 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshPose: Unifying DensePose and 3D Body Mesh reconstruction
Jun 14, 2024



DensePose provides a pixel-accurate association of images with 3D mesh coordinates, but does not provide a 3D mesh, while Human Mesh Reconstruction (HMR) systems have high 2D reprojection error, as measured by DensePose localization metrics. In this work we introduce MeshPose to jointly tackle DensePose and HMR. For this we first introduce new losses that allow us to use weak DensePose supervision to accurately localize in 2D a subset of the mesh vertices ('VertexPose'). We then lift these vertices to 3D, yielding a low-poly body mesh ('MeshPose'). Our system is trained in an end-to-end manner and is the first HMR method to attain competitive DensePose accuracy, while also being lightweight and amenable to efficient inference, making it suitable for real-time AR applications.
* IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Deformably-Scaled Transposed Convolution
Oct 17, 2022

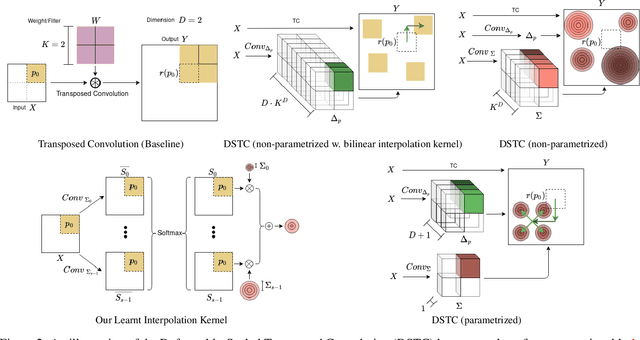
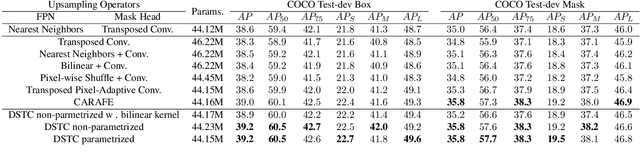
Transposed convolution is crucial for generating high-resolution outputs, yet has received little attention compared to convolution layers. In this work we revisit transposed convolution and introduce a novel layer that allows us to place information in the image selectively and choose the `stroke breadth' at which the image is synthesized, whilst incurring a small additional parameter cost. For this we introduce three ideas: firstly, we regress offsets to the positions where the transpose convolution results are placed; secondly we broadcast the offset weight locations over a learnable neighborhood; and thirdly we use a compact parametrization to share weights and restrict offsets. We show that simply substituting upsampling operators with our novel layer produces substantial improvements across tasks as diverse as instance segmentation, object detection, semantic segmentation, generative image modeling, and 3D magnetic resonance image enhancement, while outperforming all existing variants of transposed convolutions. Our novel layer can be used as a drop-in replacement for 2D and 3D upsampling operators and the code will be publicly available.
Beyond Deterministic Translation for Unsupervised Domain Adaptation
Mar 11, 2022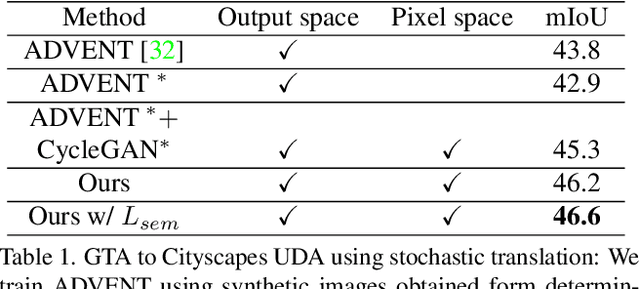


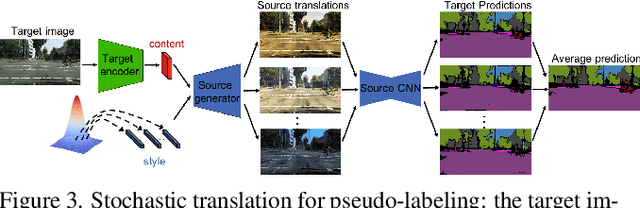
In this work we challenge the common approach of using a one-to-one mapping ('translation') between the source and target domains in unsupervised domain adaptation (UDA). Instead, we rely on stochastic translation to capture inherent translation ambiguities. This allows us to (i) train more accurate target networks by generating multiple outputs conditioned on the same source image, leveraging both accurate translation and data augmentation for appearance variability, (ii) impute robust pseudo-labels for the target data by averaging the predictions of a source network on multiple translated versions of a single target image and (iii) train and ensemble diverse networks in the target domain by modulating the degree of stochasticity in the translations. We report improvements over strong recent baselines, leading to state-of-the-art UDA results on two challenging semantic segmentation benchmarks.
Unsupervised Domain Adaptation with Semantic Consistency across Heterogeneous Modalities for MRI Prostate Lesion Segmentation
Sep 19, 2021
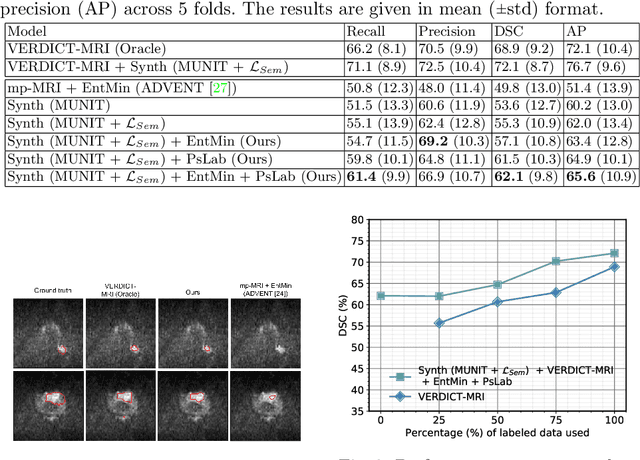
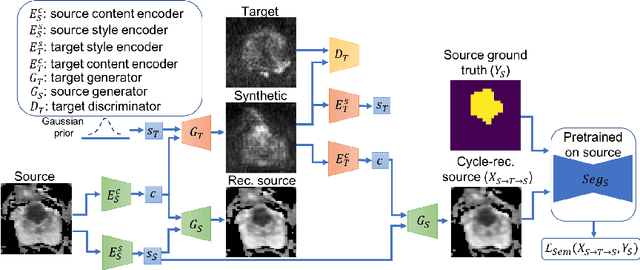

Any novel medical imaging modality that differs from previous protocols e.g. in the number of imaging channels, introduces a new domain that is heterogeneous from previous ones. This common medical imaging scenario is rarely considered in the domain adaptation literature, which handles shifts across domains of the same dimensionality. In our work we rely on stochastic generative modeling to translate across two heterogeneous domains at pixel space and introduce two new loss functions that promote semantic consistency. Firstly, we introduce a semantic cycle-consistency loss in the source domain to ensure that the translation preserves the semantics. Secondly, we introduce a pseudo-labelling loss, where we translate target data to source, label them by a source-domain network, and use the generated pseudo-labels to supervise the target-domain network. Our results show that this allows us to extract systematically better representations for the target domain. In particular, we address the challenge of enhancing performance on VERDICT-MRI, an advanced diffusion-weighted imaging technique, by exploiting labeled mp-MRI data. When compared to several unsupervised domain adaptation approaches, our approach yields substantial improvements, that consistently carry over to the semi-supervised and supervised learning settings.
To The Point: Correspondence-driven monocular 3D category reconstruction
Jun 10, 2021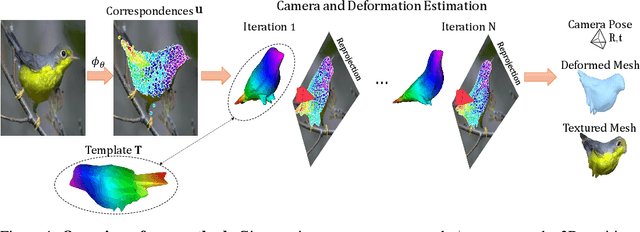
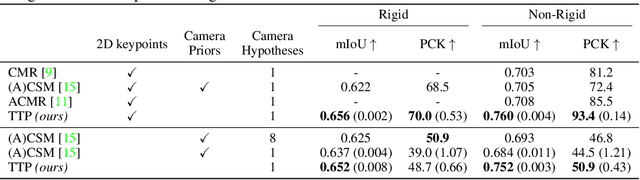
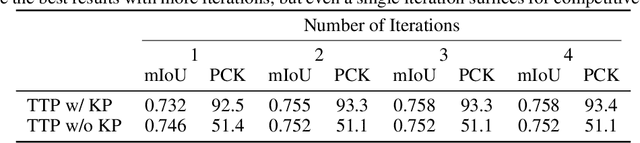
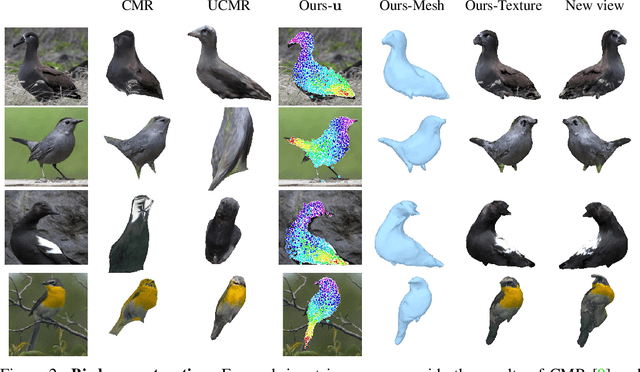
We present To The Point (TTP), a method for reconstructing 3D objects from a single image using 2D to 3D correspondences learned from weak supervision. We recover a 3D shape from a 2D image by first regressing the 2D positions corresponding to the 3D template vertices and then jointly estimating a rigid camera transform and non-rigid template deformation that optimally explain the 2D positions through the 3D shape projection. By relying on 3D-2D correspondences we use a simple per-sample optimization problem to replace CNN-based regression of camera pose and non-rigid deformation and thereby obtain substantially more accurate 3D reconstructions. We treat this optimization as a differentiable layer and train the whole system in an end-to-end manner. We report systematic quantitative improvements on multiple categories and provide qualitative results comprising diverse shape, pose and texture prediction examples. Project website: https://fkokkinos.github.io/to_the_point/.
Learning monocular 3D reconstruction of articulated categories from motion
Apr 27, 2021
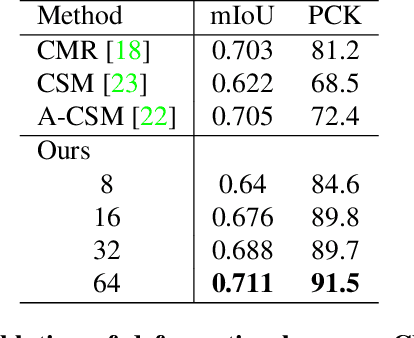
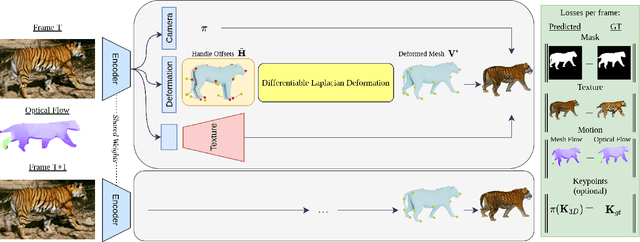
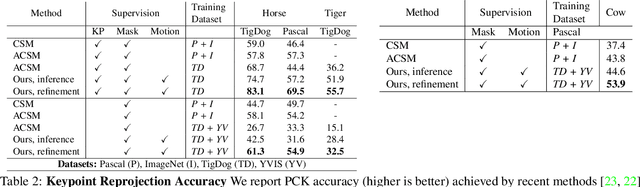
Monocular 3D reconstruction of articulated object categories is challenging due to the lack of training data and the inherent ill-posedness of the problem. In this work we use video self-supervision, forcing the consistency of consecutive 3D reconstructions by a motion-based cycle loss. This largely improves both optimization-based and learning-based 3D mesh reconstruction. We further introduce an interpretable model of 3D template deformations that controls a 3D surface through the displacement of a small number of local, learnable handles. We formulate this operation as a structured layer relying on mesh-laplacian regularization and show that it can be trained in an end-to-end manner. We finally introduce a per-sample numerical optimisation approach that jointly optimises over mesh displacements and cameras within a video, boosting accuracy both for training and also as test time post-processing. While relying exclusively on a small set of videos collected per category for supervision, we obtain state-of-the-art reconstructions with diverse shapes, viewpoints and textures for multiple articulated object categories.
Harnessing Uncertainty in Domain Adaptation for MRI Prostate Lesion Segmentation
Oct 14, 2020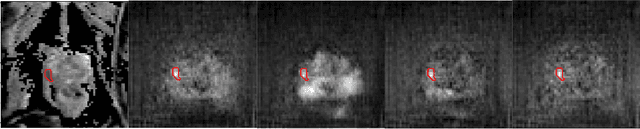
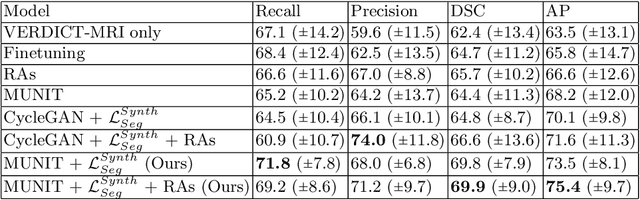
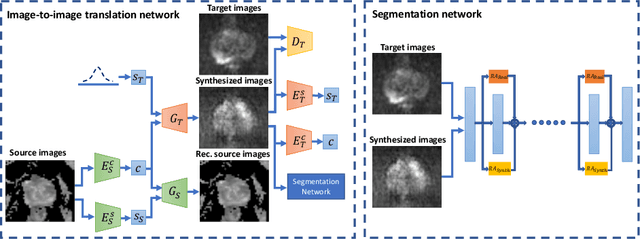
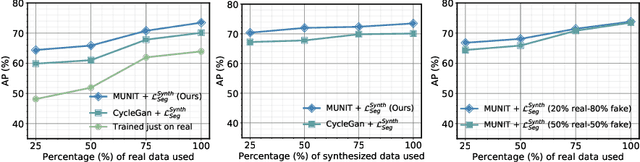
The need for training data can impede the adoption of novel imaging modalities for learning-based medical image analysis. Domain adaptation methods partially mitigate this problem by translating training data from a related source domain to a novel target domain, but typically assume that a one-to-one translation is possible. Our work addresses the challenge of adapting to a more informative target domain where multiple target samples can emerge from a single source sample. In particular we consider translating from mp-MRI to VERDICT, a richer MRI modality involving an optimized acquisition protocol for cancer characterization. We explicitly account for the inherent uncertainty of this mapping and exploit it to generate multiple outputs conditioned on a single input. Our results show that this allows us to extract systematically better image representations for the target domain, when used in tandem with both simple, CycleGAN-based baselines, as well as more powerful approaches that integrate discriminative segmentation losses and/or residual adapters. When compared to its deterministic counterparts, our approach yields substantial improvements across a broad range of dataset sizes, increasingly strong baselines, and evaluation measures.
Holistic Multi-View Building Analysis in the Wild with Projection Pooling
Sep 25, 2020
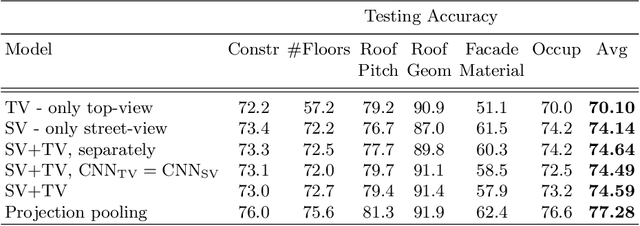
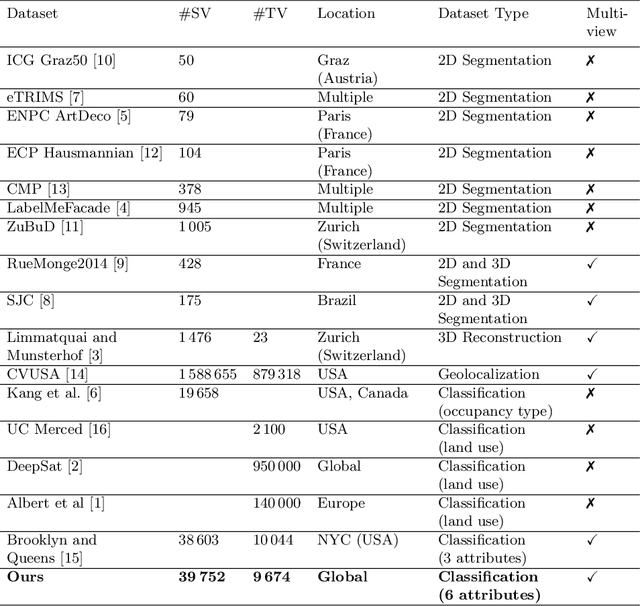
We address six different classification tasks related to fine-grained building attributes: construction type, number of floors, pitch and geometry of the roof, facade material, and occupancy class. Tackling such a problem of remote building analysis became possible only recently due to growing large scale datasets of urban scenes. To this end, we introduce a new benchmarking dataset, consisting of 49426 top-view and street-view images of 9674 buildings. These photos are further assembled, together with the geometric metadata. The dataset showcases a variety of real-world challenges, such as occlusions, blur, partially visible objects, and a broad spectrum of buildings. We propose a new projection pooling layer, creating a unified, top-view representation of the top-view and the side views in a high-dimensional space. It allows us to utilize the building and imagery metadata seamlessly. Introducing this layer improves classification accuracy - compared to highly tuned baseline models - indicating its suitability for building analysis.
Weakly-Supervised Mesh-Convolutional Hand Reconstruction in the Wild
Apr 04, 2020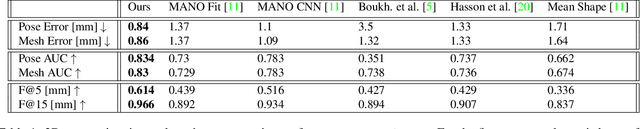
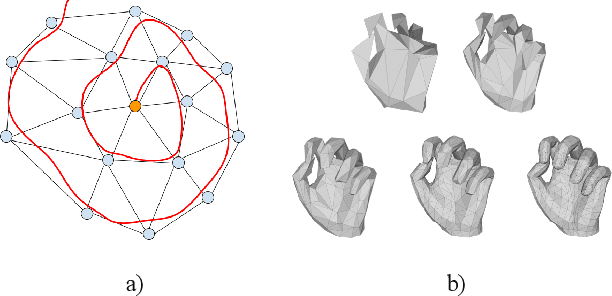
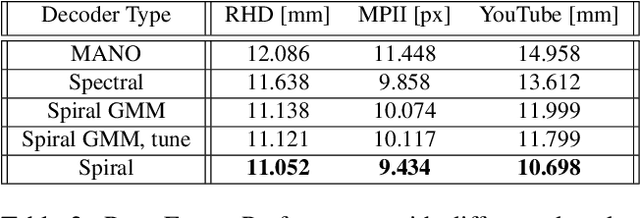

We introduce a simple and effective network architecture for monocular 3D hand pose estimation consisting of an image encoder followed by a mesh convolutional decoder that is trained through a direct 3D hand mesh reconstruction loss. We train our network by gathering a large-scale dataset of hand action in YouTube videos and use it as a source of weak supervision. Our weakly-supervised mesh convolutions-based system largely outperforms state-of-the-art methods, even halving the errors on the in the wild benchmark. The dataset and additional resources are available at https://arielai.com/mesh_hands.
Going Deeper with Point Networks
Jul 01, 2019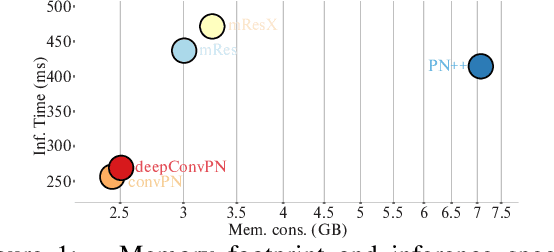

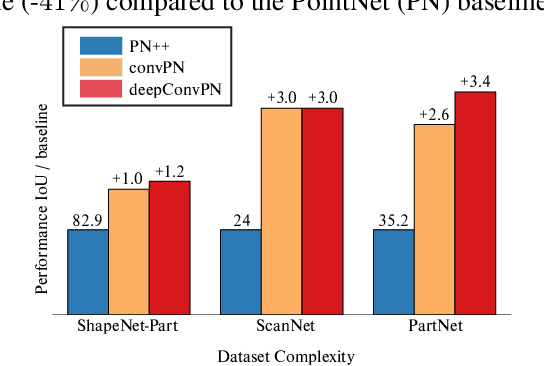
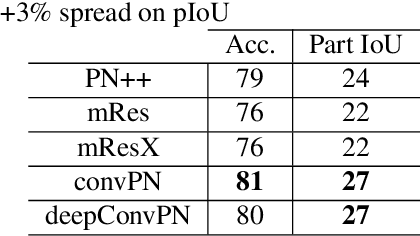
In this work, we introduce three generic point cloud processing blocks that improve both accuracy and memory consumption of state-of-the-art networks thus allowing to design deeper and more accurate networks. The novel processing blocks are: a multi-resolution point cloud processing block; a convolution-type operation for point sets that blends neighborhood information in a memory-efficient manner; and a crosslink block that efficiently shares information across low- and high-resolution processing branches. Combining these blocks allows us to design significantly wider and deeper architectures. We extensively evaluate the proposed architectures on multiple point segmentation benchmarks (ShapeNet-Part, ScanNet, PartNet) and report systematic improvements in terms of both accuracy and memory consumption by using our generic modules in conjunction with multiple recent architectures (PointNet++, DGCNN, SpiderCNN, PointCNN). We report a 3.4% increase in IoU on the -most complex- PartNet dataset while decreasing memory footprint by 57%.