 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Byzantine-Robust Distributed Learning with Compressed Communication via Double Momentum and Variance Reduction
Mar 16, 2026In collaborative and distributed learning, Byzantine robustness reflects a major facet of optimization algorithms. Such distributed algorithms are often accompanied by transmitting a large number of parameters, so communication compression is essential for an effective solution. In this paper, we propose Byz-DM21, a novel Byzantine-robust and communication-efficient stochastic distributed learning algorithm. Our key innovation is a novel gradient estimator based on a double-momentum mechanism, integrating recent advancements in error feedback techniques. Using this estimator, we design both standard and accelerated algorithms that eliminate the need for large batch sizes while maintaining robustness against Byzantine workers. We prove that the Byz-DM21 algorithm has a smaller neighborhood size and converges to $\varepsilon$-stationary points in $\mathcal{O}(\varepsilon^{-4})$ iterations. To further enhance efficiency, we introduce a distributed variant called Byz-VR-DM21, which incorporates local variance reduction at each node to progressively eliminate variance from random approximations. We show that Byz-VR-DM21 provably converges to $\varepsilon$-stationary points in $\mathcal{O}(\varepsilon^{-3 })$ iterations. Additionally, we extend our results to the case where the functions satisfy the Polyak-Łojasiewicz condition. Finally, numerical experiments demonstrate the effectiveness of the proposed method.
Cheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
Mar 13, 2026A recent cutting-edge topic in multimodal modeling is to unify visual comprehension and generation within a single model. However, the two tasks demand mismatched decoding regimes and visual representations, making it non-trivial to jointly optimize within a shared feature space. In this work, we present Cheers, a unified multimodal model that decouples patch-level details from semantic representations, thereby stabilizing semantics for multimodal understanding and improving fidelity for image generation via gated detail residuals. Cheers includes three key components: (i) a unified vision tokenizer that encodes and compresses image latent states into semantic tokens for efficient LLM conditioning, (ii) an LLM-based Transformer that unifies autoregressive decoding for text generation and diffusion decoding for image generation, and (iii) a cascaded flow matching head that decodes visual semantics first and then injects semantically gated detail residuals from the vision tokenizer to refine high-frequency content. Experiments on popular benchmarks demonstrate that Cheers matches or surpasses advanced UMMs in both visual understanding and generation. Cheers also achieves 4x token compression, enabling more efficient high-resolution image encoding and generation. Notably, Cheers outperforms the Tar-1.5B on the popular benchmarks GenEval and MMBench, while requiring only 20% of the training cost, indicating effective and efficient (i.e., 4x token compression) unified multimodal modeling. We will release all code and data for future research.
Imagination Helps Visual Reasoning, But Not Yet in Latent Space
Feb 26, 2026Latent visual reasoning aims to mimic human's imagination process by meditating through hidden states of Multimodal Large Language Models. While recognized as a promising paradigm for visual reasoning, the underlying mechanisms driving its effectiveness remain unclear. Motivated to demystify the true source of its efficacy, we investigate the validity of latent reasoning using Causal Mediation Analysis. We model the process as a causal chain: the input as the treatment, the latent tokens as the mediator, and the final answer as the outcome. Our findings uncover two critical disconnections: (a) Input-Latent Disconnect: dramatic perturbations on the input result in negligible changes to the latent tokens, suggesting that latent tokens do not effectively attend to the input sequence. (b) Latent-Answer Disconnect: perturbations on the latent tokens yield minimal impact on the final answer, indicating the limited causal effect latent tokens imposing on the outcome. Furthermore, extensive probing analysis reveals that latent tokens encode limited visual information and exhibit high similarity. Consequently, we challenge the necessity of latent reasoning and propose a straightforward alternative named CapImagine, which teaches the model to explicitly imagine using text. Experiments on vision-centric benchmarks show that CapImagine significantly outperforms complex latent-space baselines, highlighting the superior potential of visual reasoning through explicit imagination.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
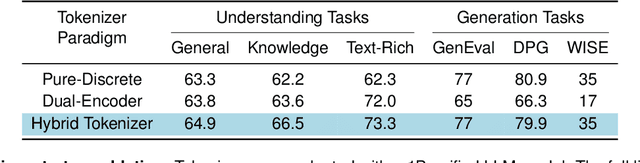
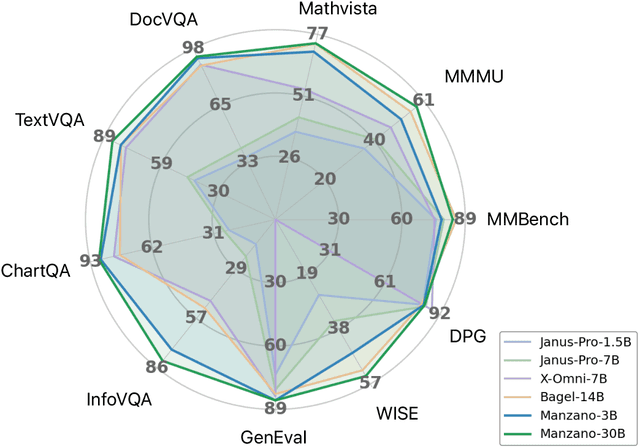
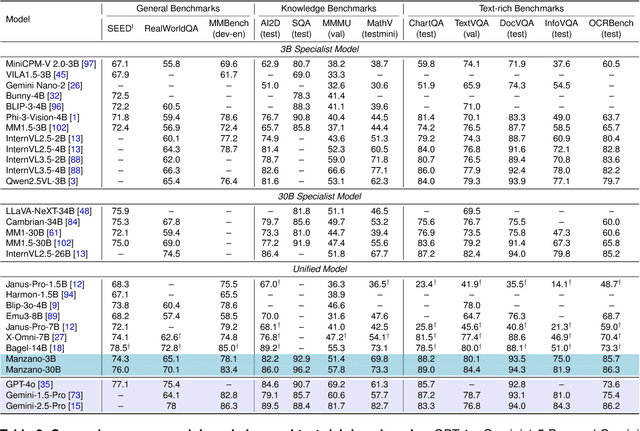
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Improve Vision Language Model Chain-of-thought Reasoning
Oct 21, 2024



Chain-of-thought (CoT) reasoning in vision language models (VLMs) is crucial for improving interpretability and trustworthiness. However, current training recipes lack robust CoT reasoning data, relying on datasets dominated by short annotations with minimal rationales. In this work, we show that training VLM on short answers does not generalize well to reasoning tasks that require more detailed responses. To address this, we propose a two-fold approach. First, we distill rationales from GPT-4o model to enrich the training data and fine-tune VLMs, boosting their CoT performance. Second, we apply reinforcement learning to further calibrate reasoning quality. Specifically, we construct positive (correct) and negative (incorrect) pairs of model-generated reasoning chains, by comparing their predictions with annotated short answers. Using this pairwise data, we apply the Direct Preference Optimization algorithm to refine the model's reasoning abilities. Our experiments demonstrate significant improvements in CoT reasoning on benchmark datasets and better generalization to direct answer prediction as well. This work emphasizes the importance of incorporating detailed rationales in training and leveraging reinforcement learning to strengthen the reasoning capabilities of VLMs.
Distance between Relevant Information Pieces Causes Bias in Long-Context LLMs
Oct 18, 2024



Positional bias in large language models (LLMs) hinders their ability to effectively process long inputs. A prominent example is the "lost in the middle" phenomenon, where LLMs struggle to utilize relevant information situated in the middle of the input. While prior research primarily focuses on single pieces of relevant information, real-world applications often involve multiple relevant information pieces. To bridge this gap, we present LongPiBench, a benchmark designed to assess positional bias involving multiple pieces of relevant information. Thorough experiments are conducted with five commercial and six open-source models. These experiments reveal that while most current models are robust against the "lost in the middle" issue, there exist significant biases related to the spacing of relevant information pieces. These findings highlight the importance of evaluating and reducing positional biases to advance LLM's capabilities.
MM-Ego: Towards Building Egocentric Multimodal LLMs
Oct 09, 2024



This research aims to comprehensively explore building a multimodal foundation model for egocentric video understanding. To achieve this goal, we work on three fronts. First, as there is a lack of QA data for egocentric video understanding, we develop a data engine that efficiently generates 7M high-quality QA samples for egocentric videos ranging from 30 seconds to one hour long, based on human-annotated data. This is currently the largest egocentric QA dataset. Second, we contribute a challenging egocentric QA benchmark with 629 videos and 7,026 questions to evaluate the models' ability in recognizing and memorizing visual details across videos of varying lengths. We introduce a new de-biasing evaluation method to help mitigate the unavoidable language bias present in the models being evaluated. Third, we propose a specialized multimodal architecture featuring a novel "Memory Pointer Prompting" mechanism. This design includes a global glimpse step to gain an overarching understanding of the entire video and identify key visual information, followed by a fallback step that utilizes the key visual information to generate responses. This enables the model to more effectively comprehend extended video content. With the data, benchmark, and model, we successfully build MM-Ego, an egocentric multimodal LLM that shows powerful performance on egocentric video understanding.
EC-DIT: Scaling Diffusion Transformers with Adaptive Expert-Choice Routing
Oct 02, 2024



Diffusion transformers have been widely adopted for text-to-image synthesis. While scaling these models up to billions of parameters shows promise, the effectiveness of scaling beyond current sizes remains underexplored and challenging. By explicitly exploiting the computational heterogeneity of image generations, we develop a new family of Mixture-of-Experts (MoE) models (EC-DIT) for diffusion transformers with expert-choice routing. EC-DIT learns to adaptively optimize the compute allocated to understand the input texts and generate the respective image patches, enabling heterogeneous computation aligned with varying text-image complexities. This heterogeneity provides an efficient way of scaling EC-DIT up to 97 billion parameters and achieving significant improvements in training convergence, text-to-image alignment, and overall generation quality over dense models and conventional MoE models. Through extensive ablations, we show that EC-DIT demonstrates superior scalability and adaptive compute allocation by recognizing varying textual importance through end-to-end training. Notably, in text-to-image alignment evaluation, our largest models achieve a state-of-the-art GenEval score of 71.68% and still maintain competitive inference speed with intuitive interpretability.
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
Sep 30, 2024



We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning. Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning. Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B). Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding. Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.