 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperMemory-VQA: An Egocentric Visual Question-Answering Benchmark for Long-Horizon Memory
May 30, 2026AI glasses present a compelling platform for AI agents to serve as personalized memory assistants. To be genuinely useful, such systems must move beyond short-term video comprehension and address memory gaps that humans experience for practical, personal, or social purposes over longitudinal egocentric video streams. However, existing egocentric datasets predominantly focus on action recognition or generic QAs from short clips, measuring perceptual capabilities rather than realistic human memory needs. We introduce SuperMemory-VQA, an egocentric visual question answering (VQA) dataset for evaluating AI assistants on practical, long-horizon memory tasks. It contains 52.9 hours of everyday activities recorded with AI glasses, including synchronized RGB video, audio transcription, eye gaze, IMU, and SLAM trajectories. Through a human-verified annotation pipeline, we construct grounded 4,853 question-answer pairs that span object and location memory, intent recall, visual scene recall, timeline reconstruction, conversational memory, and in-context retrieval. Each question is posed as multiple-choice with an explicit "unanswerable" option to test hallucination robustness. Benchmarking leading agentic frameworks and LLM backbones reveals that existing systems remain far from reliable on real-world memory tasks, highlighting the need for new architectures for grounded AI memory that can answer only when evidence is sufficient. A participant survey further supports that our questions are realistic, useful, and aligned with everyday memory needs.
E$^3$C: Video Generation with 3D Environmental Memory and Ego-Exo Human Pose Control
May 25, 2026Controllable and physically grounded egocentric video generation is essential for embodied agents to reason about how their own and others' actions manifest and change the world. Compared to generic video synthesis, egocentric generation is especially challenging: the camera is tightly coupled to the actor, leading to rapid viewpoint changes and frequent self-occlusions; the underlying actions are subtle, articulated, and often only partially visible; and both the people and the scene state must evolve consistently with the specified controls. We present E$^3$C, a controllable video diffusion framework for egocentric generation that builds structured and compact conditions disentangling persistent scene structure from human-driven dynamics. From context frames, E$^3$C constructs a semi-dense point cloud-based 3D memory and augments each point with appearance descriptors from video-VAE features. Rendering this memory into target viewpoints produces conditioning aligned with the target frames. Human dynamics are modeled separately. The observed people in the scene are controlled by skeleton renderings (exo human control), while the camera wearer is specified by their 3D body joints and 6DoF wrist motion (ego human control). To preserve ego human control when the wearer's body parts are invisible, we introduce an ego motion encoder that produces persistent cross-attention tokens. Experiments on Nymeria show that E$^3$C improves visual fidelity, camera-motion accuracy, object consistency, and ego & exo human control over strong baselines, while also enabling intuitive scene editing.
EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World
Apr 08, 2026Robot learning increasingly depends on large and diverse data, yet robot data collection remains expensive and difficult to scale. Egocentric human data offer a promising alternative by capturing rich manipulation behavior across everyday environments. However, existing human datasets are often limited in scope, difficult to extend, and fragmented across institutions. We introduce EgoVerse, a collaborative platform for human data-driven robot learning that unifies data collection, processing, and access under a shared framework, enabling contributions from individual researchers, academic labs, and industry partners. The current release includes 1,362 hours (80k episodes) of human demonstrations spanning 1,965 tasks, 240 scenes, and 2,087 unique demonstrators, with standardized formats, manipulation-relevant annotations, and tooling for downstream learning. Beyond the dataset, we conduct a large-scale study of human-to-robot transfer with experiments replicated across multiple labs, tasks, and robot embodiments under shared protocols. We find that policy performance generally improves with increased human data, but that effective scaling depends on alignment between human data and robot learning objectives. Together, the dataset, platform, and study establish a foundation for reproducible progress in human data-driven robot learning. Videos and additional information can be found at https://egoverse.ai/
Boxer: Robust Lifting of Open-World 2D Bounding Boxes to 3D
Apr 06, 2026Detecting and localizing objects in space is a fundamental computer vision problem. While much progress has been made to solve 2D object detection, 3D object localization is much less explored and far from solved, especially for open-world categories. To address this research challenge, we propose Boxer, an algorithm to estimate static 3D bounding boxes (3DBBs) from 2D open-vocabulary object detections, posed images and optional depth either represented as a sparse point cloud or dense depth. At its core is BoxerNet, a transformer-based network which lifts 2D bounding box (2DBB) proposals into 3D, followed by multi-view fusion and geometric filtering to produce globally consistent de-duplicated 3DBBs in metric world space. Boxer leverages the power of existing 2DBB detection algorithms (e.g. DETIC, OWLv2, SAM3) to localize objects in 2D. This allows the main BoxerNet model to focus on lifting to 3D rather than detecting, ultimately reducing the demand for costly annotated 3DBB training data. Extending the CuTR formulation, we incorporate an aleatoric uncertainty for robust regression, a median depth patch encoding to support sparse depth inputs, and large-scale training with over 1.2 million unique 3DBBs. BoxerNet outperforms state-of-the-art baselines in open-world 3DBB lifting, including CuTR in egocentric settings without dense depth (0.532 vs. 0.010 mAP) and on CA-1M with dense depth available (0.412 vs. 0.250 mAP).
JRM: Joint Reconstruction Model for Multiple Objects without Alignment
Mar 27, 2026Object-centric reconstruction seeks to recover the 3D structure of a scene through composition of independent objects. While this independence can simplify modeling, it discards strong signals that could improve reconstruction, notably repetition where the same object model is seen multiple times in a scene, or across scans. We propose the Joint Reconstruction Model (JRM) to leverage repetition by framing object reconstruction as one of personalized generation: multiple observations share a common subject that should be consistent for all observations, while still adhering to the specific pose and state from each. Prior methods in this direction rely on explicit matching and rigid alignment across observations, making them sensitive to errors and difficult to extend to non-rigid transformations. In contrast, JRM is a 3D flow-matching generative model that implicitly aggregates unaligned observations in its latent space, learning to produce consistent and faithful reconstructions in a data-driven manner without explicit constraints. Evaluations on synthetic and real-world data show that JRM's implicit aggregation removes the need for explicit alignment, improves robustness to incorrect associations, and naturally handles non-rigid changes such as articulation. Overall, JRM outperforms both independent and alignment-based baselines in reconstruction quality.
NymeriaPlus: Enriching Nymeria Dataset with Additional Annotations and Data
Mar 19, 2026The Nymeria Dataset, released in 2024, is a large-scale collection of in-the-wild human activities captured with multiple egocentric wearable devices that are spatially localized and temporally synchronized. It provides body-motion ground truth recorded with a motion-capture suit, device trajectories, semi-dense 3D point clouds, and in-context narrations. In this paper, we upgrade Nymeria and introduce NymeriaPlus. NymeriaPlus features: (1) improved human motion in Momentum Human Rig (MHR) and SMPL formats; (2) dense 3D and 2D bounding box annotations for indoor objects and structural elements; (3) instance-level 3D object reconstructions; and (4) additional modalities e.g., basemap recordings, audio, and wristband videos. By consolidating these complementary modalities and annotations into a single, coherent benchmark, NymeriaPlus strengthens Nymeria into a more powerful in-the-wild egocentric dataset. We expect NymeriaPlus to bridge a key gap in existing egocentric resources and to support a broader range of research, including unique explorations of multimodal learning for embodied AI.
ShapeR: Robust Conditional 3D Shape Generation from Casual Captures
Jan 16, 2026Recent advances in 3D shape generation have achieved impressive results, but most existing methods rely on clean, unoccluded, and well-segmented inputs. Such conditions are rarely met in real-world scenarios. We present ShapeR, a novel approach for conditional 3D object shape generation from casually captured sequences. Given an image sequence, we leverage off-the-shelf visual-inertial SLAM, 3D detection algorithms, and vision-language models to extract, for each object, a set of sparse SLAM points, posed multi-view images, and machine-generated captions. A rectified flow transformer trained to effectively condition on these modalities then generates high-fidelity metric 3D shapes. To ensure robustness to the challenges of casually captured data, we employ a range of techniques including on-the-fly compositional augmentations, a curriculum training scheme spanning object- and scene-level datasets, and strategies to handle background clutter. Additionally, we introduce a new evaluation benchmark comprising 178 in-the-wild objects across 7 real-world scenes with geometry annotations. Experiments show that ShapeR significantly outperforms existing approaches in this challenging setting, achieving an improvement of 2.7x in Chamfer distance compared to state of the art.
ART: Articulated Reconstruction Transformer
Dec 16, 2025We introduce ART, Articulated Reconstruction Transformer -- a category-agnostic, feed-forward model that reconstructs complete 3D articulated objects from only sparse, multi-state RGB images. Previous methods for articulated object reconstruction either rely on slow optimization with fragile cross-state correspondences or use feed-forward models limited to specific object categories. In contrast, ART treats articulated objects as assemblies of rigid parts, formulating reconstruction as part-based prediction. Our newly designed transformer architecture maps sparse image inputs to a set of learnable part slots, from which ART jointly decodes unified representations for individual parts, including their 3D geometry, texture, and explicit articulation parameters. The resulting reconstructions are physically interpretable and readily exportable for simulation. Trained on a large-scale, diverse dataset with per-part supervision, and evaluated across diverse benchmarks, ART achieves significant improvements over existing baselines and establishes a new state of the art for articulated object reconstruction from image inputs.
Benchmarking Egocentric Visual-Inertial SLAM at City Scale
Sep 30, 2025Precise 6-DoF simultaneous localization and mapping (SLAM) from onboard sensors is critical for wearable devices capturing egocentric data, which exhibits specific challenges, such as a wider diversity of motions and viewpoints, prevalent dynamic visual content, or long sessions affected by time-varying sensor calibration. While recent progress on SLAM has been swift, academic research is still driven by benchmarks that do not reflect these challenges or do not offer sufficiently accurate ground truth poses. In this paper, we introduce a new dataset and benchmark for visual-inertial SLAM with egocentric, multi-modal data. We record hours and kilometers of trajectories through a city center with glasses-like devices equipped with various sensors. We leverage surveying tools to obtain control points as indirect pose annotations that are metric, centimeter-accurate, and available at city scale. This makes it possible to evaluate extreme trajectories that involve walking at night or traveling in a vehicle. We show that state-of-the-art systems developed by academia are not robust to these challenges and we identify components that are responsible for this. In addition, we design tracks with different levels of difficulty to ease in-depth analysis and evaluation of less mature approaches. The dataset and benchmark are available at https://www.lamaria.ethz.ch.
DGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025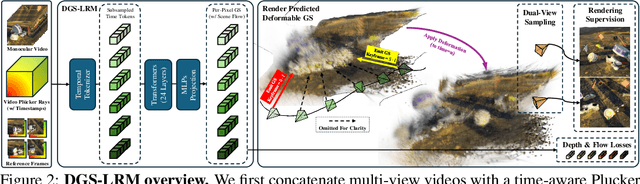
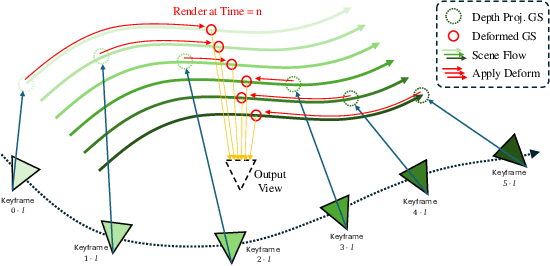
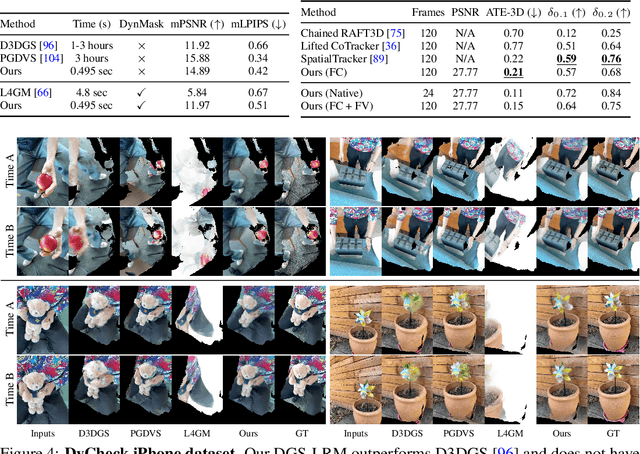

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.