 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactBench: A Cause-Driven Benchmark for Multimodal Hallucination via Systematic Evaluation
May 28, 2026While multimodal large language models (MLLMs) have achieved rapid progress in vision-language understanding, they remain prone to multimodal hallucinations, producing responses that are inconsistent with the visual input. Existing benchmarks predominantly focus on detecting hallucination outcomes rather than evaluating the underlying causes of these failures. Moreover, many benchmarks rely on simplistic scenarios and limited evaluation formats that no longer challenge state-of-the-art models. To address these limitations, we introduce ReactBench, a cause-driven hallucination benchmark featuring multiple tasks and an exam-style evaluation format. By generating adversarial images and hallucination-inducing queries, ReactBench introduces four targeted tasks: Relational Erasure, Counterfactual Attribute, Alteration Tracing, and Dense Counting. These tasks systematically expose co-occurrence bias, language priors, cross-image comparative perception deficiencies, and fine-grained perceptual bottlenecks. Beyond standard accuracy-based evaluation, we leverage Chain-of-Thought reasoning to identify fine-grained sub-causes of hallucination within each task. Extensive evaluations reveal that current MLLMs remain notably vulnerable to cause-specific hallucination triggers, demonstrating the value of ReactBench as a systematic and interpretable testbed for diagnosing and improving multimodal model robustness. The project page is available at https://reactbench.github.io/.
Allo{SR}$^2$: Rectifying One-Step Super-Resolution to Stay Real via Allomorphic Generative Flows
Apr 21, 2026Real-world image super-resolution (Real-SR) has been revolutionized by leveraging the powerful generative priors of large-scale diffusion and flow-based models. However, fine-tuning these models on limited LR-HR pairs often precipitates "prior collapse" that the model sacrifices its inherent generative richness to overfit specific training degradations. This issue is further exacerbated in one-step generation, where the absence of multi-step refinement leads to significant trajectory drift and artifact generation. In this paper, we propose Allo{SR}$^2$, a novel framework that rectifies one-step SR trajectories via allomorphic generative flows to maintain high-fidelity generative realism. Specifically, we utilize Signal-to-Noise Ratio (SNR) Guided Trajectory Initialization to establish a physically grounded starting state by aligning the degradation level of LR latent features with the optimal anchoring timestep of the pre-trained flow. To ensure a stable, curvature-free path for one-step inference, we propose Flow-Anchored Trajectory Consistency (FATC), which enforces velocity-level supervision across intermediate states. Furthermore, we develop Allomorphic Trajectory Matching (ATM), a self-adversarial alignment strategy that minimizes the distributional discrepancy between the SR flow and the generative flow in a unified vector field. Extensive experiments on both synthetic and real-world benchmarks demonstrate that Allo{SR}$^2$ achieves state-of-the-art performance in one-step Real-SR, offering a superior balance between restoration fidelity and generative realism while maintaining extreme efficiency.
GroupGPT: A Token-efficient and Privacy-preserving Agentic Framework for Multi-User Chat Assistant
Mar 01, 2026Recent advances in large language models (LLMs) have enabled increasingly capable chatbots. However, most existing systems focus on single-user settings and do not generalize well to multi-user group chats, where agents require more proactive and accurate intervention under complex, evolving contexts. Existing approaches typically rely on LLMs for both reasoning and generation, leading to high token consumption, limited scalability, and potential privacy risks. To address these challenges, we propose GroupGPT, a token-efficient and privacy-preserving agentic framework for multi-user chat assistant. GroupGPT adopts a small-large model collaborative architecture to decouple intervention timing from response generation, enabling efficient and accurate decision-making. The framework also supports multimodal inputs, including memes, images, videos, and voice messages. We further introduce MUIR, a benchmark dataset for multi-user chat assistant intervention reasoning. MUIR contains 2,500 annotated group chat segments with intervention labels and rationales, supporting evaluation of timing accuracy and response quality. We evaluate a range of models on MUIR, from large language models to smaller counterparts. Extensive experiments demonstrate that GroupGPT produces accurate and well-timed responses, achieving an average score of 4.72/5.0 in LLM-based evaluation, and is well received by users across diverse group chat scenarios. Moreover, GroupGPT reduces token usage by up to 3 times compared to baseline methods, while providing privacy sanitization of user messages before cloud transmission. Code is available at: https://github.com/Eliot-Shen/GroupGPT .
Towards Efficient Large Language Reasoning Models via Extreme-Ratio Chain-of-Thought Compression
Feb 09, 2026Chain-of-Thought (CoT) reasoning successfully enhances the reasoning capabilities of Large Language Models (LLMs), yet it incurs substantial computational overhead for inference. Existing CoT compression methods often suffer from a critical loss of logical fidelity at high compression ratios, resulting in significant performance degradation. To achieve high-fidelity, fast reasoning, we propose a novel EXTreme-RAtio Chain-of-Thought Compression framework, termed Extra-CoT, which aggressively reduces the token budget while preserving answer accuracy. To generate reliable, high-fidelity supervision, we first train a dedicated semantically-preserved compressor on mathematical CoT data with fine-grained annotations. An LLM is then fine-tuned on these compressed pairs via a mixed-ratio supervised fine-tuning (SFT), teaching it to follow a spectrum of compression budgets and providing a stable initialization for reinforcement learning (RL). We further propose Constrained and Hierarchical Ratio Policy Optimization (CHRPO) to explicitly incentivize question-solving ability under lower budgets by a hierarchical reward. Experiments on three mathematical reasoning benchmarks show the superiority of Extra-CoT. For example, on MATH-500 using Qwen3-1.7B, Extra-CoT achieves over 73\% token reduction with an accuracy improvement of 0.6\%, significantly outperforming state-of-the-art (SOTA) methods.
CLIP-Map: Structured Matrix Mapping for Parameter-Efficient CLIP Compression
Feb 05, 2026Contrastive Language-Image Pre-training (CLIP) has achieved widely applications in various computer vision tasks, e.g., text-to-image generation, Image-Text retrieval and Image captioning. However, CLIP suffers from high memory and computation cost, which prohibits its usage to the resource-limited application scenarios. Existing CLIP compression methods typically reduce the size of pre-trained CLIP weights by selecting their subset as weight inheritance for further retraining via mask optimization or important weight measurement. However, these select-based weight inheritance often compromises the feature presentation ability, especially on the extreme compression. In this paper, we propose a novel mapping-based CLIP compression framework, CLIP-Map. It leverages learnable matrices to map and combine pretrained weights by Full-Mapping with Kronecker Factorization, aiming to preserve as much information from the original weights as possible. To mitigate the optimization challenges introduced by the learnable mapping, we propose Diagonal Inheritance Initialization to reduce the distribution shifting problem for efficient and effective mapping learning. Extensive experimental results demonstrate that the proposed CLIP-Map outperforms select-based frameworks across various compression ratios, with particularly significant gains observed under high compression settings.
Generation Properties of Stochastic Interpolation under Finite Training Set
Sep 26, 2025



This paper investigates the theoretical behavior of generative models under finite training populations. Within the stochastic interpolation generative framework, we derive closed-form expressions for the optimal velocity field and score function when only a finite number of training samples are available. We demonstrate that, under some regularity conditions, the deterministic generative process exactly recovers the training samples, while the stochastic generative process manifests as training samples with added Gaussian noise. Beyond the idealized setting, we consider model estimation errors and introduce formal definitions of underfitting and overfitting specific to generative models. Our theoretical analysis reveals that, in the presence of estimation errors, the stochastic generation process effectively produces convex combinations of training samples corrupted by a mixture of uniform and Gaussian noise. Experiments on generation tasks and downstream tasks such as classification support our theory.
DF-LLaVA: Unlocking MLLM's potential for Synthetic Image Detection via Prompt-Guided Knowledge Injection
Sep 18, 2025With the increasing prevalence of synthetic images, evaluating image authenticity and locating forgeries accurately while maintaining human interpretability remains a challenging task. Existing detection models primarily focus on simple authenticity classification, ultimately providing only a forgery probability or binary judgment, which offers limited explanatory insights into image authenticity. Moreover, while MLLM-based detection methods can provide more interpretable results, they still lag behind expert models in terms of pure authenticity classification accuracy. To address this, we propose DF-LLaVA, a simple yet effective framework that unlocks the intrinsic discrimination potential of MLLMs. Our approach first extracts latent knowledge from MLLMs and then injects it into training via prompts. This framework allows LLaVA to achieve outstanding detection accuracy exceeding expert models while still maintaining the interpretability offered by MLLMs. Extensive experiments confirm the superiority of our DF-LLaVA, achieving both high accuracy and explainability in synthetic image detection. Code is available online at: https://github.com/Eliot-Shen/DF-LLaVA.
Interleaving Reasoning for Better Text-to-Image Generation
Sep 09, 2025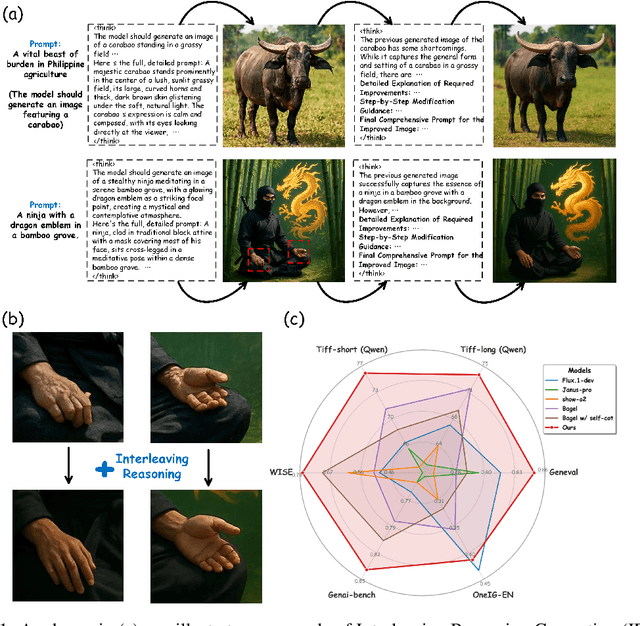
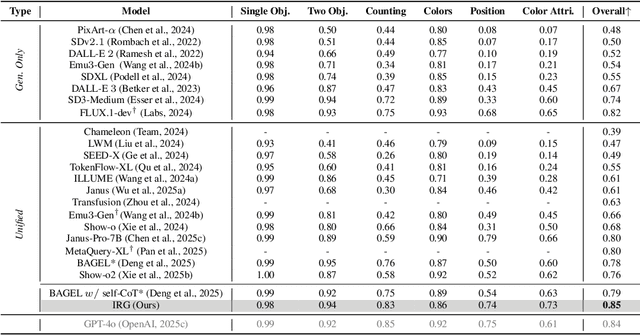

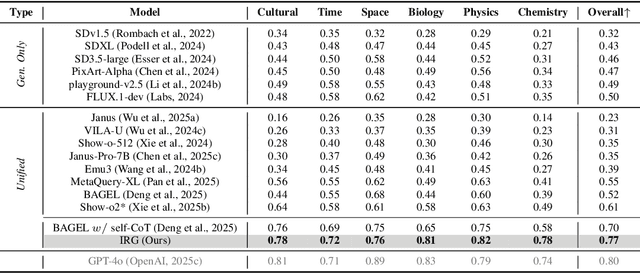
Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
CompBench: Benchmarking Complex Instruction-guided Image Editing
May 18, 2025While real-world applications increasingly demand intricate scene manipulation, existing instruction-guided image editing benchmarks often oversimplify task complexity and lack comprehensive, fine-grained instructions. To bridge this gap, we introduce, a large-scale benchmark specifically designed for complex instruction-guided image editing. CompBench features challenging editing scenarios that incorporate fine-grained instruction following, spatial and contextual reasoning, thereby enabling comprehensive evaluation of image editing models' precise manipulation capabilities. To construct CompBench, We propose an MLLM-human collaborative framework with tailored task pipelines. Furthermore, we propose an instruction decoupling strategy that disentangles editing intents into four key dimensions: location, appearance, dynamics, and objects, ensuring closer alignment between instructions and complex editing requirements. Extensive evaluations reveal that CompBench exposes fundamental limitations of current image editing models and provides critical insights for the development of next-generation instruction-guided image editing systems.
TimeSoccer: An End-to-End Multimodal Large Language Model for Soccer Commentary Generation
Apr 24, 2025Soccer is a globally popular sporting event, typically characterized by long matches and distinctive highlight moments. Recent advances in Multimodal Large Language Models (MLLMs) offer promising capabilities in temporal grounding and video understanding, soccer commentary generation often requires precise temporal localization and semantically rich descriptions over long-form video. However, existing soccer MLLMs often rely on the temporal a priori for caption generation, so they cannot process the soccer video end-to-end. While some traditional approaches follow a two-step paradigm that is complex and fails to capture the global context to achieve suboptimal performance. To solve the above issues, we present TimeSoccer, the first end-to-end soccer MLLM for Single-anchor Dense Video Captioning (SDVC) in full-match soccer videos. TimeSoccer jointly predicts timestamps and generates captions in a single pass, enabling global context modeling across 45-minute matches. To support long video understanding of soccer matches, we introduce MoFA-Select, a training-free, motion-aware frame compression module that adaptively selects representative frames via a coarse-to-fine strategy, and incorporates complementary training paradigms to strengthen the model's ability to handle long temporal sequences. Extensive experiments demonstrate that our TimeSoccer achieves State-of-The-Art (SoTA) performance on the SDVC task in an end-to-end form, generating high-quality commentary with accurate temporal alignment and strong semantic relevance.