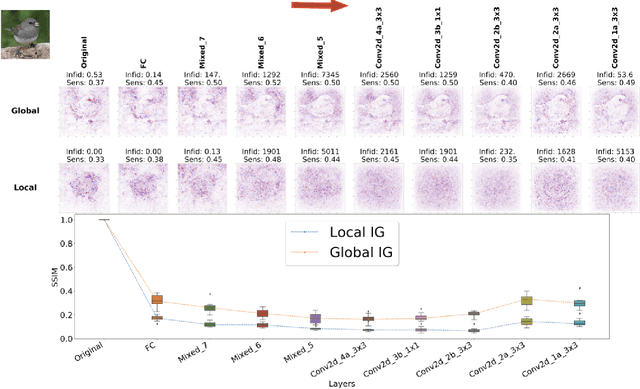
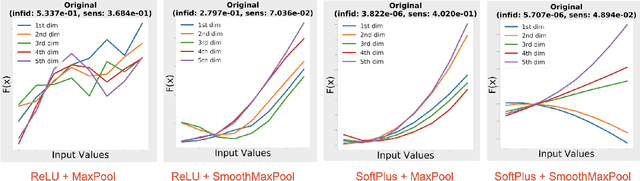
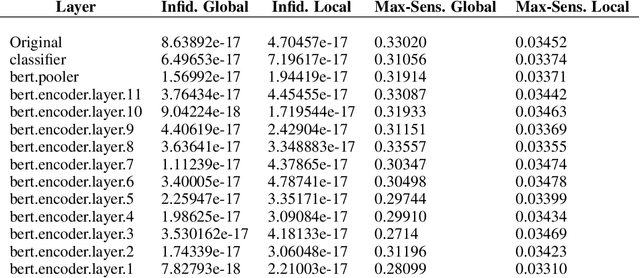
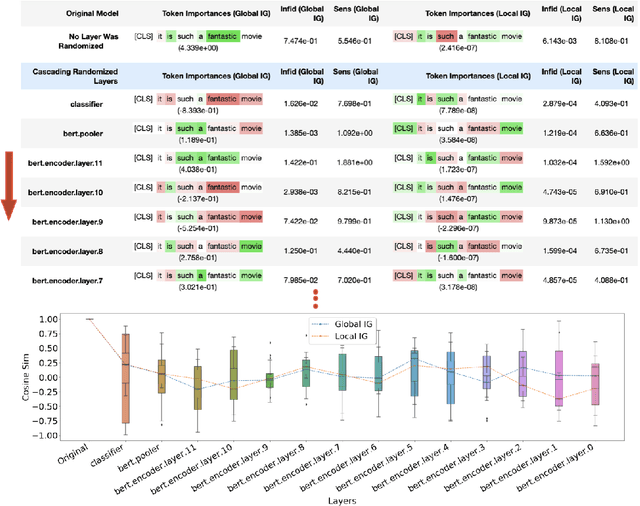
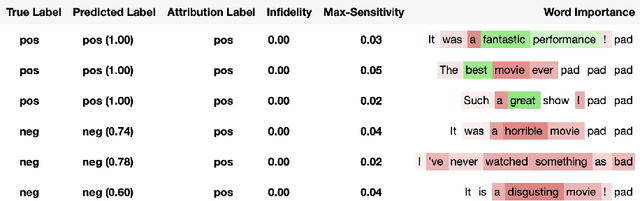
Saliency maps have shown to be both useful and misleading for explaining model predictions especially in the context of images. In this paper, we perform sanity checks for text modality and show that the conclusions made for image do not directly transfer to text. We also analyze the effects of the input multiplier in certain saliency maps using similarity scores, max-sensitivity and infidelity evaluation metrics. Our observations reveal that the input multiplier carries input's structural patterns in explanation maps, thus leading to similar results regardless of the choice of model parameters. We also show that the smoothness of a Neural Network (NN) function can affect the quality of saliency-based explanations. Our investigations reveal that replacing ReLUs with Softplus and MaxPool with smoother variants such as LogSumExp (LSE) can lead to explanations that are more reliable based on the infidelity evaluation metric.
Investigating Saturation Effects in Integrated Gradients
Oct 23, 2020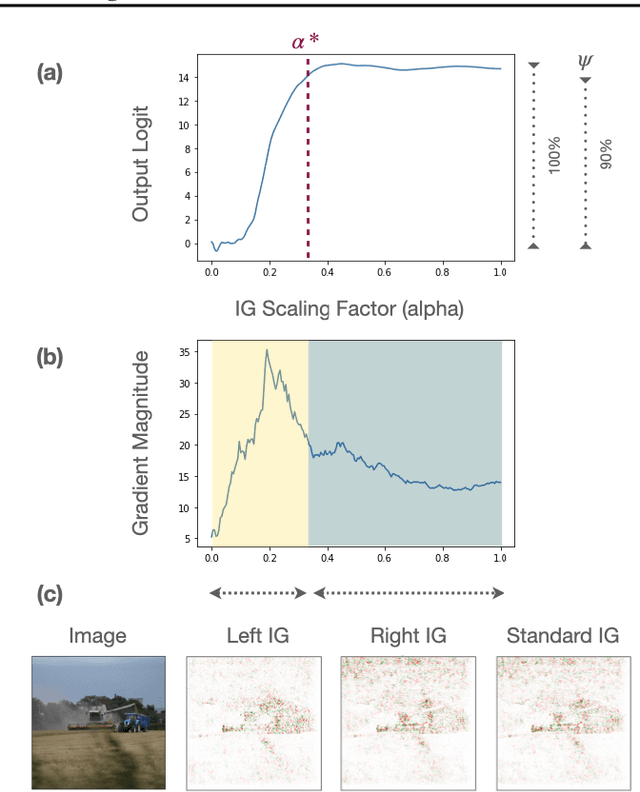
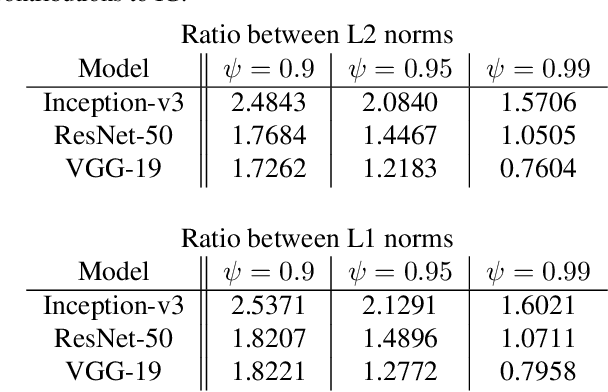

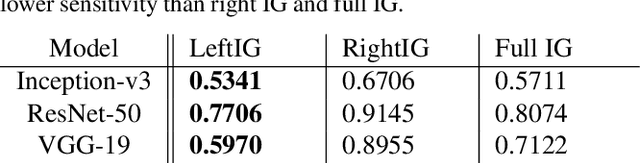
Integrated Gradients has become a popular method for post-hoc model interpretability. De-spite its popularity, the composition and relative impact of different regions of the integral path are not well understood. We explore these effects and find that gradients in saturated regions of this path, where model output changes minimally, contribute disproportionately to the computed attribution. We propose a variant of IntegratedGradients which primarily captures gradients in unsaturated regions and evaluate this method on ImageNet classification networks. We find that this attribution technique shows higher model faithfulness and lower sensitivity to noise com-pared with standard Integrated Gradients. A note-book illustrating our computations and results is available at https://github.com/vivekmig/captum-1/tree/ExpandedIG.
Captum: A unified and generic model interpretability library for PyTorch
Sep 16, 2020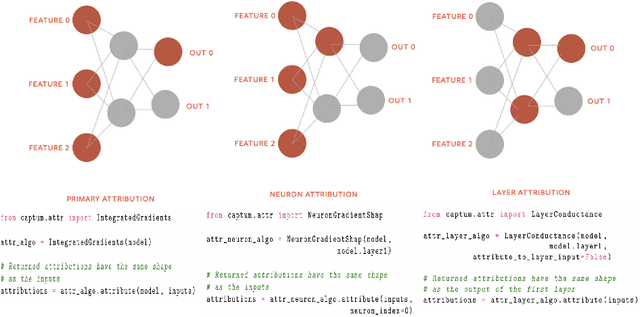

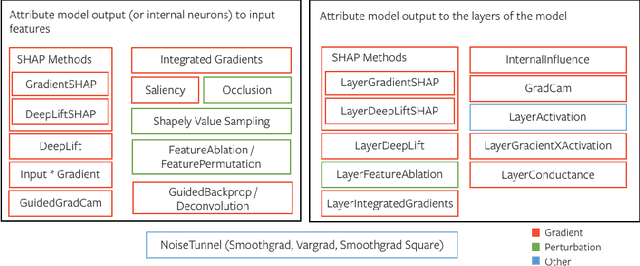
In this paper we introduce a novel, unified, open-source model interpretability library for PyTorch [12]. The library contains generic implementations of a number of gradient and perturbation-based attribution algorithms, also known as feature, neuron and layer importance algorithms, as well as a set of evaluation metrics for these algorithms. It can be used for both classification and non-classification models including graph-structured models built on Neural Networks (NN). In this paper we give a high-level overview of supported attribution algorithms and show how to perform memory-efficient and scalable computations. We emphasize that the three main characteristics of the library are multimodality, extensibility and ease of use. Multimodality supports different modality of inputs such as image, text, audio or video. Extensibility allows adding new algorithms and features. The library is also designed for easy understanding and use. Besides, we also introduce an interactive visualization tool called Captum Insights that is built on top of Captum library and allows sample-based model debugging and visualization using feature importance metrics.