 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSgSum: Transforming Multi-document Summarization into Sub-graph Selection
Oct 25, 2021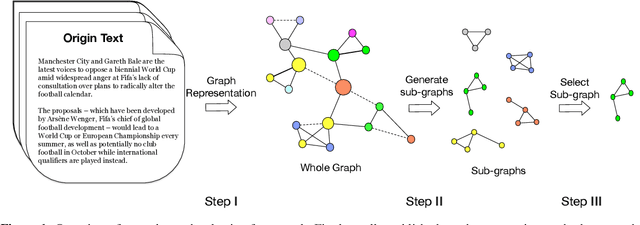
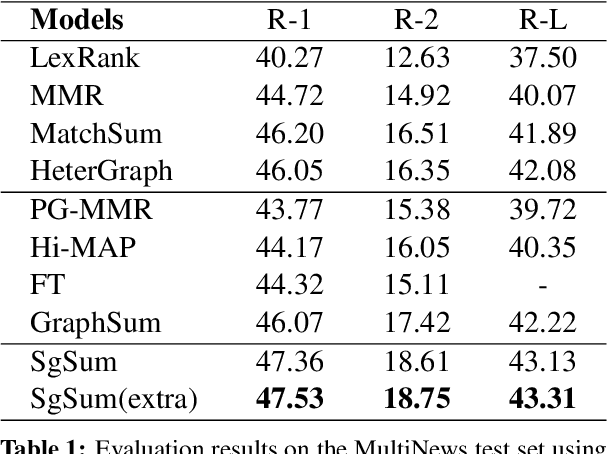
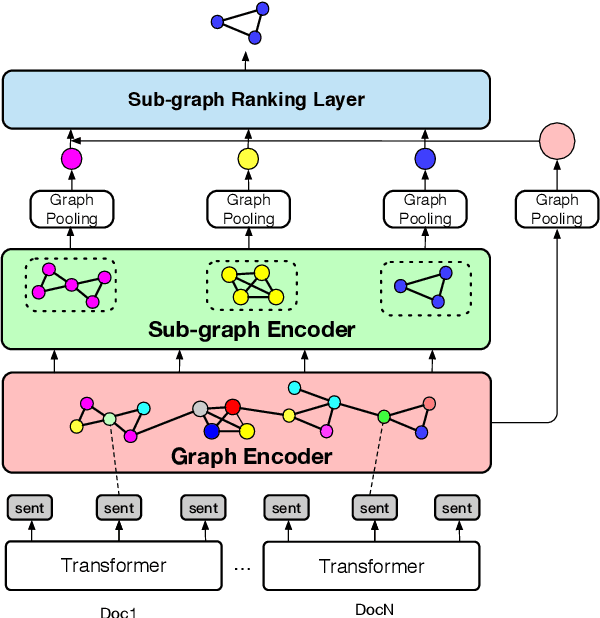
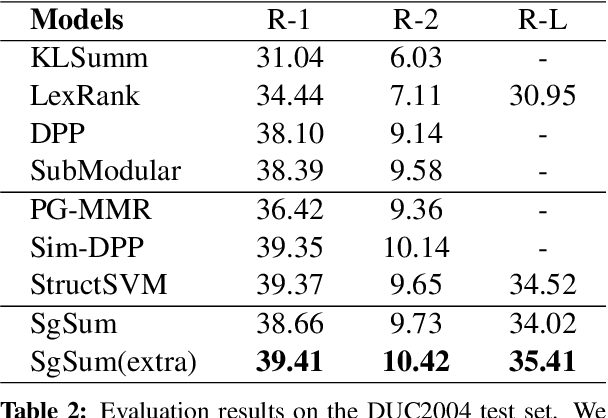
Most of existing extractive multi-document summarization (MDS) methods score each sentence individually and extract salient sentences one by one to compose a summary, which have two main drawbacks: (1) neglecting both the intra and cross-document relations between sentences; (2) neglecting the coherence and conciseness of the whole summary. In this paper, we propose a novel MDS framework (SgSum) to formulate the MDS task as a sub-graph selection problem, in which source documents are regarded as a relation graph of sentences (e.g., similarity graph or discourse graph) and the candidate summaries are its sub-graphs. Instead of selecting salient sentences, SgSum selects a salient sub-graph from the relation graph as the summary. Comparing with traditional methods, our method has two main advantages: (1) the relations between sentences are captured by modeling both the graph structure of the whole document set and the candidate sub-graphs; (2) directly outputs an integrate summary in the form of sub-graph which is more informative and coherent. Extensive experiments on MultiNews and DUC datasets show that our proposed method brings substantial improvements over several strong baselines. Human evaluation results also demonstrate that our model can produce significantly more coherent and informative summaries compared with traditional MDS methods. Moreover, the proposed architecture has strong transfer ability from single to multi-document input, which can reduce the resource bottleneck in MDS tasks. Our code and results are available at: \url{https://github.com/PaddlePaddle/Research/tree/master/NLP/EMNLP2021-SgSum}.
RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking
Oct 14, 2021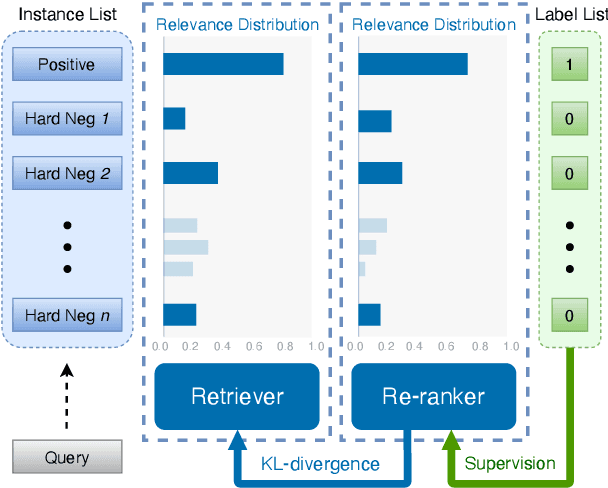

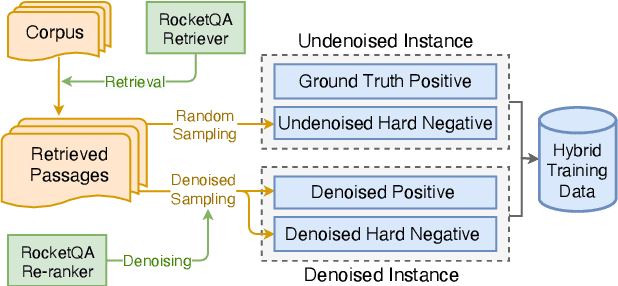
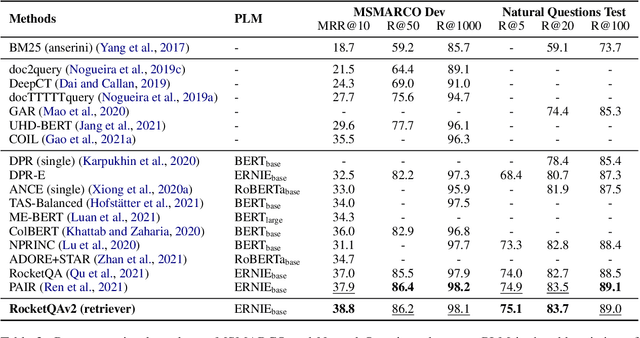
In various natural language processing tasks, passage retrieval and passage re-ranking are two key procedures in finding and ranking relevant information. Since both the two procedures contribute to the final performance, it is important to jointly optimize them in order to achieve mutual improvement. In this paper, we propose a novel joint training approach for dense passage retrieval and passage re-ranking. A major contribution is that we introduce the dynamic listwise distillation, where we design a unified listwise training approach for both the retriever and the re-ranker. During the dynamic distillation, the retriever and the re-ranker can be adaptively improved according to each other's relevance information. We also propose a hybrid data augmentation strategy to construct diverse training instances for listwise training approach. Extensive experiments show the effectiveness of our approach on both MSMARCO and Natural Questions datasets. Our code is available at https://github.com/PaddlePaddle/RocketQA.
Building Chinese Biomedical Language Models via Multi-Level Text Discrimination
Oct 14, 2021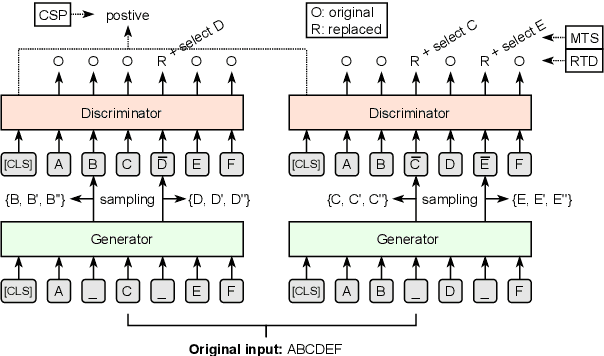
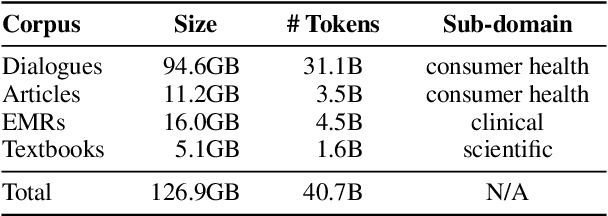
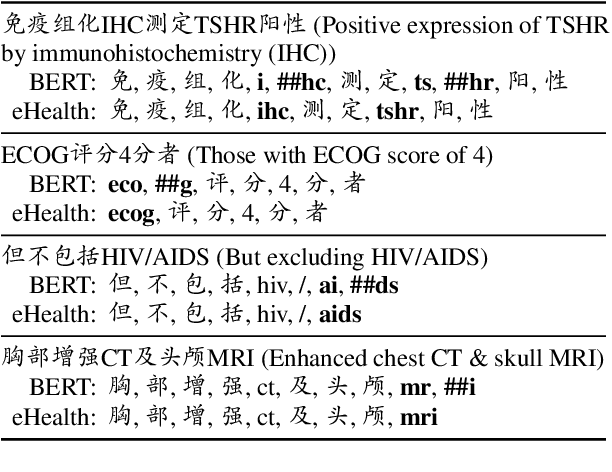
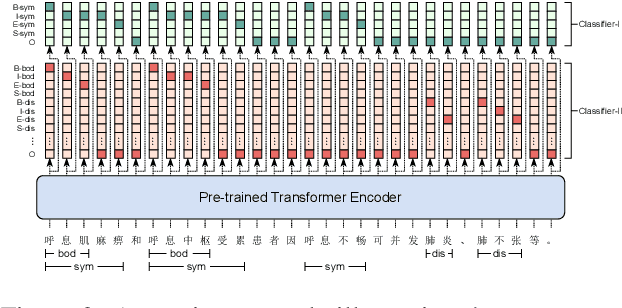
Pre-trained language models (PLMs), such as BERT and GPT, have revolutionized the field of NLP, not only in the general domain but also in the biomedical domain. Most prior efforts in building biomedical PLMs have resorted simply to domain adaptation and focused mainly on English. In this work we introduce eHealth, a biomedical PLM in Chinese built with a new pre-training framework. This new framework trains eHealth as a discriminator through both token-level and sequence-level discrimination. The former is to detect input tokens corrupted by a generator and select their original signals from plausible candidates, while the latter is to further distinguish corruptions of a same original sequence from those of the others. As such, eHealth can learn language semantics at both the token and sequence levels. Extensive experiments on 11 Chinese biomedical language understanding tasks of various forms verify the effectiveness and superiority of our approach. The pre-trained model is available to the public at \url{https://github.com/PaddlePaddle/Research/tree/master/KG/eHealth} and the code will also be released later.
Do What Nature Did To Us: Evolving Plastic Recurrent Neural Networks For Task Generalization
Sep 29, 2021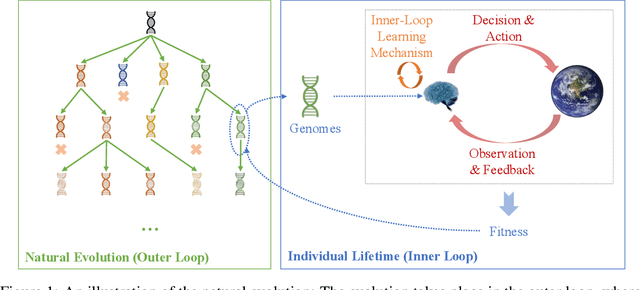
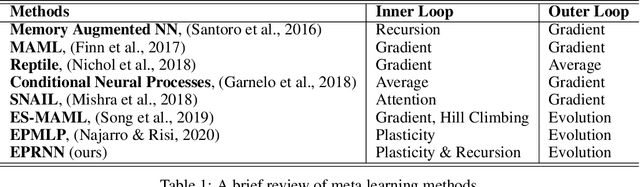
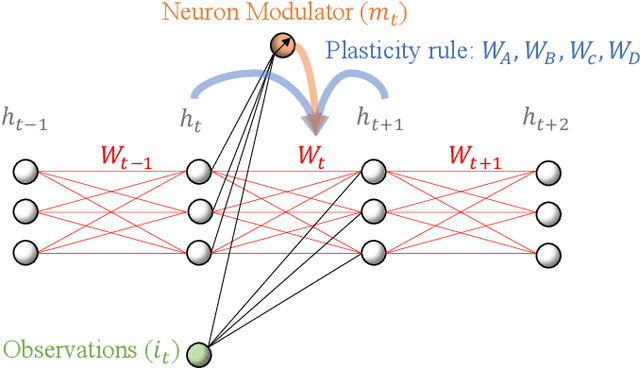

While artificial neural networks (ANNs) have been widely adopted in machine learning, researchers are increasingly obsessed by the gaps between ANNs and biological neural networks (BNNs). In this paper, we propose a framework named as Evolutionary Plastic Recurrent Neural Networks} (EPRNN). Inspired by BNN, EPRNN composes Evolution Strategies, Plasticity Rules, and Recursion-based Learning all in one meta learning framework for generalization to different tasks. More specifically, EPRNN incorporates with nested loops for meta learning -- an outer loop searches for optimal initial parameters of the neural network and learning rules; an inner loop adapts to specific tasks. In the inner loop of EPRNN, we effectively attain both long term memory and short term memory by forging plasticity with recursion-based learning mechanisms, both of which are believed to be responsible for memristance in BNNs. The inner-loop setting closely simulate that of BNNs, which neither query from any gradient oracle for optimization nor require the exact forms of learning objectives. To evaluate the performance of EPRNN, we carry out extensive experiments in two groups of tasks: Sequence Predicting, and Wheeled Robot Navigating. The experiment results demonstrate the unique advantage of EPRNN compared to state-of-the-arts based on plasticity and recursion while yielding comparably good performance against deep learning based approaches in the tasks. The experiment results suggest the potential of EPRNN to generalize to variety of tasks and encourage more efforts in plasticity and recursion based learning mechanisms.
Self-Supervised Learning for MRI Reconstruction with a Parallel Network Training Framework
Sep 26, 2021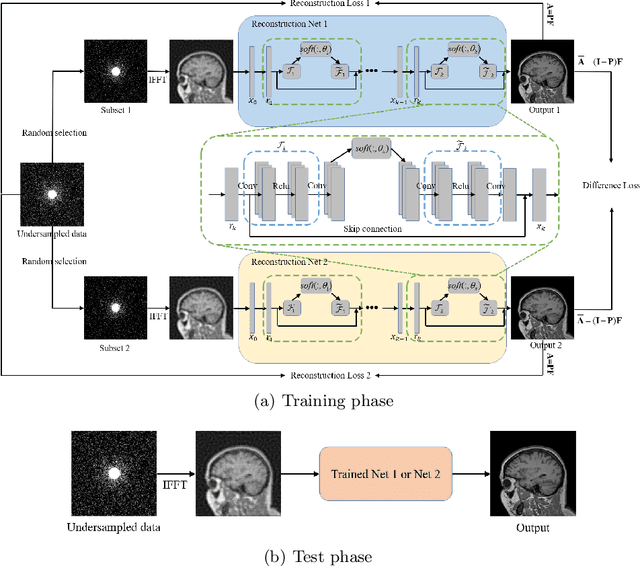
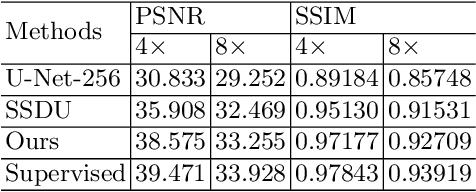

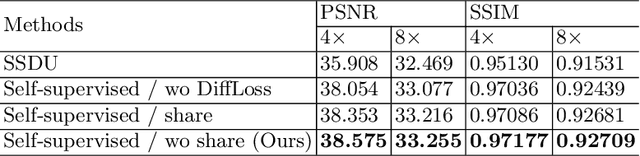
Image reconstruction from undersampled k-space data plays an important role in accelerating the acquisition of MR data, and a lot of deep learning-based methods have been exploited recently. Despite the achieved inspiring results, the optimization of these methods commonly relies on the fully-sampled reference data, which are time-consuming and difficult to collect. To address this issue, we propose a novel self-supervised learning method. Specifically, during model optimization, two subsets are constructed by randomly selecting part of k-space data from the undersampled data and then fed into two parallel reconstruction networks to perform information recovery. Two reconstruction losses are defined on all the scanned data points to enhance the network's capability of recovering the frequency information. Meanwhile, to constrain the learned unscanned data points of the network, a difference loss is designed to enforce consistency between the two parallel networks. In this way, the reconstruction model can be properly trained with only the undersampled data. During the model evaluation, the undersampled data are treated as the inputs and either of the two trained networks is expected to reconstruct the high-quality results. The proposed method is flexible and can be employed in any existing deep learning-based method. The effectiveness of the method is evaluated on an open brain MRI dataset. Experimental results demonstrate that the proposed self-supervised method can achieve competitive reconstruction performance compared to the corresponding supervised learning method at high acceleration rates (4 and 8). The code is publicly available at \url{https://github.com/chenhu96/Self-Supervised-MRI-Reconstruction}.
PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
Sep 20, 2021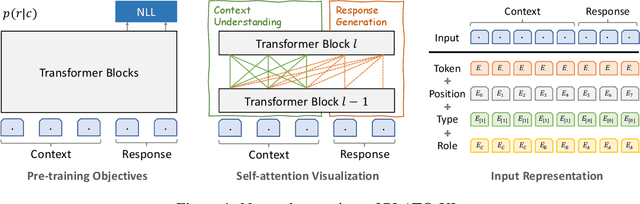
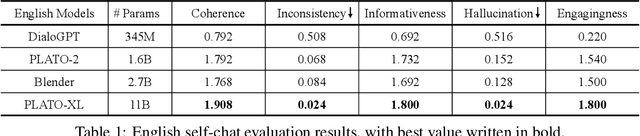

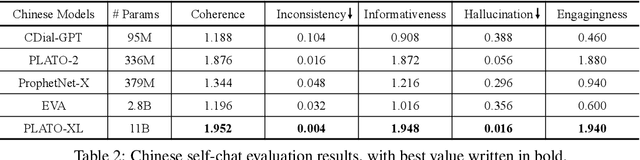
To explore the limit of dialogue generation pre-training, we present the models of PLATO-XL with up to 11 billion parameters, trained on both Chinese and English social media conversations. To train such large models, we adopt the architecture of unified transformer with high computation and parameter efficiency. In addition, we carry out multi-party aware pre-training to better distinguish the characteristic information in social media conversations. With such designs, PLATO-XL successfully achieves superior performances as compared to other approaches in both Chinese and English chitchat. We further explore the capacity of PLATO-XL on other conversational tasks, such as knowledge grounded dialogue and task-oriented conversation. The experimental results indicate that PLATO-XL obtains state-of-the-art results across multiple conversational tasks, verifying its potential as a foundation model of conversational AI.
DuRecDial 2.0: A Bilingual Parallel Corpus for Conversational Recommendation
Sep 18, 2021In this paper, we provide a bilingual parallel human-to-human recommendation dialog dataset (DuRecDial 2.0) to enable researchers to explore a challenging task of multilingual and cross-lingual conversational recommendation. The difference between DuRecDial 2.0 and existing conversational recommendation datasets is that the data item (Profile, Goal, Knowledge, Context, Response) in DuRecDial 2.0 is annotated in two languages, both English and Chinese, while other datasets are built with the setting of a single language. We collect 8.2k dialogs aligned across English and Chinese languages (16.5k dialogs and 255k utterances in total) that are annotated by crowdsourced workers with strict quality control procedure. We then build monolingual, multilingual, and cross-lingual conversational recommendation baselines on DuRecDial 2.0. Experiment results show that the use of additional English data can bring performance improvement for Chinese conversational recommendation, indicating the benefits of DuRecDial 2.0. Finally, this dataset provides a challenging testbed for future studies of monolingual, multilingual, and cross-lingual conversational recommendation.
Mixup Decoding for Diverse Machine Translation
Sep 14, 2021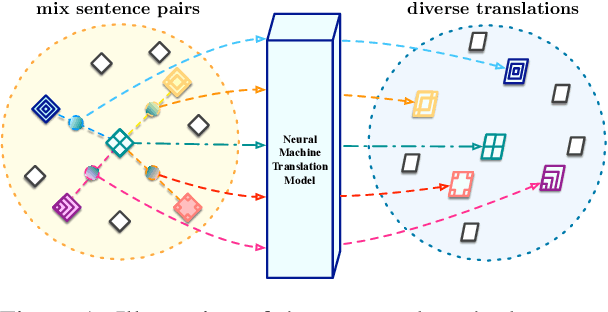

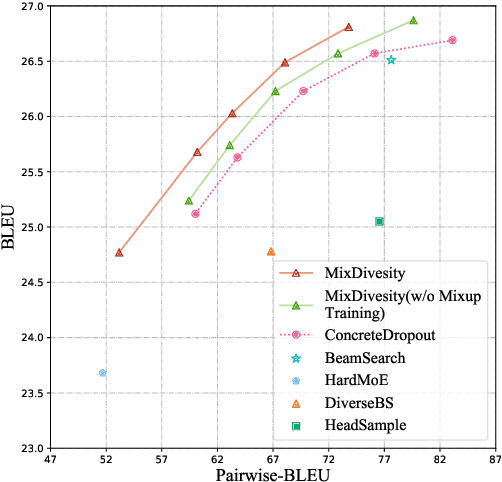
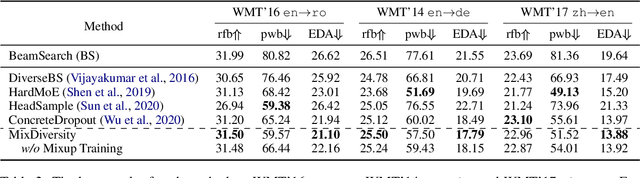
Diverse machine translation aims at generating various target language translations for a given source language sentence. Leveraging the linear relationship in the sentence latent space introduced by the mixup training, we propose a novel method, MixDiversity, to generate different translations for the input sentence by linearly interpolating it with different sentence pairs sampled from the training corpus when decoding. To further improve the faithfulness and diversity of the translations, we propose two simple but effective approaches to select diverse sentence pairs in the training corpus and adjust the interpolation weight for each pair correspondingly. Moreover, by controlling the interpolation weight, our method can achieve the trade-off between faithfulness and diversity without any additional training, which is required in most of the previous methods. Experiments on WMT'16 en-ro, WMT'14 en-de, and WMT'17 zh-en are conducted to show that our method substantially outperforms all previous diverse machine translation methods.
DuTrust: A Sentiment Analysis Dataset for Trustworthiness Evaluation
Sep 07, 2021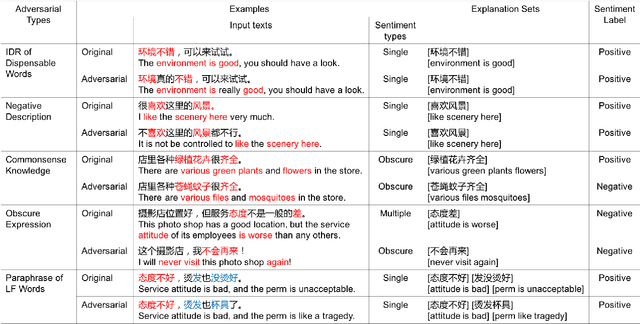
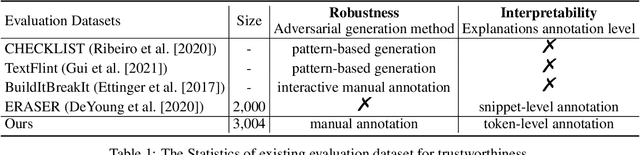


While deep learning models have greatly improved the performance of most artificial intelligence tasks, they are often criticized to be untrustworthy due to the black-box problem. Consequently, many works have been proposed to study the trustworthiness of deep learning. However, as most open datasets are designed for evaluating the accuracy of model outputs, there is still a lack of appropriate datasets for evaluating the inner workings of neural networks. The lack of datasets obviously hinders the development of trustworthiness research. Therefore, in order to systematically evaluate the factors for building trustworthy systems, we propose a novel and well-annotated sentiment analysis dataset to evaluate robustness and interpretability. To evaluate these factors, our dataset contains diverse annotations about the challenging distribution of instances, manual adversarial instances and sentiment explanations. Several evaluation metrics are further proposed for interpretability and robustness. Based on the dataset and metrics, we conduct comprehensive comparisons for the trustworthiness of three typical models, and also study the relations between accuracy, robustness and interpretability. We release this trustworthiness evaluation dataset at \url{https://github/xyz} and hope our work can facilitate the progress on building more trustworthy systems for real-world applications.
GEDIT: Geographic-Enhanced and Dependency-Guided Tagging for Joint POI and Accessibility Extraction at Baidu Maps
Aug 20, 2021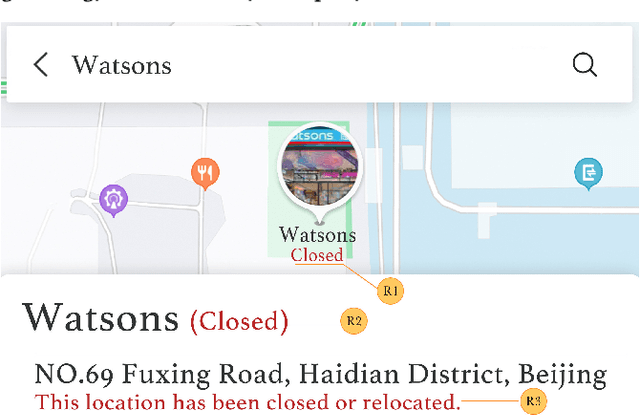

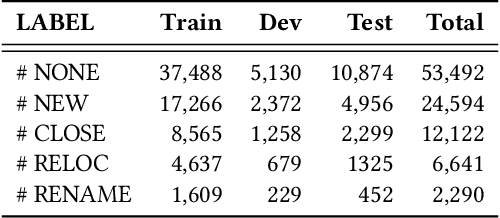

Providing timely accessibility reminders of a point-of-interest (POI) plays a vital role in improving user satisfaction of finding places and making visiting decisions. However, it is difficult to keep the POI database in sync with the real-world counterparts due to the dynamic nature of business changes. To alleviate this problem, we formulate and present a practical solution that jointly extracts POI mentions and identifies their coupled accessibility labels from unstructured text. We approach this task as a sequence tagging problem, where the goal is to produce <POI name, accessibility label> pairs from unstructured text. This task is challenging because of two main issues: (1) POI names are often newly-coined words so as to successfully register new entities or brands and (2) there may exist multiple pairs in the text, which necessitates dealing with one-to-many or many-to-one mapping to make each POI coupled with its accessibility label. To this end, we propose a Geographic-Enhanced and Dependency-guIded sequence Tagging (GEDIT) model to concurrently address the two challenges. First, to alleviate challenge #1, we develop a geographic-enhanced pre-trained model to learn the text representations. Second, to mitigate challenge #2, we apply a relational graph convolutional network to learn the tree node representations from the parsed dependency tree. Finally, we construct a neural sequence tagging model by integrating and feeding the previously pre-learned representations into a CRF layer. Extensive experiments conducted on a real-world dataset demonstrate the superiority and effectiveness of GEDIT. In addition, it has already been deployed in production at Baidu Maps. Statistics show that the proposed solution can save significant human effort and labor costs to deal with the same amount of documents, which confirms that it is a practical way for POI accessibility maintenance.