 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Table Understanding
Jun 12, 2024



Although great progress has been made by previous table understanding methods including recent approaches based on large language models (LLMs), they rely heavily on the premise that given tables must be converted into a certain text sequence (such as Markdown or HTML) to serve as model input. However, it is difficult to access such high-quality textual table representations in some real-world scenarios, and table images are much more accessible. Therefore, how to directly understand tables using intuitive visual information is a crucial and urgent challenge for developing more practical applications. In this paper, we propose a new problem, multimodal table understanding, where the model needs to generate correct responses to various table-related requests based on the given table image. To facilitate both the model training and evaluation, we construct a large-scale dataset named MMTab, which covers a wide spectrum of table images, instructions and tasks. On this basis, we develop Table-LLaVA, a generalist tabular multimodal large language model (MLLM), which significantly outperforms recent open-source MLLM baselines on 23 benchmarks under held-in and held-out settings. The code and data is available at this https://github.com/SpursGoZmy/Table-LLaVA
$k$NN Prompting: Beyond-Context Learning with Calibration-Free Nearest Neighbor Inference
Mar 24, 2023In-Context Learning (ICL), which formulates target tasks as prompt completion conditioned on in-context demonstrations, has become the prevailing utilization of LLMs. In this paper, we first disclose an actual predicament for this typical usage that it can not scale up with training data due to context length restriction. Besides, existing works have shown that ICL also suffers from various biases and requires delicate calibration treatment. To address both challenges, we advocate a simple and effective solution, $k$NN Prompting, which first queries LLM with training data for distributed representations, then predicts test instances by simply referring to nearest neighbors. We conduct comprehensive experiments to demonstrate its two-fold superiority: 1) Calibration-Free: $k$NN Prompting does not directly align LLM output distribution with task-specific label space, instead leverages such distribution to align test and training instances. It significantly outperforms state-of-the-art calibration-based methods under comparable few-shot scenario. 2) Beyond-Context: $k$NN Prompting can further scale up effectively with as many training data as are available, continually bringing substantial improvements. The scaling trend holds across 10 orders of magnitude ranging from 2 shots to 1024 shots as well as different LLMs scales ranging from 0.8B to 30B. It successfully bridges data scaling into model scaling, and brings new potentials for the gradient-free paradigm of LLM deployment. Code is publicly available.
* ICLR 2023. Code is available at https://github.com/BenfengXu/KNNPrompting
UPainting: Unified Text-to-Image Diffusion Generation with Cross-modal Guidance
Nov 03, 2022



Diffusion generative models have recently greatly improved the power of text-conditioned image generation. Existing image generation models mainly include text conditional diffusion model and cross-modal guided diffusion model, which are good at small scene image generation and complex scene image generation respectively. In this work, we propose a simple yet effective approach, namely UPainting, to unify simple and complex scene image generation, as shown in Figure 1. Based on architecture improvements and diverse guidance schedules, UPainting effectively integrates cross-modal guidance from a pretrained image-text matching model into a text conditional diffusion model that utilizes a pretrained Transformer language model as the text encoder. Our key findings is that combining the power of large-scale Transformer language model in understanding language and image-text matching model in capturing cross-modal semantics and style, is effective to improve sample fidelity and image-text alignment of image generation. In this way, UPainting has a more general image generation capability, which can generate images of both simple and complex scenes more effectively. To comprehensively compare text-to-image models, we further create a more general benchmark, UniBench, with well-written Chinese and English prompts in both simple and complex scenes. We compare UPainting with recent models and find that UPainting greatly outperforms other models in terms of caption similarity and image fidelity in both simple and complex scenes. UPainting project page \url{https://upainting.github.io/}.
Neural Knowledge Bank for Pretrained Transformers
Aug 16, 2022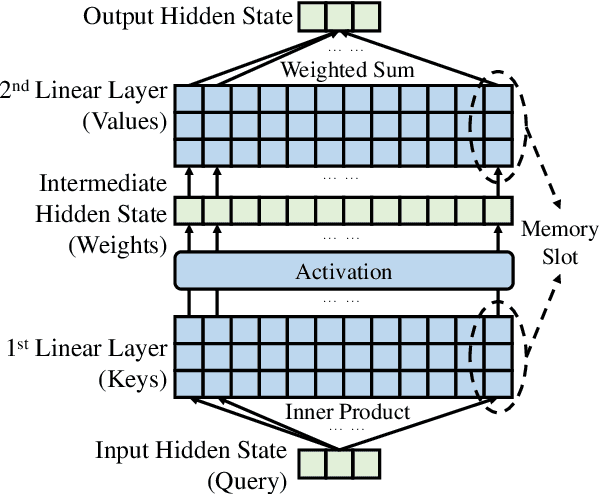
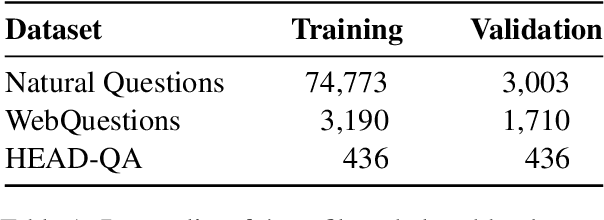
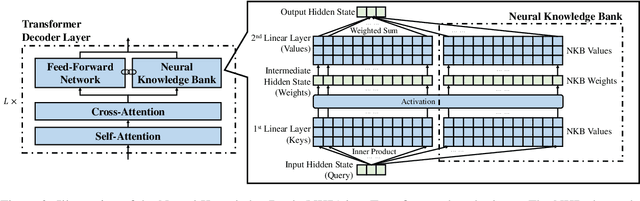
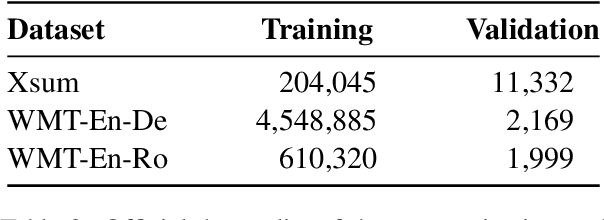
The ability of pretrained Transformers to remember factual knowledge is essential but still limited for existing models. Inspired by existing work that regards Feed-Forward Networks (FFNs) in Transformers as key-value memories, we design a Neural Knowledge Bank (NKB) and a knowledge injection strategy to introduce extra factual knowledge for pretrained Transformers. The NKB is in the form of additional knowledgeable memory slots to the FFN and the memory-like architecture makes it highly interpretable and flexible. When injecting extra knowledge with the Salient Span Masking (SSM) pretraining objective, we fix the original pretrained model and train only the NKB. This training strategy makes sure the general language modeling ability of the original pretrained model is not influenced. By mounting the NKB onto the T5 model, we verify its strong ability to store extra factual knowledge based on three closed-book question answering datasets. Also, we prove that mounting the NKB will not degrade the general language modeling ability of T5 through two representative tasks, summarization and machine translation. Further, we thoroughly analyze the interpretability of the NKB and reveal the meaning of its keys and values in a human-readable way. Finally, we show the flexibility of the NKB by directly modifying its value vectors to update the factual knowledge stored in it.
DuReader_retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine
Mar 19, 2022
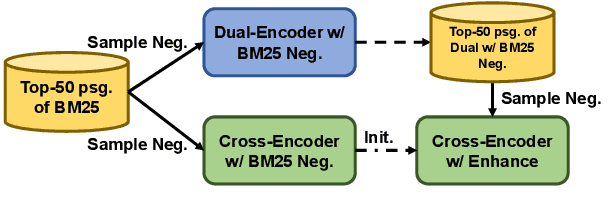
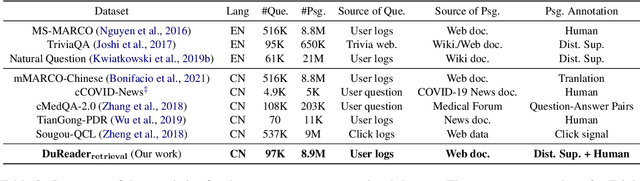
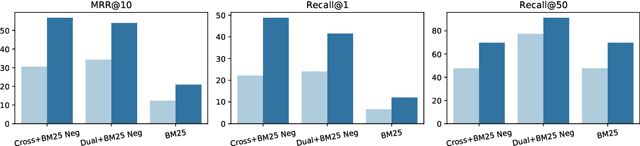
In this paper, we present DuReader_retrieval, a large-scale Chinese dataset for passage retrieval. DuReader_retrieval contains more than 90K queries and over 8M unique passages from Baidu search. To ensure the quality of our benchmark and address the shortcomings in other existing datasets, we (1) reduce the false negatives in development and testing sets by pooling the results from multiple retrievers with human annotations, (2) and remove the semantically similar questions between training with development and testing sets. We further introduce two extra out-of-domain testing sets for benchmarking the domain generalization capability. Our experiment results demonstrate that DuReader_retrieval is challenging and there is still plenty of room for the community to improve, e.g. the generalization across domains, salient phrase and syntax mismatch between query and paragraph and robustness. DuReader_retrieval will be publicly available at https://github.com/baidu/DuReader/tree/master/DuReader-Retrieval
RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking
Oct 14, 2021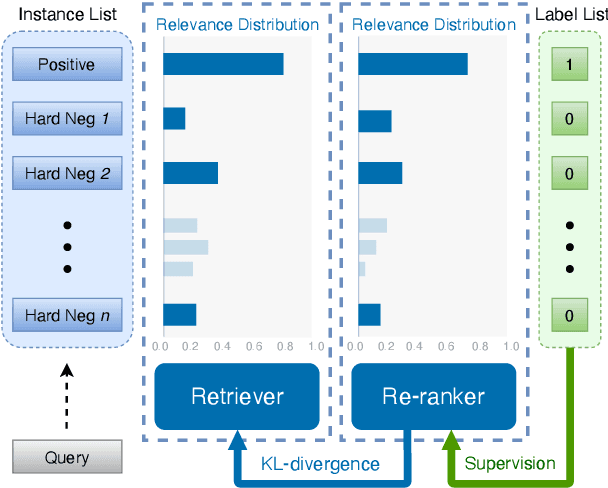

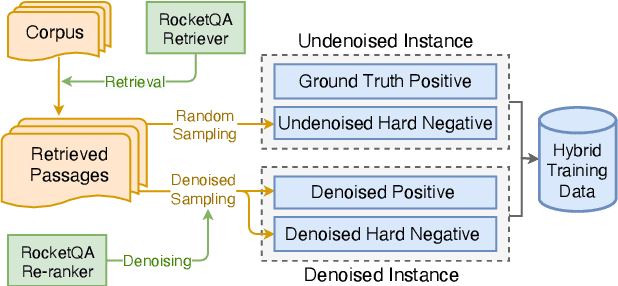
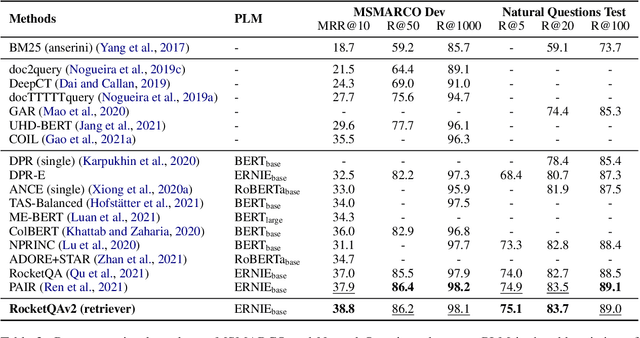
In various natural language processing tasks, passage retrieval and passage re-ranking are two key procedures in finding and ranking relevant information. Since both the two procedures contribute to the final performance, it is important to jointly optimize them in order to achieve mutual improvement. In this paper, we propose a novel joint training approach for dense passage retrieval and passage re-ranking. A major contribution is that we introduce the dynamic listwise distillation, where we design a unified listwise training approach for both the retriever and the re-ranker. During the dynamic distillation, the retriever and the re-ranker can be adaptively improved according to each other's relevance information. We also propose a hybrid data augmentation strategy to construct diverse training instances for listwise training approach. Extensive experiments show the effectiveness of our approach on both MSMARCO and Natural Questions datasets. Our code is available at https://github.com/PaddlePaddle/RocketQA.
DuReader: a Chinese Machine Reading Comprehension Dataset from Real-world Applications
Jun 11, 2018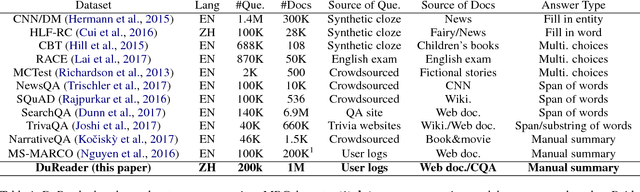
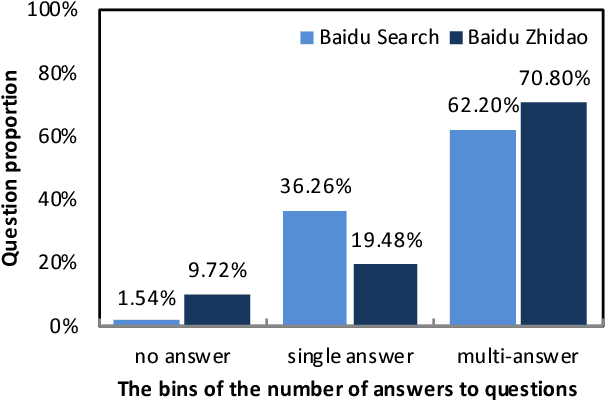

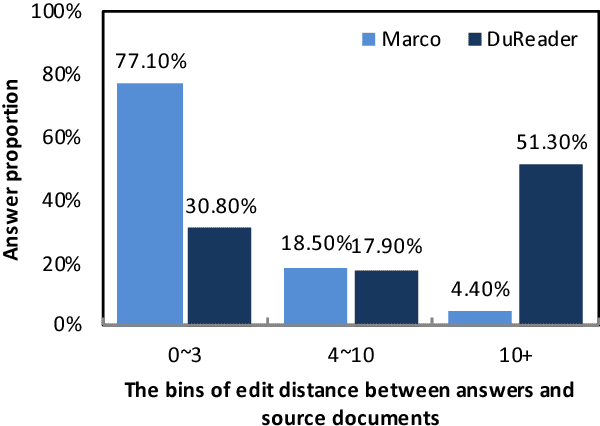
This paper introduces DuReader, a new large-scale, open-domain Chinese ma- chine reading comprehension (MRC) dataset, designed to address real-world MRC. DuReader has three advantages over previous MRC datasets: (1) data sources: questions and documents are based on Baidu Search and Baidu Zhidao; answers are manually generated. (2) question types: it provides rich annotations for more question types, especially yes-no and opinion questions, that leaves more opportunity for the research community. (3) scale: it contains 200K questions, 420K answers and 1M documents; it is the largest Chinese MRC dataset so far. Experiments show that human performance is well above current state-of-the-art baseline systems, leaving plenty of room for the community to make improvements. To help the community make these improvements, both DuReader and baseline systems have been posted online. We also organize a shared competition to encourage the exploration of more models. Since the release of the task, there are significant improvements over the baselines.