 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Localization and Affordance Prediction for Tasks in Egocentric Video
Jul 18, 2024



Vision-Language Models (VLMs) have shown great success as foundational models for downstream vision and natural language applications in a variety of domains. However, these models lack the spatial understanding necessary for robotics applications where the agent must reason about the affordances provided by the 3D world around them. We present a system which trains on spatially-localized egocentric videos in order to connect visual input and task descriptions to predict a task's spatial affordance, that is the location where a person would go to accomplish the task. We show our approach outperforms the baseline of using a VLM to map similarity of a task's description over a set of location-tagged images. Our learning-based approach has less error both on predicting where a task may take place and on predicting what tasks are likely to happen at the current location. The resulting system enables robots to use egocentric sensing to navigate to physical locations of novel tasks specified in natural language.
One2Avatar: Generative Implicit Head Avatar For Few-shot User Adaptation
Feb 19, 2024



Traditional methods for constructing high-quality, personalized head avatars from monocular videos demand extensive face captures and training time, posing a significant challenge for scalability. This paper introduces a novel approach to create high quality head avatar utilizing only a single or a few images per user. We learn a generative model for 3D animatable photo-realistic head avatar from a multi-view dataset of expressions from 2407 subjects, and leverage it as a prior for creating personalized avatar from few-shot images. Different from previous 3D-aware face generative models, our prior is built with a 3DMM-anchored neural radiance field backbone, which we show to be more effective for avatar creation through auto-decoding based on few-shot inputs. We also handle unstable 3DMM fitting by jointly optimizing the 3DMM fitting and camera calibration that leads to better few-shot adaptation. Our method demonstrates compelling results and outperforms existing state-of-the-art methods for few-shot avatar adaptation, paving the way for more efficient and personalized avatar creation.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Diffusion Shape Prior for Wrinkle-Accurate Cloth Registration
Nov 10, 2023



Registering clothes from 4D scans with vertex-accurate correspondence is challenging, yet important for dynamic appearance modeling and physics parameter estimation from real-world data. However, previous methods either rely on texture information, which is not always reliable, or achieve only coarse-level alignment. In this work, we present a novel approach to enabling accurate surface registration of texture-less clothes with large deformation. Our key idea is to effectively leverage a shape prior learned from pre-captured clothing using diffusion models. We also propose a multi-stage guidance scheme based on learned functional maps, which stabilizes registration for large-scale deformation even when they vary significantly from training data. Using high-fidelity real captured clothes, our experiments show that the proposed approach based on diffusion models generalizes better than surface registration with VAE or PCA-based priors, outperforming both optimization-based and learning-based non-rigid registration methods for both interpolation and extrapolation tests.
Normal-guided Garment UV Prediction for Human Re-texturing
Mar 11, 2023



Clothes undergo complex geometric deformations, which lead to appearance changes. To edit human videos in a physically plausible way, a texture map must take into account not only the garment transformation induced by the body movements and clothes fitting, but also its 3D fine-grained surface geometry. This poses, however, a new challenge of 3D reconstruction of dynamic clothes from an image or a video. In this paper, we show that it is possible to edit dressed human images and videos without 3D reconstruction. We estimate a geometry aware texture map between the garment region in an image and the texture space, a.k.a, UV map. Our UV map is designed to preserve isometry with respect to the underlying 3D surface by making use of the 3D surface normals predicted from the image. Our approach captures the underlying geometry of the garment in a self-supervised way, requiring no ground truth annotation of UV maps and can be readily extended to predict temporally coherent UV maps. We demonstrate that our method outperforms the state-of-the-art human UV map estimation approaches on both real and synthetic data.
Self-supervised Wide Baseline Visual Servoing via 3D Equivariance
Sep 12, 2022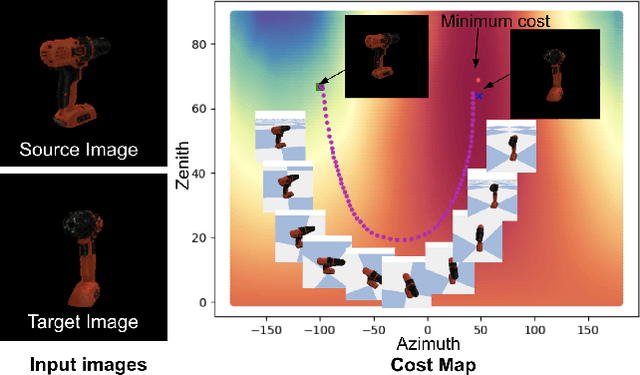
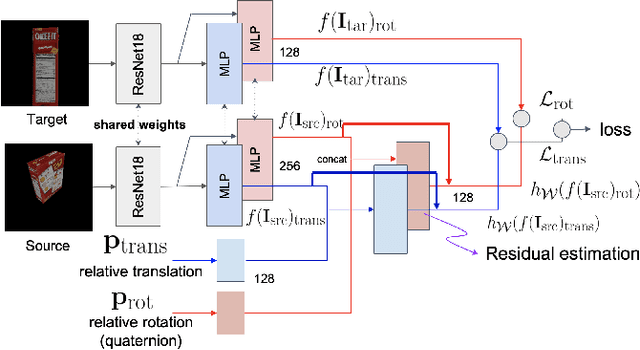
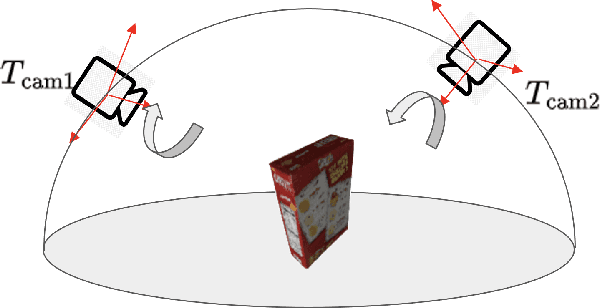

One of the challenging input settings for visual servoing is when the initial and goal camera views are far apart. Such settings are difficult because the wide baseline can cause drastic changes in object appearance and cause occlusions. This paper presents a novel self-supervised visual servoing method for wide baseline images which does not require 3D ground truth supervision. Existing approaches that regress absolute camera pose with respect to an object require 3D ground truth data of the object in the forms of 3D bounding boxes or meshes. We learn a coherent visual representation by leveraging a geometric property called 3D equivariance-the representation is transformed in a predictable way as a function of 3D transformation. To ensure that the feature-space is faithful to the underlying geodesic space, a geodesic preserving constraint is applied in conjunction with the equivariance. We design a Siamese network that can effectively enforce these two geometric properties without requiring 3D supervision. With the learned model, the relative transformation can be inferred simply by following the gradient in the learned space and used as feedback for closed-loop visual servoing. Our method is evaluated on objects from the YCB dataset, showing meaningful outperformance on a visual servoing task, or object alignment task with respect to state-of-the-art approaches that use 3D supervision. Ours yields more than 35% average distance error reduction and more than 90% success rate with 3cm error tolerance.
Egocentric Scene Understanding via Multimodal Spatial Rectifier
Jul 14, 2022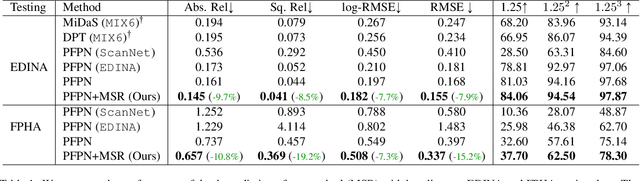
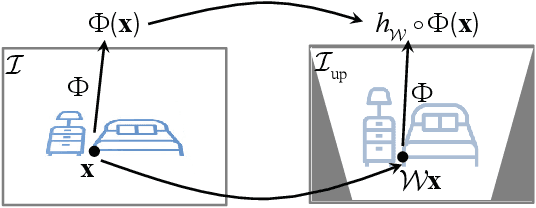
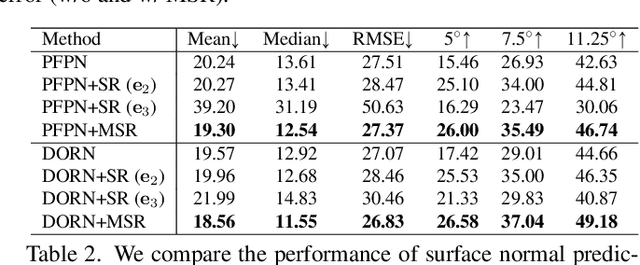

In this paper, we study a problem of egocentric scene understanding, i.e., predicting depths and surface normals from an egocentric image. Egocentric scene understanding poses unprecedented challenges: (1) due to large head movements, the images are taken from non-canonical viewpoints (i.e., tilted images) where existing models of geometry prediction do not apply; (2) dynamic foreground objects including hands constitute a large proportion of visual scenes. These challenges limit the performance of the existing models learned from large indoor datasets, such as ScanNet and NYUv2, which comprise predominantly upright images of static scenes. We present a multimodal spatial rectifier that stabilizes the egocentric images to a set of reference directions, which allows learning a coherent visual representation. Unlike unimodal spatial rectifier that often produces excessive perspective warp for egocentric images, the multimodal spatial rectifier learns from multiple directions that can minimize the impact of the perspective warp. To learn visual representations of the dynamic foreground objects, we present a new dataset called EDINA (Egocentric Depth on everyday INdoor Activities) that comprises more than 500K synchronized RGBD frames and gravity directions. Equipped with the multimodal spatial rectifier and the EDINA dataset, our proposed method on single-view depth and surface normal estimation significantly outperforms the baselines not only on our EDINA dataset, but also on other popular egocentric datasets, such as First Person Hand Action (FPHA) and EPIC-KITCHENS.
Learning Motion-Dependent Appearance for High-Fidelity Rendering of Dynamic Humans from a Single Camera
Mar 24, 2022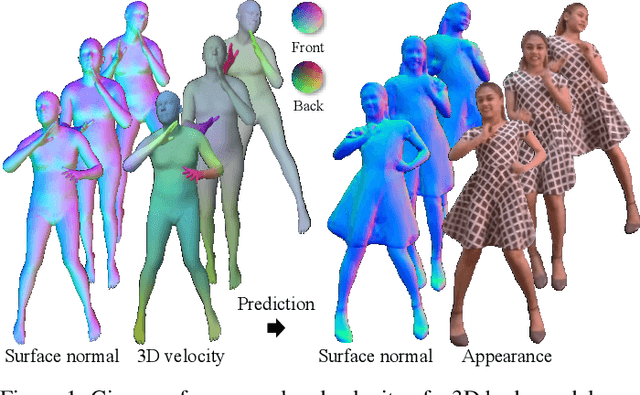

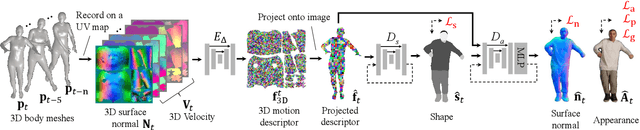

Appearance of dressed humans undergoes a complex geometric transformation induced not only by the static pose but also by its dynamics, i.e., there exists a number of cloth geometric configurations given a pose depending on the way it has moved. Such appearance modeling conditioned on motion has been largely neglected in existing human rendering methods, resulting in rendering of physically implausible motion. A key challenge of learning the dynamics of the appearance lies in the requirement of a prohibitively large amount of observations. In this paper, we present a compact motion representation by enforcing equivariance -- a representation is expected to be transformed in the way that the pose is transformed. We model an equivariant encoder that can generate the generalizable representation from the spatial and temporal derivatives of the 3D body surface. This learned representation is decoded by a compositional multi-task decoder that renders high fidelity time-varying appearance. Our experiments show that our method can generate a temporally coherent video of dynamic humans for unseen body poses and novel views given a single view video.
* CVPR accepted. 15 pages. 17 figures, 5 tables
PoseKernelLifter: Metric Lifting of 3D Human Pose using Sound
Dec 03, 2021
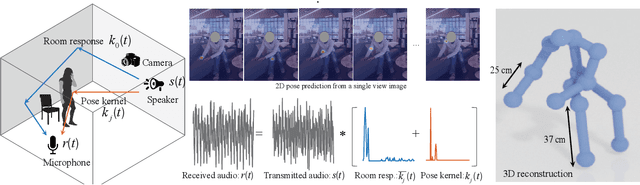
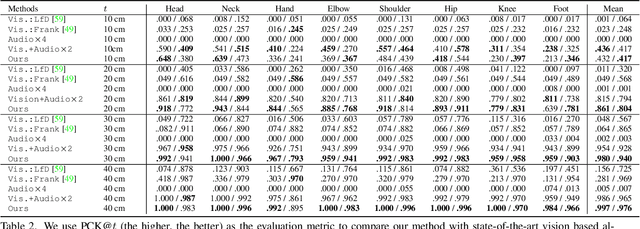
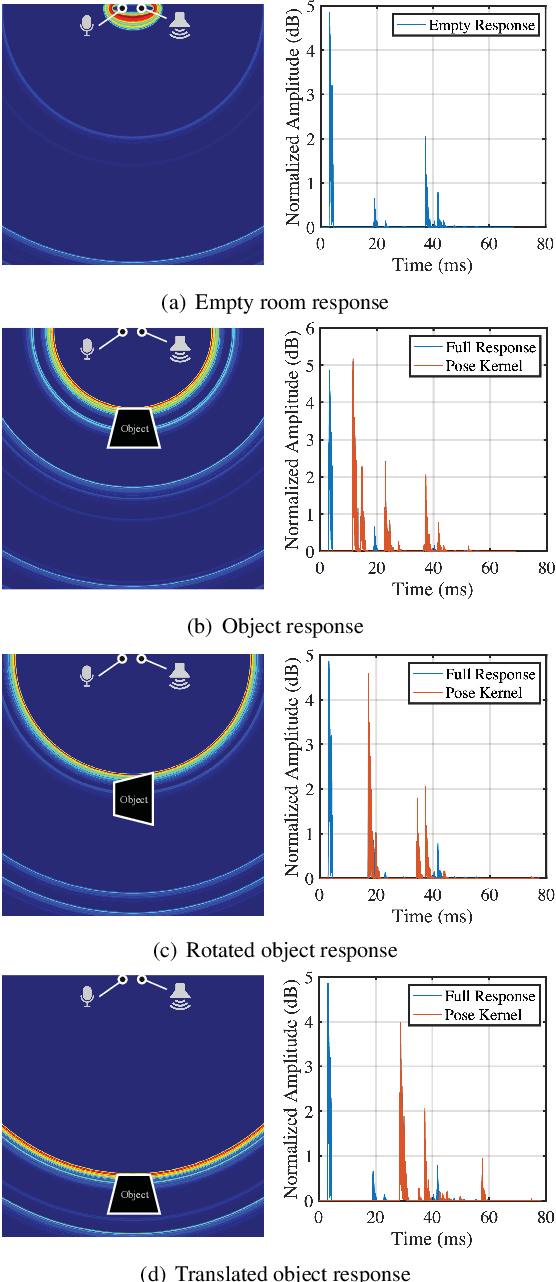
Reconstructing the 3D pose of a person in metric scale from a single view image is a geometrically ill-posed problem. For example, we can not measure the exact distance of a person to the camera from a single view image without additional scene assumptions (e.g., known height). Existing learning based approaches circumvent this issue by reconstructing the 3D pose up to scale. However, there are many applications such as virtual telepresence, robotics, and augmented reality that require metric scale reconstruction. In this paper, we show that audio signals recorded along with an image, provide complementary information to reconstruct the metric 3D pose of the person. The key insight is that as the audio signals traverse across the 3D space, their interactions with the body provide metric information about the body's pose. Based on this insight, we introduce a time-invariant transfer function called pose kernel -- the impulse response of audio signals induced by the body pose. The main properties of the pose kernel are that (1) its envelope highly correlates with 3D pose, (2) the time response corresponds to arrival time, indicating the metric distance to the microphone, and (3) it is invariant to changes in the scene geometry configurations. Therefore, it is readily generalizable to unseen scenes. We design a multi-stage 3D CNN that fuses audio and visual signals and learns to reconstruct 3D pose in a metric scale. We show that our multi-modal method produces accurate metric reconstruction in real world scenes, which is not possible with state-of-the-art lifting approaches including parametric mesh regression and depth regression.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/