 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Specific Data Synthesis for LLMs via Minimal Sufficient Representation Learning
May 28, 2026Large Language Models have demonstrated remarkable progress in general-purpose capabilities and can achieve strong performance in specific domains through fine-tuning on domain-specific data. However, acquiring high-quality data for target domains remains a significant challenge. Existing data synthesis approaches follow a deductive paradigm, heavily relying on explicit domain descriptions expressed in natural language and careful prompt engineering, limiting their applicability in real-world scenarios where domains are difficult to describe or formally articulate. In this work, we tackle the underexplored problem of domain-specific data synthesis through an inductive paradigm, where the target domain is defined only through a set of reference examples, particularly when domain characteristics are difficult to articulate in natural language. We propose a novel framework, DOMINO, that learns a minimal sufficient domain representation from reference samples and leverages it to guide the generation of domain-aligned synthetic data. DOMINO integrates prompt tuning with a contrastive disentanglement objective to separate domain-level patterns from sample-specific noise, mitigating overfitting while preserving core domain characteristics. Theoretically, we prove that DOMINO expands the support of the synthetic data distribution, ensuring greater diversity. Empirically, on challenging coding benchmarks where domain definitions are implicit, fine-tuning on data synthesized by DOMINO improves Pass@1 accuracy by up to 4.63\% over strong, instruction-tuned backbones, demonstrating its effectiveness and robustness. This work establishes a new paradigm for domain-specific data synthesis, enabling practical and scalable domain adaptation without manual prompt design or natural language domain specifications.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
MiroFlow: Towards High-Performance and Robust Open-Source Agent Framework for General Deep Research Tasks
Feb 26, 2026Despite the remarkable progress of large language models (LLMs), the capabilities of standalone LLMs have begun to plateau when tackling real-world, complex tasks that require interaction with external tools and dynamic environments. Although recent agent frameworks aim to enhance model autonomy through tool integration and external interaction, they still suffer from naive workflows, unstable performance, limited support across diverse benchmarks and tasks, and heavy reliance on costly commercial APIs. In this work, we propose a high-performance and robust open-source agent framework, termed MiroFlow, which incorporates an agent graph for flexible orchestration, an optional deep reasoning mode to enhance performance, and a robust workflow execution to ensure stable and reproducible performance. Extensive experiments demonstrate that MiroFlow consistently achieves state-of-the-art performance across multiple agent benchmarks, including GAIA, BrowseComp-EN/ZH, HLE, xBench-DeepSearch, and notably FutureX. We hope it could serve as an easily accessible, reproducible, and comparable baseline for the deep research community.
Training-Free Acceleration for Document Parsing Vision-Language Model with Hierarchical Speculative Decoding
Feb 13, 2026Document parsing is a fundamental task in multimodal understanding, supporting a wide range of downstream applications such as information extraction and intelligent document analysis. Benefiting from strong semantic modeling and robust generalization, VLM-based end-to-end approaches have emerged as the mainstream paradigm in recent years. However, these models often suffer from substantial inference latency, as they must auto-regressively generate long token sequences when processing long-form documents. In this work, motivated by the extremely long outputs and complex layout structures commonly found in document parsing, we propose a training-free and highly efficient acceleration method. Inspired by speculative decoding, we employ a lightweight document parsing pipeline as a draft model to predict batches of future tokens, while the more accurate VLM verifies these draft predictions in parallel. Moreover, we further exploit the layout-structured nature of documents by partitioning each page into independent regions, enabling parallel decoding of each region using the same draft-verify strategy. The final predictions are then assembled according to the natural reading order. Experimental results demonstrate the effectiveness of our approach: on the general-purpose OmniDocBench, our method provides a 2.42x lossless acceleration for the dots.ocr model, and achieves up to 4.89x acceleration on long-document parsing tasks. We will release our code to facilitate reproducibility and future research.
LLM-VA: Resolving the Jailbreak-Overrefusal Trade-off via Vector Alignment
Jan 27, 2026Safety-aligned LLMs suffer from two failure modes: jailbreak (answering harmful inputs) and over-refusal (declining benign queries). Existing vector steering methods adjust the magnitude of answer vectors, but this creates a fundamental trade-off -- reducing jailbreak increases over-refusal and vice versa. We identify the root cause: LLMs encode the decision to answer (answer vector $v_a$) and the judgment of input safety (benign vector $v_b$) as nearly orthogonal directions, treating them as independent processes. We propose LLM-VA, which aligns $v_a$ with $v_b$ through closed-form weight updates, making the model's willingness to answer causally dependent on its safety assessment -- without fine-tuning or architectural changes. Our method identifies vectors at each layer using SVMs, selects safety-relevant layers, and iteratively aligns vectors via minimum-norm weight modifications. Experiments on 12 LLMs demonstrate that LLM-VA achieves 11.45% higher F1 than the best baseline while preserving 95.92% utility, and automatically adapts to each model's safety bias without manual tuning. Code and models are available at https://hotbento.github.io/LLM-VA-Web/.
RP-CATE: Recurrent Perceptron-based Channel Attention Transformer Encoder for Industrial Hybrid Modeling
Dec 22, 2025Nowadays, industrial hybrid modeling which integrates both mechanistic modeling and machine learning-based modeling techniques has attracted increasing interest from scholars due to its high accuracy, low computational cost, and satisfactory interpretability. Nevertheless, the existing industrial hybrid modeling methods still face two main limitations. First, current research has mainly focused on applying a single machine learning method to one specific task, failing to develop a comprehensive machine learning architecture suitable for modeling tasks, which limits their ability to effectively represent complex industrial scenarios. Second, industrial datasets often contain underlying associations (e.g., monotonicity or periodicity) that are not adequately exploited by current research, which can degrade model's predictive performance. To address these limitations, this paper proposes the Recurrent Perceptron-based Channel Attention Transformer Encoder (RP-CATE), with three distinctive characteristics: 1: We developed a novel architecture by replacing the self-attention mechanism with channel attention and incorporating our proposed Recurrent Perceptron (RP) Module into Transformer, achieving enhanced effectiveness for industrial modeling tasks compared to the original Transformer. 2: We proposed a new data type called Pseudo-Image Data (PID) tailored for channel attention requirements and developed a cyclic sliding window method for generating PID. 3: We introduced the concept of Pseudo-Sequential Data (PSD) and a method for converting industrial datasets into PSD, which enables the RP Module to capture the underlying associations within industrial dataset more effectively. An experiment aimed at hybrid modeling in chemical engineering was conducted by using RP-CATE and the experimental results demonstrate that RP-CATE achieves the best performance compared to other baseline models.
ViCO: A Training Strategy towards Semantic Aware Dynamic High-Resolution
Oct 14, 2025



Existing Multimodal Large Language Models (MLLMs) suffer from increased inference costs due to the additional vision tokens introduced by image inputs. In this work, we propose Visual Consistency Learning (ViCO), a novel training algorithm that enables the model to represent images of varying semantic complexities using different numbers of vision tokens. The key idea behind our method is to employ multiple MLP connectors, each with a different image compression ratio, to downsample the vision tokens based on the semantic complexity of the image. During training, we minimize the KL divergence between the responses conditioned on different MLP connectors. At inference time, we introduce an image router, termed Visual Resolution Router (ViR), that automatically selects the appropriate compression rate for each image patch. Compared with existing dynamic high-resolution strategies, which adjust the number of visual tokens based on image resolutions, our method dynamically adapts the number of visual tokens according to semantic complexity. Experimental results demonstrate that our method can reduce the number of vision tokens by up to 50% while maintaining the model's perception, reasoning, and OCR capabilities. We hope this work will contribute to the development of more efficient MLLMs. The code and models will be released to facilitate future research.
ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
Sep 18, 2025



Vision-Language Models (VLMs) have enabled computer use agents (CUAs) that operate GUIs autonomously, showing great potential, yet progress is limited by the lack of large-scale, open-source computer use data and foundation models. In this work, we introduce ScaleCUA, a step toward scaling open-source CUAs. It offers a large-scale dataset spanning 6 operating systems and 3 task domains, built via a closed-loop pipeline uniting automated agents with human experts. Trained on this scaled-up data, ScaleCUA can operate seamlessly across platforms. Specifically, it delivers strong gains over baselines (+26.6 on WebArena-Lite-v2, +10.7 on ScreenSpot-Pro) and sets new state-of-the-art results (94.4% on MMBench-GUI L1-Hard, 60.6% on OSWorld-G, 47.4% on WebArena-Lite-v2). These findings underscore the power of data-driven scaling for general-purpose computer use agents. We will release data, models, and code to advance future research: https://github.com/OpenGVLab/ScaleCUA.
GenExam: A Multidisciplinary Text-to-Image Exam
Sep 17, 2025

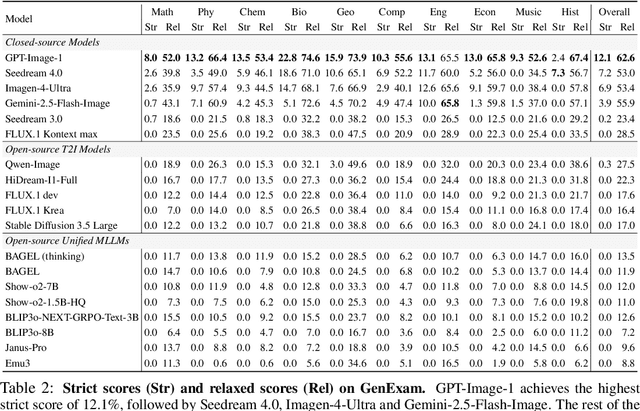

Exams are a fundamental test of expert-level intelligence and require integrated understanding, reasoning, and generation. Existing exam-style benchmarks mainly focus on understanding and reasoning tasks, and current generation benchmarks emphasize the illustration of world knowledge and visual concepts, neglecting the evaluation of rigorous drawing exams. We introduce GenExam, the first benchmark for multidisciplinary text-to-image exams, featuring 1,000 samples across 10 subjects with exam-style prompts organized under a four-level taxonomy. Each problem is equipped with ground-truth images and fine-grained scoring points to enable a precise evaluation of semantic correctness and visual plausibility. Experiments show that even state-of-the-art models such as GPT-Image-1 and Gemini-2.5-Flash-Image achieve less than 15% strict scores, and most models yield almost 0%, suggesting the great challenge of our benchmark. By framing image generation as an exam, GenExam offers a rigorous assessment of models' ability to integrate knowledge, reasoning, and generation, providing insights on the path to general AGI.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.