 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Comic Image Generation
Jun 14, 2025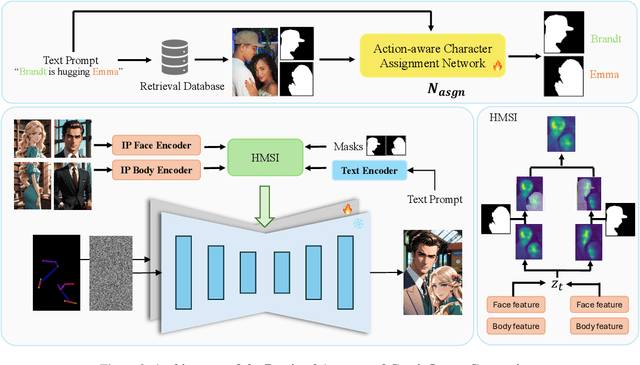



We present RaCig, a novel system for generating comic-style image sequences with consistent characters and expressive gestures. RaCig addresses two key challenges: (1) maintaining character identity and costume consistency across frames, and (2) producing diverse and vivid character gestures. Our approach integrates a retrieval-based character assignment module, which aligns characters in textual prompts with reference images, and a regional character injection mechanism that embeds character features into specified image regions. Experimental results demonstrate that RaCig effectively generates engaging comic narratives with coherent characters and dynamic interactions. The source code will be publicly available to support further research in this area.
Self-NPO: Negative Preference Optimization of Diffusion Models by Simply Learning from Itself without Explicit Preference Annotations
May 17, 2025Diffusion models have demonstrated remarkable success in various visual generation tasks, including image, video, and 3D content generation. Preference optimization (PO) is a prominent and growing area of research that aims to align these models with human preferences. While existing PO methods primarily concentrate on producing favorable outputs, they often overlook the significance of classifier-free guidance (CFG) in mitigating undesirable results. Diffusion-NPO addresses this gap by introducing negative preference optimization (NPO), training models to generate outputs opposite to human preferences and thereby steering them away from unfavorable outcomes. However, prior NPO approaches, including Diffusion-NPO, rely on costly and fragile procedures for obtaining explicit preference annotations (e.g., manual pairwise labeling or reward model training), limiting their practicality in domains where such data are scarce or difficult to acquire. In this work, we introduce Self-NPO, a Negative Preference Optimization approach that learns exclusively from the model itself, thereby eliminating the need for manual data labeling or reward model training. Moreover, our method is highly efficient and does not require exhaustive data sampling. We demonstrate that Self-NPO integrates seamlessly into widely used diffusion models, including SD1.5, SDXL, and CogVideoX, as well as models already optimized for human preferences, consistently enhancing both their generation quality and alignment with human preferences.
Diffusion-NPO: Negative Preference Optimization for Better Preference Aligned Generation of Diffusion Models
May 16, 2025Diffusion models have made substantial advances in image generation, yet models trained on large, unfiltered datasets often yield outputs misaligned with human preferences. Numerous methods have been proposed to fine-tune pre-trained diffusion models, achieving notable improvements in aligning generated outputs with human preferences. However, we argue that existing preference alignment methods neglect the critical role of handling unconditional/negative-conditional outputs, leading to a diminished capacity to avoid generating undesirable outcomes. This oversight limits the efficacy of classifier-free guidance~(CFG), which relies on the contrast between conditional generation and unconditional/negative-conditional generation to optimize output quality. In response, we propose a straightforward but versatile effective approach that involves training a model specifically attuned to negative preferences. This method does not require new training strategies or datasets but rather involves minor modifications to existing techniques. Our approach integrates seamlessly with models such as SD1.5, SDXL, video diffusion models and models that have undergone preference optimization, consistently enhancing their alignment with human preferences.
BlinkVision: A Benchmark for Optical Flow, Scene Flow and Point Tracking Estimation using RGB Frames and Events
Oct 27, 2024Recent advances in event-based vision suggest that these systems complement traditional cameras by providing continuous observation without frame rate limitations and a high dynamic range, making them well-suited for correspondence tasks such as optical flow and point tracking. However, there is still a lack of comprehensive benchmarks for correspondence tasks that include both event data and images. To address this gap, we propose BlinkVision, a large-scale and diverse benchmark with multiple modalities and dense correspondence annotations. BlinkVision offers several valuable features: 1) Rich modalities: It includes both event data and RGB images. 2) Extensive annotations: It provides dense per-pixel annotations covering optical flow, scene flow, and point tracking. 3) Large vocabulary: It contains 410 everyday categories, sharing common classes with popular 2D and 3D datasets like LVIS and ShapeNet. 4) Naturalistic: It delivers photorealistic data and covers various naturalistic factors, such as camera shake and deformation. BlinkVision enables extensive benchmarks on three types of correspondence tasks (optical flow, point tracking, and scene flow estimation) for both image-based and event-based methods, offering new observations, practices, and insights for future research. The benchmark website is https://www.blinkvision.net/.
Storynizor: Consistent Story Generation via Inter-Frame Synchronized and Shuffled ID Injection
Sep 29, 2024



Recent advances in text-to-image diffusion models have spurred significant interest in continuous story image generation. In this paper, we introduce Storynizor, a model capable of generating coherent stories with strong inter-frame character consistency, effective foreground-background separation, and diverse pose variation. The core innovation of Storynizor lies in its key modules: ID-Synchronizer and ID-Injector. The ID-Synchronizer employs an auto-mask self-attention module and a mask perceptual loss across inter-frame images to improve the consistency of character generation, vividly representing their postures and backgrounds. The ID-Injector utilize a Shuffling Reference Strategy (SRS) to integrate ID features into specific locations, enhancing ID-based consistent character generation. Additionally, to facilitate the training of Storynizor, we have curated a novel dataset called StoryDB comprising 100, 000 images. This dataset contains single and multiple-character sets in diverse environments, layouts, and gestures with detailed descriptions. Experimental results indicate that Storynizor demonstrates superior coherent story generation with high-fidelity character consistency, flexible postures, and vivid backgrounds compared to other character-specific methods.
GenCA: A Text-conditioned Generative Model for Realistic and Drivable Codec Avatars
Aug 24, 2024



Photo-realistic and controllable 3D avatars are crucial for various applications such as virtual and mixed reality (VR/MR), telepresence, gaming, and film production. Traditional methods for avatar creation often involve time-consuming scanning and reconstruction processes for each avatar, which limits their scalability. Furthermore, these methods do not offer the flexibility to sample new identities or modify existing ones. On the other hand, by learning a strong prior from data, generative models provide a promising alternative to traditional reconstruction methods, easing the time constraints for both data capture and processing. Additionally, generative methods enable downstream applications beyond reconstruction, such as editing and stylization. Nonetheless, the research on generative 3D avatars is still in its infancy, and therefore current methods still have limitations such as creating static avatars, lacking photo-realism, having incomplete facial details, or having limited drivability. To address this, we propose a text-conditioned generative model that can generate photo-realistic facial avatars of diverse identities, with more complete details like hair, eyes and mouth interior, and which can be driven through a powerful non-parametric latent expression space. Specifically, we integrate the generative and editing capabilities of latent diffusion models with a strong prior model for avatar expression driving. Our model can generate and control high-fidelity avatars, even those out-of-distribution. We also highlight its potential for downstream applications, including avatar editing and single-shot avatar reconstruction.
Phased Consistency Model
May 28, 2024The consistency model (CM) has recently made significant progress in accelerating the generation of diffusion models. However, its application to high-resolution, text-conditioned image generation in the latent space (a.k.a., LCM) remains unsatisfactory. In this paper, we identify three key flaws in the current design of LCM. We investigate the reasons behind these limitations and propose the Phased Consistency Model (PCM), which generalizes the design space and addresses all identified limitations. Our evaluations demonstrate that PCM significantly outperforms LCM across 1--16 step generation settings. While PCM is specifically designed for multi-step refinement, it achieves even superior or comparable 1-step generation results to previously state-of-the-art specifically designed 1-step methods. Furthermore, we show that PCM's methodology is versatile and applicable to video generation, enabling us to train the state-of-the-art few-step text-to-video generator. More details are available at https://g-u-n.github.io/projects/pcm/.
Deep Reward Supervisions for Tuning Text-to-Image Diffusion Models
May 01, 2024



Optimizing a text-to-image diffusion model with a given reward function is an important but underexplored research area. In this study, we propose Deep Reward Tuning (DRTune), an algorithm that directly supervises the final output image of a text-to-image diffusion model and back-propagates through the iterative sampling process to the input noise. We find that training earlier steps in the sampling process is crucial for low-level rewards, and deep supervision can be achieved efficiently and effectively by stopping the gradient of the denoising network input. DRTune is extensively evaluated on various reward models. It consistently outperforms other algorithms, particularly for low-level control signals, where all shallow supervision methods fail. Additionally, we fine-tune Stable Diffusion XL 1.0 (SDXL 1.0) model via DRTune to optimize Human Preference Score v2.1, resulting in the Favorable Diffusion XL 1.0 (FDXL 1.0) model. FDXL 1.0 significantly enhances image quality compared to SDXL 1.0 and reaches comparable quality compared with Midjourney v5.2.
ECNet: Effective Controllable Text-to-Image Diffusion Models
Mar 27, 2024The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.
Ponymation: Learning 3D Animal Motions from Unlabeled Online Videos
Dec 21, 2023We introduce Ponymation, a new method for learning a generative model of articulated 3D animal motions from raw, unlabeled online videos. Unlike existing approaches for motion synthesis, our model does not require any pose annotations or parametric shape models for training, and is learned purely from a collection of raw video clips obtained from the Internet. We build upon a recent work, MagicPony, which learns articulated 3D animal shapes purely from single image collections, and extend it on two fronts. First, instead of training on static images, we augment the framework with a video training pipeline that incorporates temporal regularizations, achieving more accurate and temporally consistent reconstructions. Second, we learn a generative model of the underlying articulated 3D motion sequences via a spatio-temporal transformer VAE, simply using 2D reconstruction losses without relying on any explicit pose annotations. At inference time, given a single 2D image of a new animal instance, our model reconstructs an articulated, textured 3D mesh, and generates plausible 3D animations by sampling from the learned motion latent space.