 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleEdit-12M: Scaling Open-Source Image Editing Data Generation via Multi-Agent Framework
Mar 21, 2026Instruction-based image editing has emerged as a key capability for unified multimodal models (UMMs), yet constructing large-scale, diverse, and high-quality editing datasets without costly proprietary APIs remains challenging. Previous image editing datasets either rely on closed-source models for annotation, which prevents cost-effective scaling, or employ fixed synthetic editing pipelines, which suffer from limited quality and generalizability. To address these challenges, we propose ScaleEditor, a fully open-source hierarchical multi-agent framework for end-to-end construction of large-scale, high-quality image editing datasets. Our pipeline consists of three key components: source image expansion with world-knowledge infusion, adaptive multi-agent editing instruction-image synthesis, and a task-aware data quality verification mechanism. Using ScaleEditor, we curate ScaleEdit-12M, the largest open-source image editing dataset to date, spanning 23 task families across diverse real and synthetic domains. Fine-tuning UniWorld-V1 and Bagel on ScaleEdit yields consistent gains, improving performance by up to 10.4% on ImgEdit and 35.1% on GEdit for general editing benchmarks and by up to 150.0% on RISE and 26.5% on KRIS-Bench for knowledge-infused benchmarks. These results demonstrate that open-source, agentic pipelines can approach commercial-grade data quality while retaining cost-effectiveness and scalability. Both the framework and dataset will be open-sourced.
Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing and Generation
Mar 12, 2026Reinforcement learning (RL) has emerged as a promising paradigm for enhancing image editing and text-to-image (T2I) generation. However, current reward models, which act as critics during RL, often suffer from hallucinations and assign noisy scores, inherently misguiding the optimization process. In this paper, we present FIRM (Faithful Image Reward Modeling), a comprehensive framework that develops robust reward models to provide accurate and reliable guidance for faithful image generation and editing. First, we design tailored data curation pipelines to construct high-quality scoring datasets. Specifically, we evaluate editing using both execution and consistency, while generation is primarily assessed via instruction following. Using these pipelines, we collect the FIRM-Edit-370K and FIRM-Gen-293K datasets, and train specialized reward models (FIRM-Edit-8B and FIRM-Gen-8B) that accurately reflect these criteria. Second, we introduce FIRM-Bench, a comprehensive benchmark specifically designed for editing and generation critics. Evaluations demonstrate that our models achieve superior alignment with human judgment compared to existing metrics. Furthermore, to seamlessly integrate these critics into the RL pipeline, we formulate a novel "Base-and-Bonus" reward strategy that balances competing objectives: Consistency-Modulated Execution (CME) for editing and Quality-Modulated Alignment (QMA) for generation. Empowered by this framework, our resulting models FIRM-Qwen-Edit and FIRM-SD3.5 achieve substantial performance breakthroughs. Comprehensive experiments demonstrate that FIRM mitigates hallucinations, establishing a new standard for fidelity and instruction adherence over existing general models. All of our datasets, models, and code have been publicly available at https://firm-reward.github.io.
GRADE: Benchmarking Discipline-Informed Reasoning in Image Editing
Mar 12, 2026Unified multimodal models target joint understanding, reasoning, and generation, but current image editing benchmarks are largely confined to natural images and shallow commonsense reasoning, offering limited assessment of this capability under structured, domain-specific constraints. In this work, we introduce GRADE, the first benchmark to assess discipline-informed knowledge and reasoning in image editing. GRADE comprises 520 carefully curated samples across 10 academic domains, spanning from natural science to social science. To support rigorous evaluation, we propose a multi-dimensional evaluation protocol that jointly assesses Discipline Reasoning, Visual Consistency, and Logical Readability. Extensive experiments on 20 state-of-the-art open-source and closed-source models reveal substantial limitations in current models under implicit, knowledge-intensive editing settings, leading to large performance gaps. Beyond quantitative scores, we conduct rigorous analyses and ablations to expose model shortcomings and identify the constraints within disciplinary editing. Together, GRADE pinpoints key directions for the future development of unified multimodal models, advancing the research on discipline-informed image editing and reasoning. Our benchmark and evaluation code are publicly released.
InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing
Mar 10, 2026Unified multimodal models (UMMs) that integrate understanding, reasoning, generation, and editing face inherent trade-offs between maintaining strong semantic comprehension and acquiring powerful generation capabilities. In this report, we present InternVL-U, a lightweight 4B-parameter UMM that democratizes these capabilities within a unified framework. Guided by the principles of unified contextual modeling and modality-specific modular design with decoupled visual representations, InternVL-U integrates a state-of-the-art Multimodal Large Language Model (MLLM) with a specialized MMDiT-based visual generation head. To further bridge the gap between aesthetic generation and high-level intelligence, we construct a comprehensive data synthesis pipeline targeting high-semantic-density tasks, such as text rendering and scientific reasoning, under a reasoning-centric paradigm that leverages Chain-of-Thought (CoT) to better align abstract user intent with fine-grained visual generation details. Extensive experiments demonstrate that InternVL-U achieves a superior performance - efficiency balance. Despite using only 4B parameters, it consistently outperforms unified baseline models with over 3x larger scales such as BAGEL (14B) on various generation and editing tasks, while retaining strong multimodal understanding and reasoning capabilities.
MADCrowner: Margin Aware Dental Crown Design with Template Deformation and Refinement
Mar 05, 2026Dental crown restoration is one of the most common treatment modalities for tooth defect, where personalized dental crown design is critical. While computer-aided design (CAD) systems have notably enhanced the efficiency of dental crown design, extensive manual adjustments are still required in the clinic workflow. Recent studies have explored the application of learning-based methods for the automated generation of restorative dental crowns. Nevertheless, these approaches were challenged by inadequate spatial resolution, noisy outputs, and overextension of surface reconstruction. To address these limitations, we propose \totalframework, a margin-aware mesh generation framework comprising CrownDeformR and CrownSegger. Inspired by the clinic manual workflow of dental crown design, we designed CrownDeformR to deform an initial template to the target crown based on anatomical context, which is extracted by a multi-scale intraoral scan encoder. Additionally, we introduced \marginseg, a novel margin segmentation network, to extract the cervical margin of the target tooth. The performance of CrownDeformR improved with the cervical margin as an extra constraint. And it was also utilized as the boundary condition for the tailored postprocessing method, which removed the overextended area of the reconstructed surface. We constructed a large-scale intraoral scan dataset and performed extensive experiments. The proposed method significantly outperformed existing approaches in both geometric accuracy and clinical feasibility.
MathCanvas: Intrinsic Visual Chain-of-Thought for Multimodal Mathematical Reasoning
Oct 16, 2025While Large Language Models (LLMs) have excelled in textual reasoning, they struggle with mathematical domains like geometry that intrinsically rely on visual aids. Existing approaches to Visual Chain-of-Thought (VCoT) are often limited by rigid external tools or fail to generate the high-fidelity, strategically-timed diagrams necessary for complex problem-solving. To bridge this gap, we introduce MathCanvas, a comprehensive framework designed to endow unified Large Multimodal Models (LMMs) with intrinsic VCoT capabilities for mathematics. Our approach consists of two phases. First, a Visual Manipulation stage pre-trains the model on a novel 15.2M-pair corpus, comprising 10M caption-to-diagram pairs (MathCanvas-Imagen) and 5.2M step-by-step editing trajectories (MathCanvas-Edit), to master diagram generation and editing. Second, a Strategic Visual-Aided Reasoning stage fine-tunes the model on MathCanvas-Instruct, a new 219K-example dataset of interleaved visual-textual reasoning paths, teaching it when and how to leverage visual aids. To facilitate rigorous evaluation, we introduce MathCanvas-Bench, a challenging benchmark with 3K problems that require models to produce interleaved visual-textual solutions. Our model, BAGEL-Canvas, trained under this framework, achieves an 86% relative improvement over strong LMM baselines on MathCanvas-Bench, demonstrating excellent generalization to other public math benchmarks. Our work provides a complete toolkit-framework, datasets, and benchmark-to unlock complex, human-like visual-aided reasoning in LMMs. Project Page: https://mathcanvas.github.io/
GenExam: A Multidisciplinary Text-to-Image Exam
Sep 17, 2025

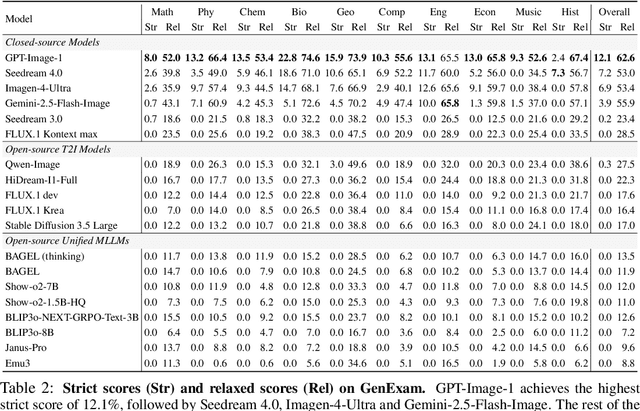

Exams are a fundamental test of expert-level intelligence and require integrated understanding, reasoning, and generation. Existing exam-style benchmarks mainly focus on understanding and reasoning tasks, and current generation benchmarks emphasize the illustration of world knowledge and visual concepts, neglecting the evaluation of rigorous drawing exams. We introduce GenExam, the first benchmark for multidisciplinary text-to-image exams, featuring 1,000 samples across 10 subjects with exam-style prompts organized under a four-level taxonomy. Each problem is equipped with ground-truth images and fine-grained scoring points to enable a precise evaluation of semantic correctness and visual plausibility. Experiments show that even state-of-the-art models such as GPT-Image-1 and Gemini-2.5-Flash-Image achieve less than 15% strict scores, and most models yield almost 0%, suggesting the great challenge of our benchmark. By framing image generation as an exam, GenExam offers a rigorous assessment of models' ability to integrate knowledge, reasoning, and generation, providing insights on the path to general AGI.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
Learning Adaptive and Temporally Causal Video Tokenization in a 1D Latent Space
May 22, 2025We propose AdapTok, an adaptive temporal causal video tokenizer that can flexibly allocate tokens for different frames based on video content. AdapTok is equipped with a block-wise masking strategy that randomly drops tail tokens of each block during training, and a block causal scorer to predict the reconstruction quality of video frames using different numbers of tokens. During inference, an adaptive token allocation strategy based on integer linear programming is further proposed to adjust token usage given predicted scores. Such design allows for sample-wise, content-aware, and temporally dynamic token allocation under a controllable overall budget. Extensive experiments for video reconstruction and generation on UCF-101 and Kinetics-600 demonstrate the effectiveness of our approach. Without additional image data, AdapTok consistently improves reconstruction quality and generation performance under different token budgets, allowing for more scalable and token-efficient generative video modeling.
LangBridge: Interpreting Image as a Combination of Language Embeddings
Mar 26, 2025



Recent years have witnessed remarkable advances in Large Vision-Language Models (LVLMs), which have achieved human-level performance across various complex vision-language tasks. Following LLaVA's paradigm, mainstream LVLMs typically employ a shallow MLP for visual-language alignment through a two-stage training process: pretraining for cross-modal alignment followed by instruction tuning. While this approach has proven effective, the underlying mechanisms of how MLPs bridge the modality gap remain poorly understood. Although some research has explored how LLMs process transformed visual tokens, few studies have investigated the fundamental alignment mechanism. Furthermore, the MLP adapter requires retraining whenever switching LLM backbones. To address these limitations, we first investigate the working principles of MLP adapters and discover that they learn to project visual embeddings into subspaces spanned by corresponding text embeddings progressively. Based on this insight, we propose LangBridge, a novel adapter that explicitly maps visual tokens to linear combinations of LLM vocabulary embeddings. This innovative design enables pretraining-free adapter transfer across different LLMs while maintaining performance. Our experimental results demonstrate that a LangBridge adapter pre-trained on Qwen2-0.5B can be directly applied to larger models such as LLaMA3-8B or Qwen2.5-14B while maintaining competitive performance. Overall, LangBridge enables interpretable vision-language alignment by grounding visual representations in LLM vocab embedding, while its plug-and-play design ensures efficient reuse across multiple LLMs with nearly no performance degradation. See our project page at https://jiaqiliao77.github.io/LangBridge.github.io/