 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAC-Gaze: Motion-Aware Continual Calibration for Mobile Gaze Tracking
May 28, 2025Mobile gaze tracking faces a fundamental challenge: maintaining accuracy as users naturally change their postures and device orientations. Traditional calibration approaches, like one-off, fail to adapt to these dynamic conditions, leading to degraded performance over time. We present MAC-Gaze, a Motion-Aware continual Calibration approach that leverages smartphone Inertial measurement unit (IMU) sensors and continual learning techniques to automatically detect changes in user motion states and update the gaze tracking model accordingly. Our system integrates a pre-trained visual gaze estimator and an IMU-based activity recognition model with a clustering-based hybrid decision-making mechanism that triggers recalibration when motion patterns deviate significantly from previously encountered states. To enable accumulative learning of new motion conditions while mitigating catastrophic forgetting, we employ replay-based continual learning, allowing the model to maintain performance across previously encountered motion conditions. We evaluate our system through extensive experiments on the publicly available RGBDGaze dataset and our own 10-hour multimodal MotionGaze dataset (481K+ images, 800K+ IMU readings), encompassing a wide range of postures under various motion conditions including sitting, standing, lying, and walking. Results demonstrate that our method reduces gaze estimation error by 19.9% on RGBDGaze (from 1.73 cm to 1.41 cm) and by 31.7% on MotionGaze (from 2.81 cm to 1.92 cm) compared to traditional calibration approaches. Our framework provides a robust solution for maintaining gaze estimation accuracy in mobile scenarios.
UniGaze: Towards Universal Gaze Estimation via Large-scale Pre-Training
Feb 04, 2025



Despite decades of research on data collection and model architectures, current gaze estimation models face significant challenges in generalizing across diverse data domains. While recent advances in self-supervised pre-training have shown remarkable potential for improving model generalization in various vision tasks, their effectiveness in gaze estimation remains unexplored due to the geometric nature of the gaze regression task. We propose UniGaze, which leverages large-scale, in-the-wild facial datasets through self-supervised pre-training for gaze estimation. We carefully curate multiple facial datasets that capture diverse variations in identity, lighting, background, and head poses. By directly applying Masked Autoencoder (MAE) pre-training on normalized face images with a Vision Transformer (ViT) backbone, our UniGaze learns appropriate feature representations within the specific input space required by downstream gaze estimation models. Through comprehensive experiments using challenging cross-dataset evaluation and novel protocols, including leave-one-dataset-out and joint-dataset settings, we demonstrate that UniGaze significantly improves generalization across multiple data domains while minimizing reliance on costly labeled data. The source code and pre-trained models will be released upon acceptance.
Domain-Adaptive Full-Face Gaze Estimation via Novel-View-Synthesis and Feature Disentanglement
May 25, 2023



Along with the recent development of deep neural networks, appearance-based gaze estimation has succeeded considerably when training and testing within the same domain. Compared to the within-domain task, the variance of different domains makes the cross-domain performance drop severely, preventing gaze estimation deployment in real-world applications. Among all the factors, ranges of head pose and gaze are believed to play a significant role in the final performance of gaze estimation, while collecting large ranges of data is expensive. This work proposes an effective model training pipeline consisting of a training data synthesis and a gaze estimation model for unsupervised domain adaptation. The proposed data synthesis leverages the single-image 3D reconstruction to expand the range of the head poses from the source domain without requiring a 3D facial shape dataset. To bridge the inevitable gap between synthetic and real images, we further propose an unsupervised domain adaptation method suitable for synthetic full-face data. We propose a disentangling autoencoder network to separate gaze-related features and introduce background augmentation consistency loss to utilize the characteristics of the synthetic source domain. Through comprehensive experiments, we show that the model only using monocular-reconstructed synthetic training data can perform comparably to real data with a large label range. Our proposed domain adaptation approach further improves the performance on multiple target domains. The code and data will be available at \url{https://github.com/ut-vision/AdaptiveGaze}.
Rotation-Constrained Cross-View Feature Fusion for Multi-View Appearance-based Gaze Estimation
May 22, 2023



Appearance-based gaze estimation has been actively studied in recent years. However, its generalization performance for unseen head poses is still a significant limitation for existing methods. This work proposes a generalizable multi-view gaze estimation task and a cross-view feature fusion method to address this issue. In addition to paired images, our method takes the relative rotation matrix between two cameras as additional input. The proposed network learns to extract rotatable feature representation by using relative rotation as a constraint and adaptively fuses the rotatable features via stacked fusion modules. This simple yet efficient approach significantly improves generalization performance under unseen head poses without significantly increasing computational cost. The model can be trained with random combinations of cameras without fixing the positioning and can generalize to unseen camera pairs during inference. Through experiments using multiple datasets, we demonstrate the advantage of the proposed method over baseline methods, including state-of-the-art domain generalization approaches.
Learning Video-independent Eye Contact Segmentation from In-the-Wild Videos
Oct 05, 2022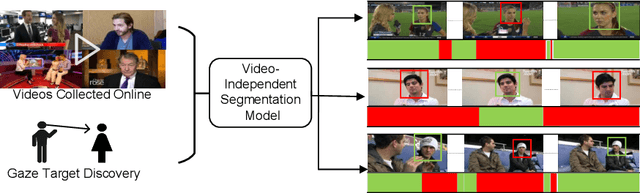

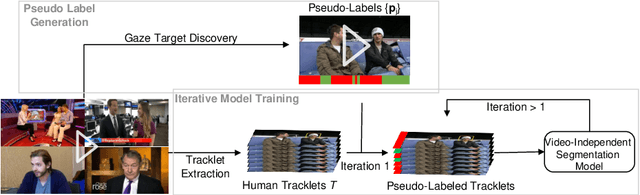
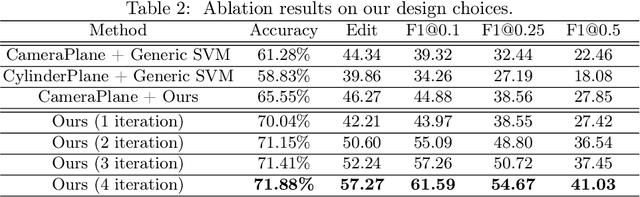
Human eye contact is a form of non-verbal communication and can have a great influence on social behavior. Since the location and size of the eye contact targets vary across different videos, learning a generic video-independent eye contact detector is still a challenging task. In this work, we address the task of one-way eye contact detection for videos in the wild. Our goal is to build a unified model that can identify when a person is looking at his gaze targets in an arbitrary input video. Considering that this requires time-series relative eye movement information, we propose to formulate the task as a temporal segmentation. Due to the scarcity of labeled training data, we further propose a gaze target discovery method to generate pseudo-labels for unlabeled videos, which allows us to train a generic eye contact segmentation model in an unsupervised way using in-the-wild videos. To evaluate our proposed approach, we manually annotated a test dataset consisting of 52 videos of human conversations. Experimental results show that our eye contact segmentation model outperforms the previous video-dependent eye contact detector and can achieve 71.88% framewise accuracy on our annotated test set. Our code and evaluation dataset are available at https://github.com/ut-vision/Video-Independent-ECS.
Learning-by-Novel-View-Synthesis for Full-Face Appearance-based 3D Gaze Estimation
Jan 23, 2022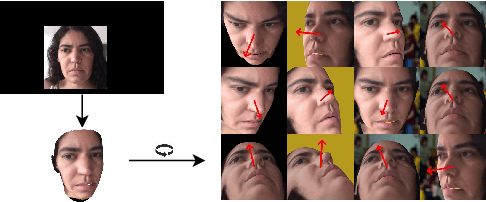
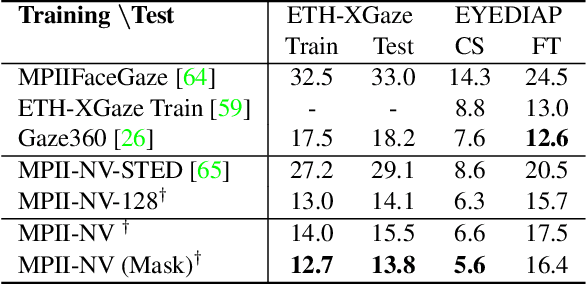

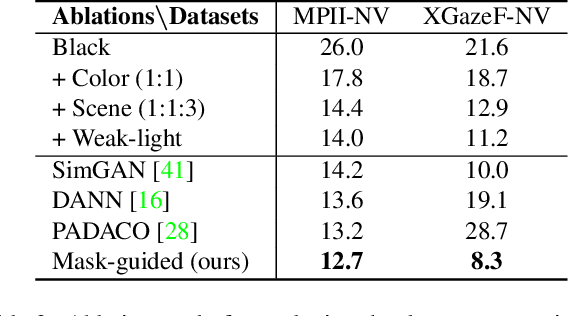
Despite recent advances in appearance-based gaze estimation techniques, the need for training data that covers the target head pose and gaze distribution remains a crucial challenge for practical deployment. This work examines a novel approach for synthesizing gaze estimation training data based on monocular 3D face reconstruction. Unlike prior works using multi-view reconstruction, photo-realistic CG models, or generative neural networks, our approach can manipulate and extend the head pose range of existing training data without any additional requirements. We introduce a projective matching procedure to align the reconstructed 3D facial mesh to the camera coordinate system and synthesize face images with accurate gaze labels. We also propose a mask-guided gaze estimation model and data augmentation strategies to further improve the estimation accuracy by taking advantage of the synthetic training data. Experiments using multiple public datasets show that our approach can significantly improve the estimation performance on challenging cross-dataset settings with non-overlapping gaze distributions.
Stacked Temporal Attention: Improving First-person Action Recognition by Emphasizing Discriminative Clips
Dec 02, 2021

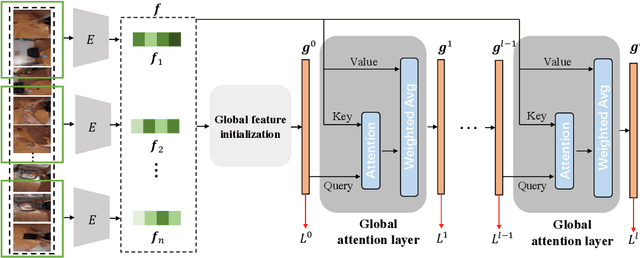
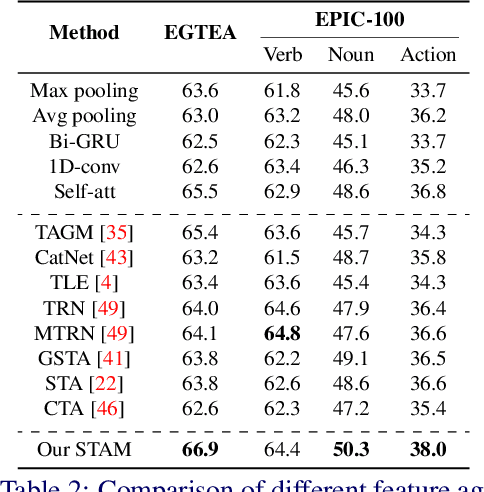
First-person action recognition is a challenging task in video understanding. Because of strong ego-motion and a limited field of view, many backgrounds or noisy frames in a first-person video can distract an action recognition model during its learning process. To encode more discriminative features, the model needs to have the ability to focus on the most relevant part of the video for action recognition. Previous works explored to address this problem by applying temporal attention but failed to consider the global context of the full video, which is critical for determining the relatively significant parts. In this work, we propose a simple yet effective Stacked Temporal Attention Module (STAM) to compute temporal attention based on the global knowledge across clips for emphasizing the most discriminative features. We achieve this by stacking multiple self-attention layers. Instead of naive stacking, which is experimentally proven to be ineffective, we carefully design the input to each self-attention layer so that both the local and global context of the video is considered during generating the temporal attention weights. Experiments demonstrate that our proposed STAM can be built on top of most existing backbones and boost the performance in various datasets.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2021: Team M3EM Technical Report
Jul 01, 2021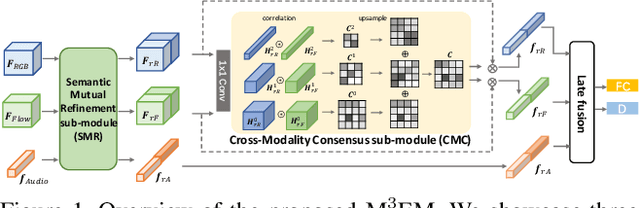

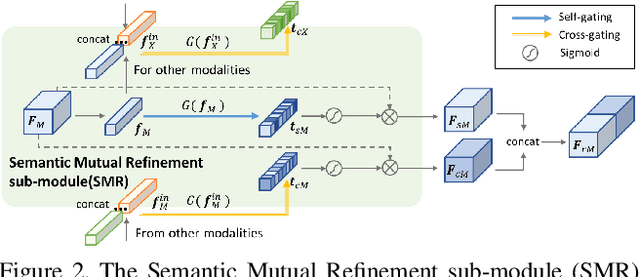
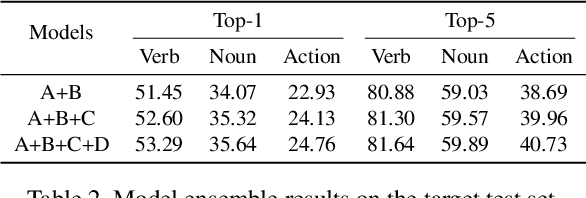
In this report, we describe the technical details of our submission to the 2021 EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition. Leveraging multiple modalities has been proved to benefit the Unsupervised Domain Adaptation (UDA) task. In this work, we present Multi-Modal Mutual Enhancement Module (M3EM), a deep module for jointly considering information from multiple modalities to find the most transferable representations across domains. We achieve this by implementing two sub-modules for enhancing each modality using the context of other modalities. The first sub-module exchanges information across modalities through the semantic space, while the second sub-module finds the most transferable spatial region based on the consensus of all modalities.
DRIV100: In-The-Wild Multi-Domain Dataset and Evaluation for Real-World Domain Adaptation of Semantic Segmentation
Feb 25, 2021


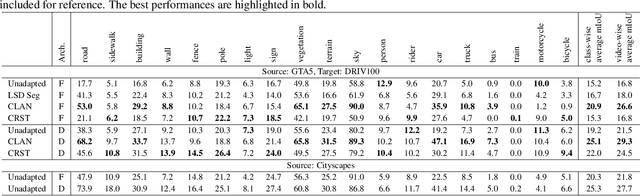
Together with the recent advances in semantic segmentation, many domain adaptation methods have been proposed to overcome the domain gap between training and deployment environments. However, most previous studies use limited combinations of source/target datasets, and domain adaptation techniques have never been thoroughly evaluated in a more challenging and diverse set of target domains. This work presents a new multi-domain dataset DRIV100 for benchmarking domain adaptation techniques on in-the-wild road-scene videos collected from the Internet. The dataset consists of pixel-level annotations for 100 videos selected to cover diverse scenes/domains based on two criteria; human subjective judgment and an anomaly score judged using an existing road-scene dataset. We provide multiple manually labeled ground-truth frames for each video, enabling a thorough evaluation of video-level domain adaptation where each video independently serves as the target domain. Using the dataset, we quantify domain adaptation performances of state-of-the-art methods and clarify the potential and novel challenges of domain adaptation techniques. The dataset is available at https://doi.org/10.5281/zenodo.4389243.