 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Anything
Apr 05, 2023



We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at https://segment-anything.com to foster research into foundation models for computer vision.
PyTorchVideo: A Deep Learning Library for Video Understanding
Nov 18, 2021
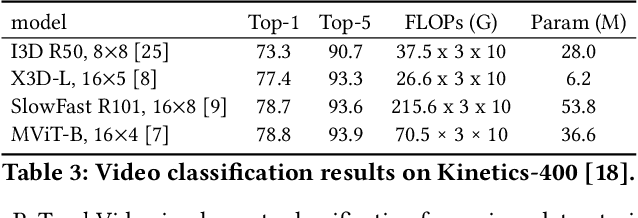

We introduce PyTorchVideo, an open-source deep-learning library that provides a rich set of modular, efficient, and reproducible components for a variety of video understanding tasks, including classification, detection, self-supervised learning, and low-level processing. The library covers a full stack of video understanding tools including multimodal data loading, transformations, and models that reproduce state-of-the-art performance. PyTorchVideo further supports hardware acceleration that enables real-time inference on mobile devices. The library is based on PyTorch and can be used by any training framework; for example, PyTorchLightning, PySlowFast, or Classy Vision. PyTorchVideo is available at https://pytorchvideo.org/
Accelerating 3D Deep Learning with PyTorch3D
Jul 16, 2020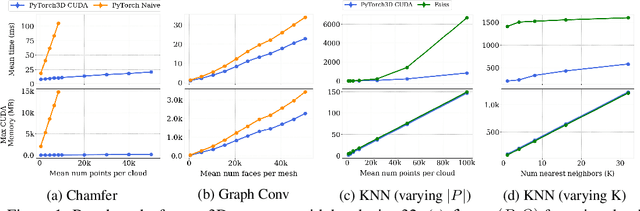
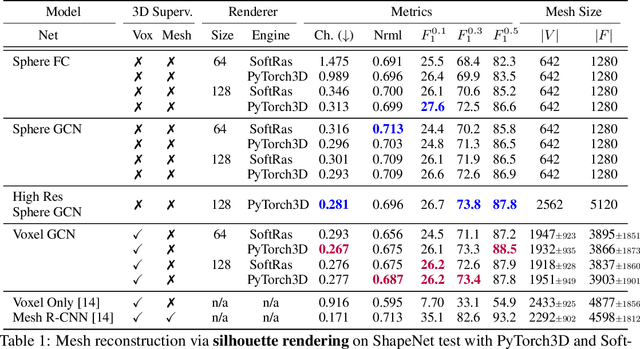
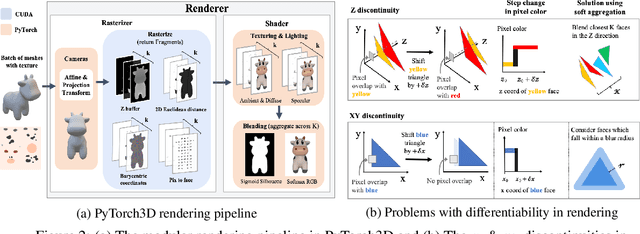
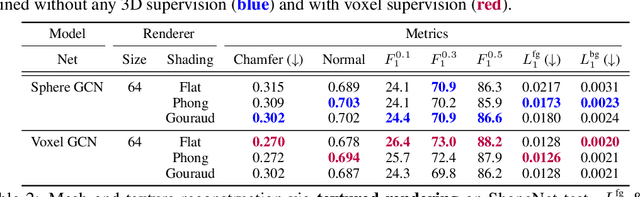
Deep learning has significantly improved 2D image recognition. Extending into 3D may advance many new applications including autonomous vehicles, virtual and augmented reality, authoring 3D content, and even improving 2D recognition. However despite growing interest, 3D deep learning remains relatively underexplored. We believe that some of this disparity is due to the engineering challenges involved in 3D deep learning, such as efficiently processing heterogeneous data and reframing graphics operations to be differentiable. We address these challenges by introducing PyTorch3D, a library of modular, efficient, and differentiable operators for 3D deep learning. It includes a fast, modular differentiable renderer for meshes and point clouds, enabling analysis-by-synthesis approaches. Compared with other differentiable renderers, PyTorch3D is more modular and efficient, allowing users to more easily extend it while also gracefully scaling to large meshes and images. We compare the PyTorch3D operators and renderer with other implementations and demonstrate significant speed and memory improvements. We also use PyTorch3D to improve the state-of-the-art for unsupervised 3D mesh and point cloud prediction from 2D images on ShapeNet. PyTorch3D is open-source and we hope it will help accelerate research in 3D deep learning.
On Network Design Spaces for Visual Recognition
May 30, 2019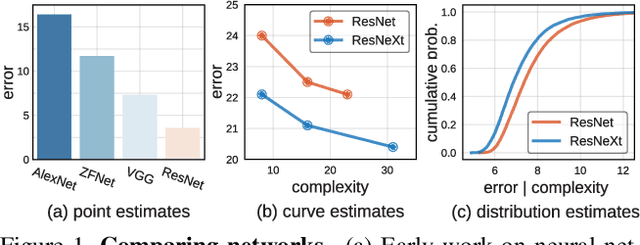

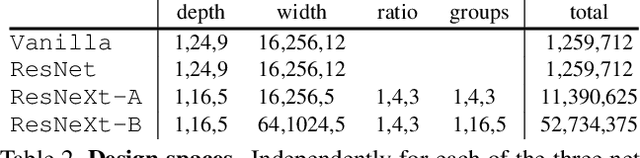
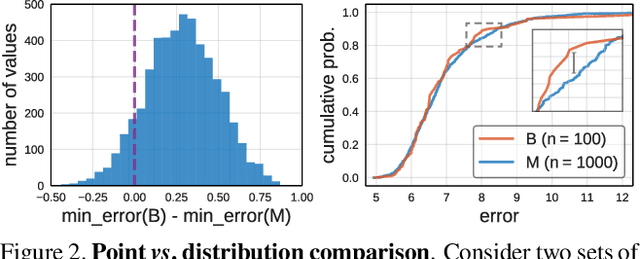
Over the past several years progress in designing better neural network architectures for visual recognition has been substantial. To help sustain this rate of progress, in this work we propose to reexamine the methodology for comparing network architectures. In particular, we introduce a new comparison paradigm of distribution estimates, in which network design spaces are compared by applying statistical techniques to populations of sampled models, while controlling for confounding factors like network complexity. Compared to current methodologies of comparing point and curve estimates of model families, distribution estimates paint a more complete picture of the entire design landscape. As a case study, we examine design spaces used in neural architecture search (NAS). We find significant statistical differences between recent NAS design space variants that have been largely overlooked. Furthermore, our analysis reveals that the design spaces for standard model families like ResNeXt can be comparable to the more complex ones used in recent NAS work. We hope these insights into distribution analysis will enable more robust progress toward discovering better networks for visual recognition.