 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIMS-V: Simulated Instruction-Tuning for Spatial Video Understanding
Nov 06, 2025Despite impressive high-level video comprehension, multimodal language models struggle with spatial reasoning across time and space. While current spatial training approaches rely on real-world video data, obtaining diverse footage with precise spatial annotations remains a bottleneck. To alleviate this bottleneck, we present SIMS-V -- a systematic data-generation framework that leverages the privileged information of 3D simulators to create spatially-rich video training data for multimodal language models. Using this framework, we investigate which properties of simulated data drive effective real-world transfer through systematic ablations of question types, mixes, and scales. We identify a minimal set of three question categories (metric measurement, perspective-dependent reasoning, and temporal tracking) that prove most effective for developing transferable spatial intelligence, outperforming comprehensive coverage despite using fewer question types. These insights enable highly efficient training: our 7B-parameter video LLM fine-tuned on just 25K simulated examples outperforms the larger 72B baseline and achieves competitive performance with proprietary models on rigorous real-world spatial reasoning benchmarks. Our approach demonstrates robust generalization, maintaining performance on general video understanding while showing substantial improvements on embodied and real-world spatial tasks.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
SAM 2: Segment Anything in Images and Videos
Aug 01, 2024



We present Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos. We build a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. Our model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 trained on our data provides strong performance across a wide range of tasks. In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM). We believe that our data, model, and insights will serve as a significant milestone for video segmentation and related perception tasks. We are releasing a version of our model, the dataset and an interactive demo.
PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators
Jun 28, 2024



We present PoliFormer (Policy Transformer), an RGB-only indoor navigation agent trained end-to-end with reinforcement learning at scale that generalizes to the real-world without adaptation despite being trained purely in simulation. PoliFormer uses a foundational vision transformer encoder with a causal transformer decoder enabling long-term memory and reasoning. It is trained for hundreds of millions of interactions across diverse environments, leveraging parallelized, multi-machine rollouts for efficient training with high throughput. PoliFormer is a masterful navigator, producing state-of-the-art results across two distinct embodiments, the LoCoBot and Stretch RE-1 robots, and four navigation benchmarks. It breaks through the plateaus of previous work, achieving an unprecedented 85.5% success rate in object goal navigation on the CHORES-S benchmark, a 28.5% absolute improvement. PoliFormer can also be trivially extended to a variety of downstream applications such as object tracking, multi-object navigation, and open-vocabulary navigation with no finetuning.
Segment Anything
Apr 05, 2023



We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at https://segment-anything.com to foster research into foundation models for computer vision.
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Mar 23, 2023



This paper revisits the standard pretrain-then-finetune paradigm used in computer vision for visual recognition tasks. Typically, state-of-the-art foundation models are pretrained using large scale (weakly) supervised datasets with billions of images. We introduce an additional pre-pretraining stage that is simple and uses the self-supervised MAE technique to initialize the model. While MAE has only been shown to scale with the size of models, we find that it scales with the size of the training dataset as well. Thus, our MAE-based pre-pretraining scales with both model and data size making it applicable for training foundation models. Pre-pretraining consistently improves both the model convergence and the downstream transfer performance across a range of model scales (millions to billions of parameters), and dataset sizes (millions to billions of images). We measure the effectiveness of pre-pretraining on 10 different visual recognition tasks spanning image classification, video recognition, object detection, low-shot classification and zero-shot recognition. Our largest model achieves new state-of-the-art results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%). Our study reveals that model initialization plays a significant role, even for web-scale pretraining with billions of images.
Exploring Plain Vision Transformer Backbones for Object Detection
Mar 30, 2022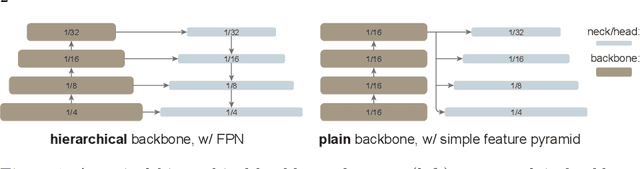



We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre-training. With minimal adaptations for fine-tuning, our plain-backbone detector can achieve competitive results. Surprisingly, we observe: (i) it is sufficient to build a simple feature pyramid from a single-scale feature map (without the common FPN design) and (ii) it is sufficient to use window attention (without shifting) aided with very few cross-window propagation blocks. With plain ViT backbones pre-trained as Masked Autoencoders (MAE), our detector, named ViTDet, can compete with the previous leading methods that were all based on hierarchical backbones, reaching up to 61.3 box AP on the COCO dataset using only ImageNet-1K pre-training. We hope our study will draw attention to research on plain-backbone detectors. Code will be made available.
Revisiting Weakly Supervised Pre-Training of Visual Perception Models
Jan 20, 2022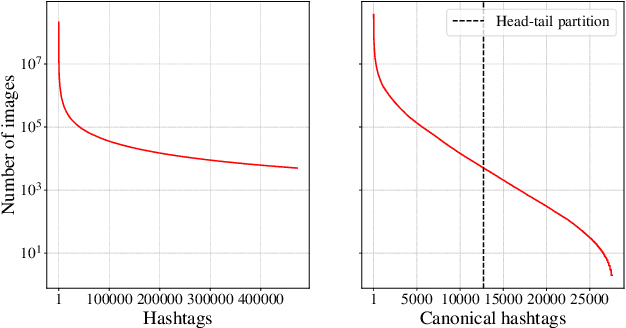
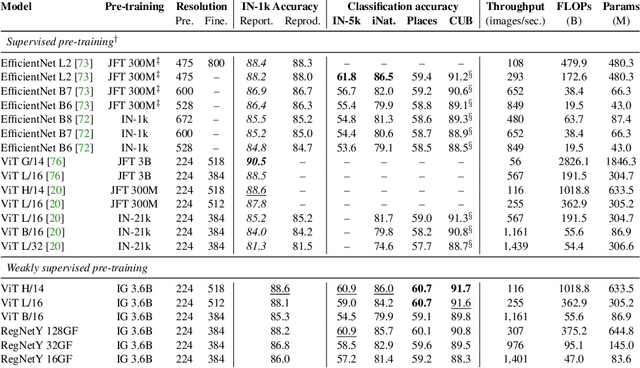
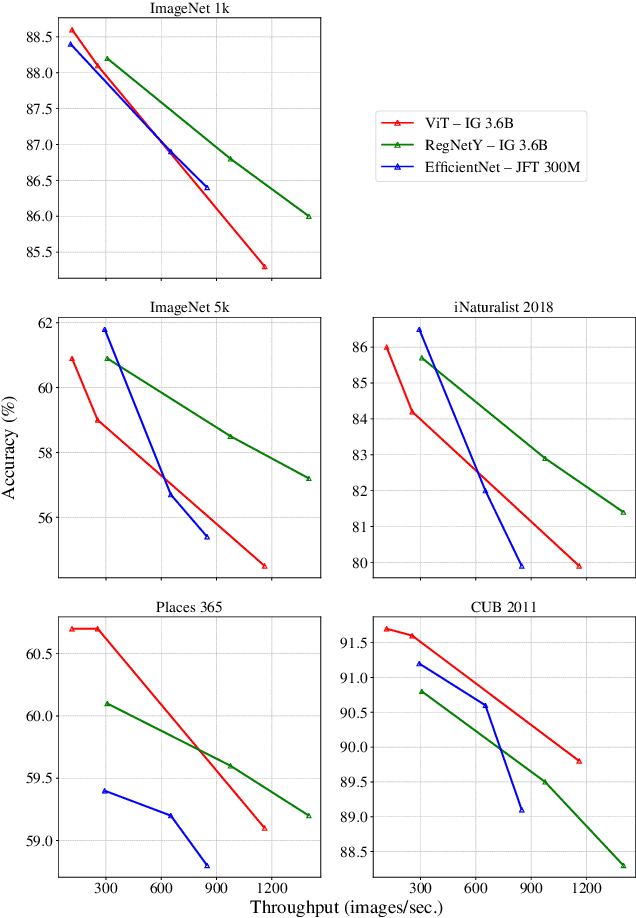
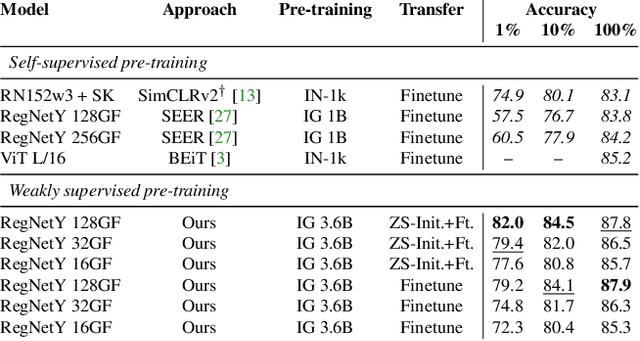
Model pre-training is a cornerstone of modern visual recognition systems. Although fully supervised pre-training on datasets like ImageNet is still the de-facto standard, recent studies suggest that large-scale weakly supervised pre-training can outperform fully supervised approaches. This paper revisits weakly-supervised pre-training of models using hashtag supervision with modern versions of residual networks and the largest-ever dataset of images and corresponding hashtags. We study the performance of the resulting models in various transfer-learning settings including zero-shot transfer. We also compare our models with those obtained via large-scale self-supervised learning. We find our weakly-supervised models to be very competitive across all settings, and find they substantially outperform their self-supervised counterparts. We also include an investigation into whether our models learned potentially troubling associations or stereotypes. Overall, our results provide a compelling argument for the use of weakly supervised learning in the development of visual recognition systems. Our models, Supervised Weakly through hashtAGs (SWAG), are available publicly.
Masked Autoencoders Are Scalable Vision Learners
Dec 02, 2021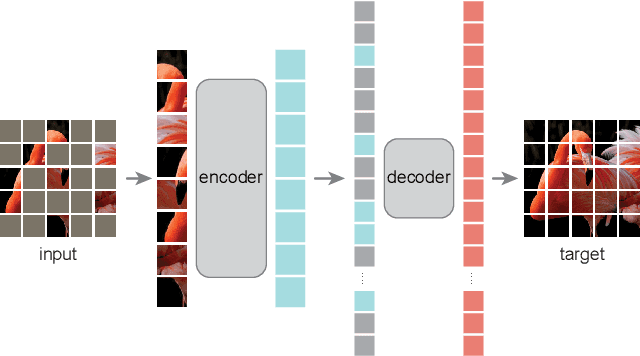
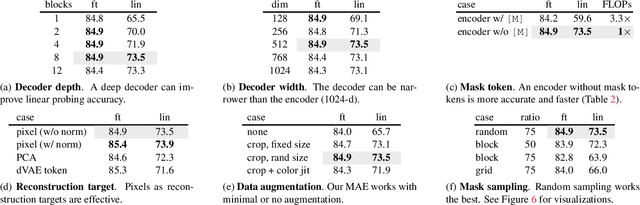

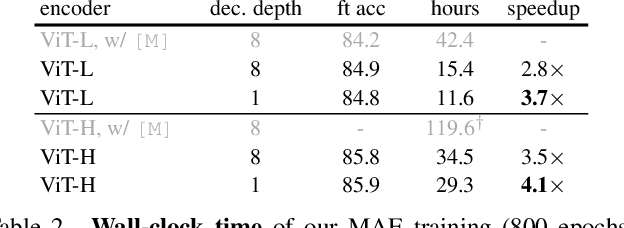
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pre-training and shows promising scaling behavior.
Benchmarking Detection Transfer Learning with Vision Transformers
Nov 22, 2021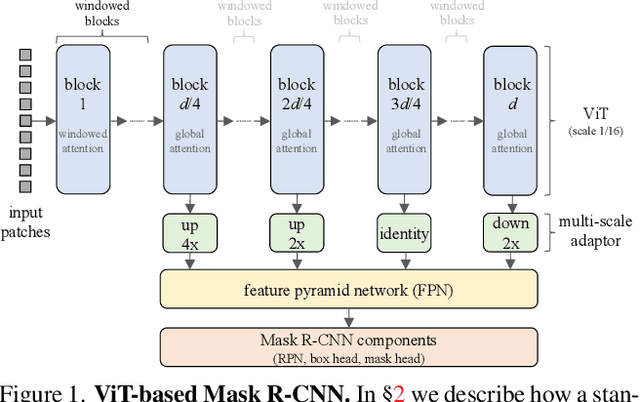
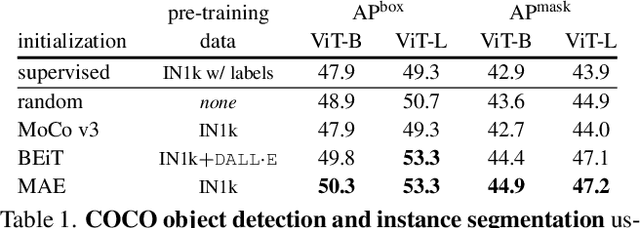
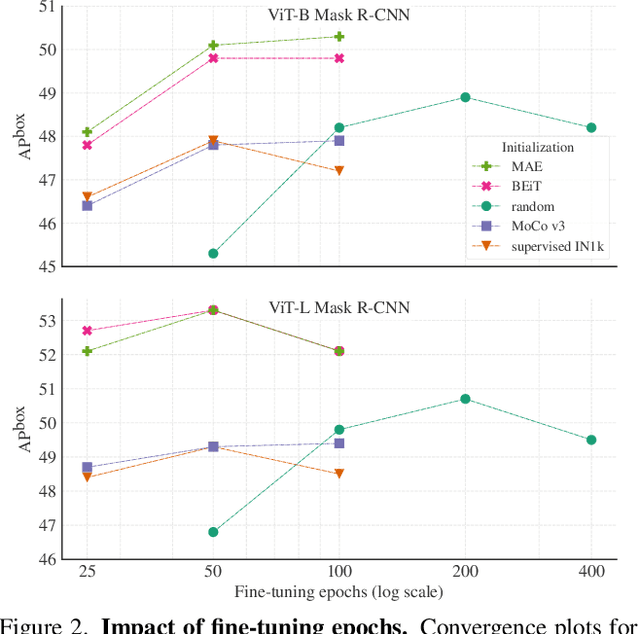

Object detection is a central downstream task used to test if pre-trained network parameters confer benefits, such as improved accuracy or training speed. The complexity of object detection methods can make this benchmarking non-trivial when new architectures, such as Vision Transformer (ViT) models, arrive. These difficulties (e.g., architectural incompatibility, slow training, high memory consumption, unknown training formulae, etc.) have prevented recent studies from benchmarking detection transfer learning with standard ViT models. In this paper, we present training techniques that overcome these challenges, enabling the use of standard ViT models as the backbone of Mask R-CNN. These tools facilitate the primary goal of our study: we compare five ViT initializations, including recent state-of-the-art self-supervised learning methods, supervised initialization, and a strong random initialization baseline. Our results show that recent masking-based unsupervised learning methods may, for the first time, provide convincing transfer learning improvements on COCO, increasing box AP up to 4% (absolute) over supervised and prior self-supervised pre-training methods. Moreover, these masking-based initializations scale better, with the improvement growing as model size increases.