 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
Lidar Panoptic Segmentation and Tracking without Bells and Whistles
Oct 19, 2023



State-of-the-art lidar panoptic segmentation (LPS) methods follow bottom-up segmentation-centric fashion wherein they build upon semantic segmentation networks by utilizing clustering to obtain object instances. In this paper, we re-think this approach and propose a surprisingly simple yet effective detection-centric network for both LPS and tracking. Our network is modular by design and optimized for all aspects of both the panoptic segmentation and tracking task. One of the core components of our network is the object instance detection branch, which we train using point-level (modal) annotations, as available in segmentation-centric datasets. In the absence of amodal (cuboid) annotations, we regress modal centroids and object extent using trajectory-level supervision that provides information about object size, which cannot be inferred from single scans due to occlusions and the sparse nature of the lidar data. We obtain fine-grained instance segments by learning to associate lidar points with detected centroids. We evaluate our method on several 3D/4D LPS benchmarks and observe that our model establishes a new state-of-the-art among open-sourced models, outperforming recent query-based models.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
A Categorized Reflection Removal Dataset with Diverse Real-world Scenes
Aug 07, 2021


Due to the lack of a large-scale reflection removal dataset with diverse real-world scenes, many existing reflection removal methods are trained on synthetic data plus a small amount of real-world data, which makes it difficult to evaluate the strengths or weaknesses of different reflection removal methods thoroughly. Furthermore, existing real-world benchmarks and datasets do not categorize image data based on the types and appearances of reflection (e.g., smoothness, intensity), making it hard to analyze reflection removal methods. Hence, we construct a new reflection removal dataset that is categorized, diverse, and real-world (CDR). A pipeline based on RAW data is used to capture perfectly aligned input images and transmission images. The dataset is constructed using diverse glass types under various environments to ensure diversity. By analyzing several reflection removal methods and conducting extensive experiments on our dataset, we show that state-of-the-art reflection removal methods generally perform well on blurry reflection but fail in obtaining satisfying performance on other types of real-world reflection. We believe our dataset can help develop novel methods to remove real-world reflection better. Our dataset is available at https://alexzhao-hugga.github.io/Real-World-Reflection-Removal/.
Fast Video Object Segmentation With Temporal Aggregation Network and Dynamic Template Matching
Jul 11, 2020
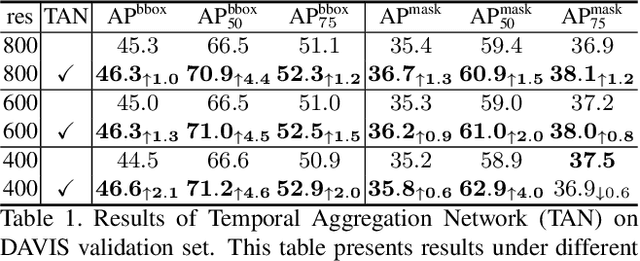
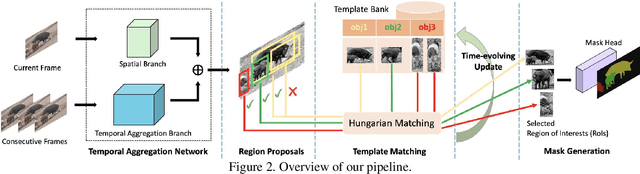
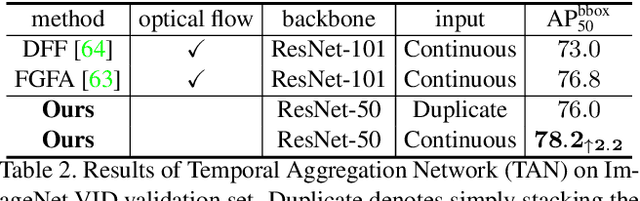
Significant progress has been made in Video Object Segmentation (VOS), the video object tracking task in its finest level. While the VOS task can be naturally decoupled into image semantic segmentation and video object tracking, significantly much more research effort has been made in segmentation than tracking. In this paper, we introduce "tracking-by-detection" into VOS which can coherently integrate segmentation into tracking, by proposing a new temporal aggregation network and a novel dynamic time-evolving template matching mechanism to achieve significantly improved performance. Notably, our method is entirely online and thus suitable for one-shot learning, and our end-to-end trainable model allows multiple object segmentation in one forward pass. We achieve new state-of-the-art performance on the DAVIS benchmark without complicated bells and whistles in both speed and accuracy, with a speed of 0.14 second per frame and J&F measure of 75.9% respectively.
Polarized Reflection Removal with Perfect Alignment in the Wild
Mar 28, 2020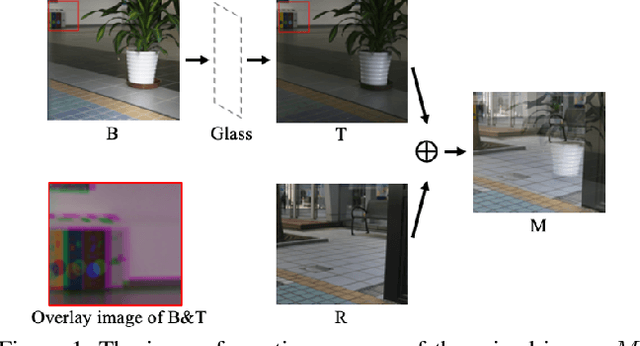

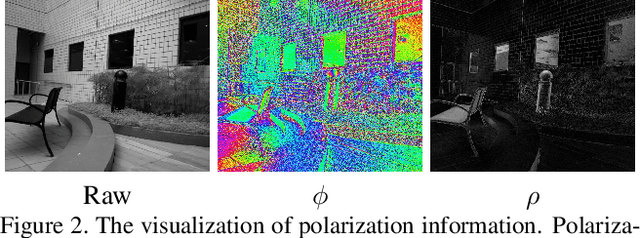
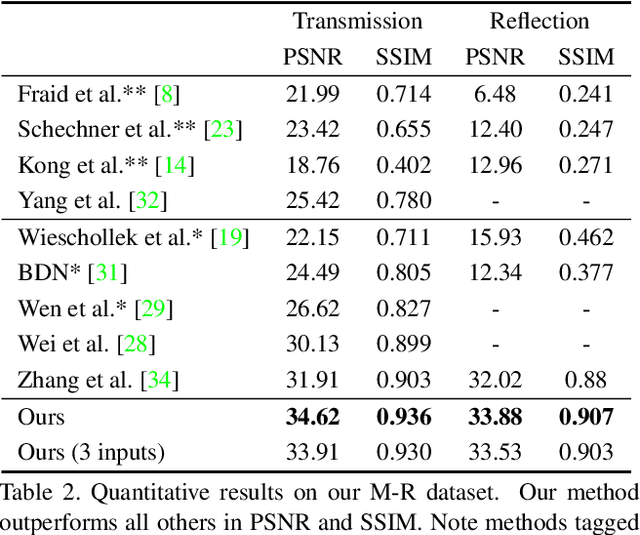
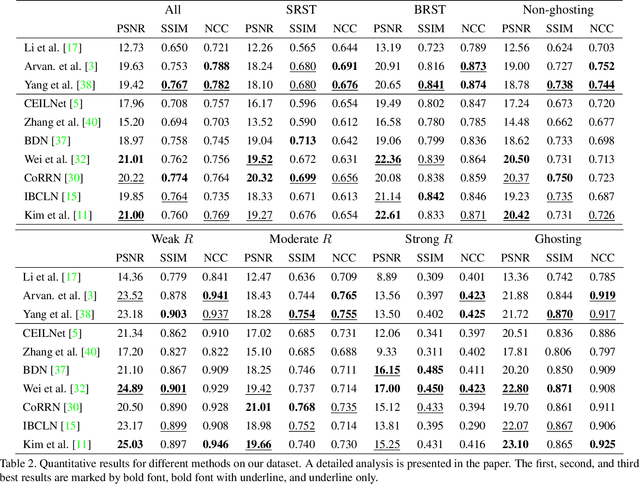
We present a novel formulation to removing reflection from polarized images in the wild. We first identify the misalignment issues of existing reflection removal datasets where the collected reflection-free images are not perfectly aligned with input mixed images due to glass refraction. Then we build a new dataset with more than 100 types of glass in which obtained transmission images are perfectly aligned with input mixed images. Second, capitalizing on the special relationship between reflection and polarized light, we propose a polarized reflection removal model with a two-stage architecture. In addition, we design a novel perceptual NCC loss that can improve the performance of reflection removal and general image decomposition tasks. We conduct extensive experiments, and results suggest that our model outperforms state-of-the-art methods on reflection removal.