 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLUX-Reason-6M & PRISM-Bench: A Million-Scale Text-to-Image Reasoning Dataset and Comprehensive Benchmark
Sep 11, 2025The advancement of open-source text-to-image (T2I) models has been hindered by the absence of large-scale, reasoning-focused datasets and comprehensive evaluation benchmarks, resulting in a performance gap compared to leading closed-source systems. To address this challenge, We introduce FLUX-Reason-6M and PRISM-Bench (Precise and Robust Image Synthesis Measurement Benchmark). FLUX-Reason-6M is a massive dataset consisting of 6 million high-quality FLUX-generated images and 20 million bilingual (English and Chinese) descriptions specifically designed to teach complex reasoning. The image are organized according to six key characteristics: Imagination, Entity, Text rendering, Style, Affection, and Composition, and design explicit Generation Chain-of-Thought (GCoT) to provide detailed breakdowns of image generation steps. The whole data curation takes 15,000 A100 GPU days, providing the community with a resource previously unattainable outside of large industrial labs. PRISM-Bench offers a novel evaluation standard with seven distinct tracks, including a formidable Long Text challenge using GCoT. Through carefully designed prompts, it utilizes advanced vision-language models for nuanced human-aligned assessment of prompt-image alignment and image aesthetics. Our extensive evaluation of 19 leading models on PRISM-Bench reveals critical performance gaps and highlights specific areas requiring improvement. Our dataset, benchmark, and evaluation code are released to catalyze the next wave of reasoning-oriented T2I generation. Project page: https://flux-reason-6m.github.io/ .
One Model for All Tasks: Leveraging Efficient World Models in Multi-Task Planning
Sep 09, 2025In heterogeneous multi-task learning, tasks not only exhibit diverse observation and action spaces but also vary substantially in intrinsic difficulty. While conventional multi-task world models like UniZero excel in single-task settings, we find that when handling large-scale heterogeneous environments, gradient conflicts and the loss of model plasticity often constrain their sample and computational efficiency. In this work, we address these challenges from two perspectives: the single learning iteration and the overall learning process. First, we investigate the impact of key design spaces on extending UniZero to multi-task planning. We find that a Mixture-of-Experts (MoE) architecture provides the most substantial performance gains by mitigating gradient conflicts, leading to our proposed model, \textit{ScaleZero}. Second, to dynamically balance the computational load across the learning process, we introduce an online, LoRA-based \textit{dynamic parameter scaling} (DPS) strategy. This strategy progressively integrates LoRA adapters in response to task-specific progress, enabling adaptive knowledge retention and parameter expansion. Empirical evaluations on standard benchmarks such as Atari, DMControl (DMC), and Jericho demonstrate that ScaleZero, relying exclusively on online reinforcement learning with one model, attains performance on par with specialized single-task baselines. Furthermore, when augmented with our dynamic parameter scaling strategy, our method achieves competitive performance while requiring only 80\% of the single-task environment interaction steps. These findings underscore the potential of ScaleZero for effective large-scale multi-task learning. Our code is available at \textcolor{magenta}{https://github.com/opendilab/LightZero}.
GLEAM: Learning to Match and Explain in Cross-View Geo-Localization
Sep 09, 2025Cross-View Geo-Localization (CVGL) focuses on identifying correspondences between images captured from distinct perspectives of the same geographical location. However, existing CVGL approaches are typically restricted to a single view or modality, and their direct visual matching strategy lacks interpretability: they merely predict whether two images correspond, without explaining the rationale behind the match. In this paper, we present GLEAM-C, a foundational CVGL model that unifies multiple views and modalities-including UAV imagery, street maps, panoramic views, and ground photographs-by aligning them exclusively with satellite imagery. Our framework enhances training efficiency through optimized implementation while achieving accuracy comparable to prior modality-specific CVGL models through a two-phase training strategy. Moreover, to address the lack of interpretability in traditional CVGL methods, we leverage the reasoning capabilities of multimodal large language models (MLLMs) to propose a new task, GLEAM-X, which combines cross-view correspondence prediction with explainable reasoning. To support this task, we construct a bilingual benchmark using GPT-4o and Doubao-1.5-Thinking-Vision-Pro to generate training and testing data. The test set is further refined through detailed human revision, enabling systematic evaluation of explainable cross-view reasoning and advancing transparency and scalability in geo-localization. Together, GLEAM-C and GLEAM-X form a comprehensive CVGL pipeline that integrates multi-modal, multi-view alignment with interpretable correspondence analysis, unifying accurate cross-view matching with explainable reasoning and advancing Geo-Localization by enabling models to better Explain And Match. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/GLEAM.
Alignment with Fill-In-the-Middle for Enhancing Code Generation
Aug 27, 2025The code generation capabilities of Large Language Models (LLMs) have advanced applications like tool invocation and problem-solving. However, improving performance in code-related tasks remains challenging due to limited training data that is verifiable with accurate test cases. While Direct Preference Optimization (DPO) has shown promise, existing methods for generating test cases still face limitations. In this paper, we propose a novel approach that splits code snippets into smaller, granular blocks, creating more diverse DPO pairs from the same test cases. Additionally, we introduce the Abstract Syntax Tree (AST) splitting and curriculum training method to enhance the DPO training. Our approach demonstrates significant improvements in code generation tasks, as validated by experiments on benchmark datasets such as HumanEval (+), MBPP (+), APPS, LiveCodeBench, and BigCodeBench. Code and data are available at https://github.com/SenseLLM/StructureCoder.
Echo-4o: Harnessing the Power of GPT-4o Synthetic Images for Improved Image Generation
Aug 13, 2025



Recently, GPT-4o has garnered significant attention for its strong performance in image generation, yet open-source models still lag behind. Several studies have explored distilling image data from GPT-4o to enhance open-source models, achieving notable progress. However, a key question remains: given that real-world image datasets already constitute a natural source of high-quality data, why should we use GPT-4o-generated synthetic data? In this work, we identify two key advantages of synthetic images. First, they can complement rare scenarios in real-world datasets, such as surreal fantasy or multi-reference image generation, which frequently occur in user queries. Second, they provide clean and controllable supervision. Real-world data often contains complex background noise and inherent misalignment between text descriptions and image content, whereas synthetic images offer pure backgrounds and long-tailed supervision signals, facilitating more accurate text-to-image alignment. Building on these insights, we introduce Echo-4o-Image, a 180K-scale synthetic dataset generated by GPT-4o, harnessing the power of synthetic image data to address blind spots in real-world coverage. Using this dataset, we fine-tune the unified multimodal generation baseline Bagel to obtain Echo-4o. In addition, we propose two new evaluation benchmarks for a more accurate and challenging assessment of image generation capabilities: GenEval++, which increases instruction complexity to mitigate score saturation, and Imagine-Bench, which focuses on evaluating both the understanding and generation of imaginative content. Echo-4o demonstrates strong performance across standard benchmarks. Moreover, applying Echo-4o-Image to other foundation models (e.g., OmniGen2, BLIP3-o) yields consistent performance gains across multiple metrics, highlighting the datasets strong transferability.
VBCD: A Voxel-Based Framework for Personalized Dental Crown Design
Jul 23, 2025



The design of restorative dental crowns from intraoral scans is labor-intensive for dental technicians. To address this challenge, we propose a novel voxel-based framework for automated dental crown design (VBCD). The VBCD framework generates an initial coarse dental crown from voxelized intraoral scans, followed by a fine-grained refiner incorporating distance-aware supervision to improve accuracy and quality. During the training stage, we employ the Curvature and Margin line Penalty Loss (CMPL) to enhance the alignment of the generated crown with the margin line. Additionally, a positional prompt based on the FDI tooth numbering system is introduced to further improve the accuracy of the generated dental crowns. Evaluation on a large-scale dataset of intraoral scans demonstrated that our approach outperforms existing methods, providing a robust solution for personalized dental crown design.
Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
Jul 23, 2025
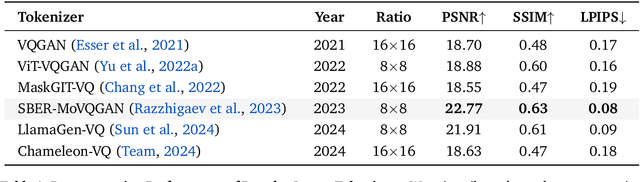
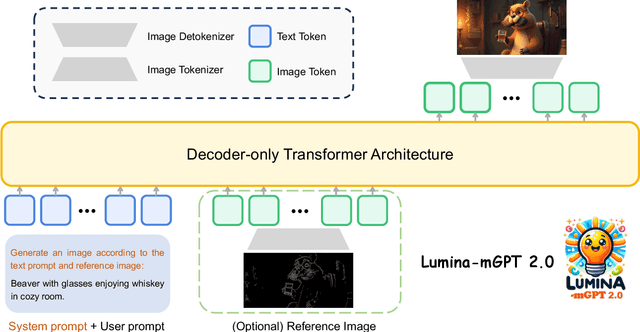

We present Lumina-mGPT 2.0, a stand-alone, decoder-only autoregressive model that revisits and revitalizes the autoregressive paradigm for high-quality image generation and beyond. Unlike existing approaches that rely on pretrained components or hybrid architectures, Lumina-mGPT 2.0 is trained entirely from scratch, enabling unrestricted architectural design and licensing freedom. It achieves generation quality on par with state-of-the-art diffusion models such as DALL-E 3 and SANA, while preserving the inherent flexibility and compositionality of autoregressive modeling. Our unified tokenization scheme allows the model to seamlessly handle a wide spectrum of tasks-including subject-driven generation, image editing, controllable synthesis, and dense prediction-within a single generative framework. To further boost usability, we incorporate efficient decoding strategies like inference-time scaling and speculative Jacobi sampling to improve quality and speed, respectively. Extensive evaluations on standard text-to-image benchmarks (e.g., GenEval, DPG) demonstrate that Lumina-mGPT 2.0 not only matches but in some cases surpasses diffusion-based models. Moreover, we confirm its multi-task capabilities on the Graph200K benchmark, with the native Lumina-mGPT 2.0 performing exceptionally well. These results position Lumina-mGPT 2.0 as a strong, flexible foundation model for unified multimodal generation. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-mGPT-2.0.
Resurrect Mask AutoRegressive Modeling for Efficient and Scalable Image Generation
Jul 17, 2025



AutoRegressive (AR) models have made notable progress in image generation, with Masked AutoRegressive (MAR) models gaining attention for their efficient parallel decoding. However, MAR models have traditionally underperformed when compared to standard AR models. This study refines the MAR architecture to improve image generation quality. We begin by evaluating various image tokenizers to identify the most effective one. Subsequently, we introduce an improved Bidirectional LLaMA architecture by replacing causal attention with bidirectional attention and incorporating 2D RoPE, which together form our advanced model, MaskGIL. Scaled from 111M to 1.4B parameters, MaskGIL achieves a FID score of 3.71, matching state-of-the-art AR models in the ImageNet 256x256 benchmark, while requiring only 8 inference steps compared to the 256 steps of AR models. Furthermore, we develop a text-driven MaskGIL model with 775M parameters for generating images from text at various resolutions. Beyond image generation, MaskGIL extends to accelerate AR-based generation and enable real-time speech-to-image conversion. Our codes and models are available at https://github.com/synbol/MaskGIL.
Perceive Anything: Recognize, Explain, Caption, and Segment Anything in Images and Videos
Jun 05, 2025



We present Perceive Anything Model (PAM), a conceptually straightforward and efficient framework for comprehensive region-level visual understanding in images and videos. Our approach extends the powerful segmentation model SAM 2 by integrating Large Language Models (LLMs), enabling simultaneous object segmentation with the generation of diverse, region-specific semantic outputs, including categories, label definition, functional explanations, and detailed captions. A key component, Semantic Perceiver, is introduced to efficiently transform SAM 2's rich visual features, which inherently carry general vision, localization, and semantic priors into multi-modal tokens for LLM comprehension. To support robust multi-granularity understanding, we also develop a dedicated data refinement and augmentation pipeline, yielding a high-quality dataset of 1.5M image and 0.6M video region-semantic annotations, including novel region-level streaming video caption data. PAM is designed for lightweightness and efficiency, while also demonstrates strong performance across a diverse range of region understanding tasks. It runs 1.2-2.4x faster and consumes less GPU memory than prior approaches, offering a practical solution for real-world applications. We believe that our effective approach will serve as a strong baseline for future research in region-level visual understanding.
MINT-CoT: Enabling Interleaved Visual Tokens in Mathematical Chain-of-Thought Reasoning
Jun 05, 2025Chain-of-Thought (CoT) has widely enhanced mathematical reasoning in Large Language Models (LLMs), but it still remains challenging for extending it to multimodal domains. Existing works either adopt a similar textual reasoning for image input, or seek to interleave visual signals into mathematical CoT. However, they face three key limitations for math problem-solving: reliance on coarse-grained box-shaped image regions, limited perception of vision encoders on math content, and dependence on external capabilities for visual modification. In this paper, we propose MINT-CoT, introducing Mathematical INterleaved Tokens for Chain-of-Thought visual reasoning. MINT-CoT adaptively interleaves relevant visual tokens into textual reasoning steps via an Interleave Token, which dynamically selects visual regions of any shapes within math figures. To empower this capability, we construct the MINT-CoT dataset, containing 54K mathematical problems aligning each reasoning step with visual regions at the token level, accompanied by a rigorous data generation pipeline. We further present a three-stage MINT-CoT training strategy, progressively combining text-only CoT SFT, interleaved CoT SFT, and interleaved CoT RL, which derives our MINT-CoT-7B model. Extensive experiments demonstrate the effectiveness of our method for effective visual interleaved reasoning in mathematical domains, where MINT-CoT-7B outperforms the baseline model by +34.08% on MathVista, +28.78% on GeoQA, and +23.2% on MMStar, respectively. Our code and data are available at https://github.com/xinyan-cxy/MINT-CoT