 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRice Diseases Detection and Classification Using Attention Based Neural Network and Bayesian Optimization
Jan 03, 2022
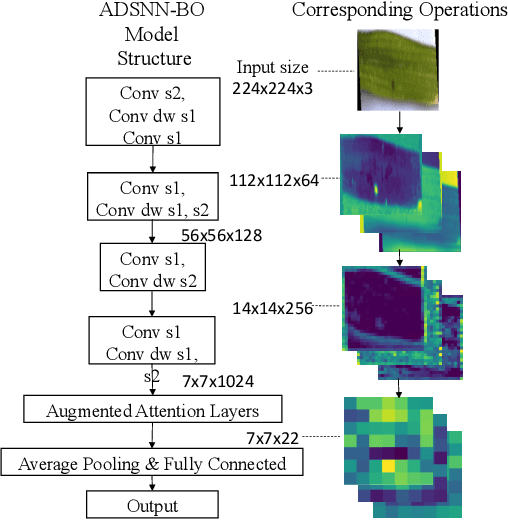
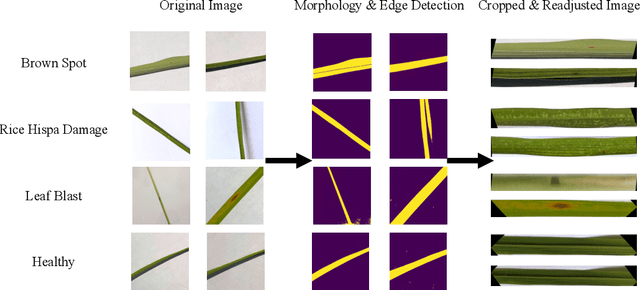

In this research, an attention-based depthwise separable neural network with Bayesian optimization (ADSNN-BO) is proposed to detect and classify rice disease from rice leaf images. Rice diseases frequently result in 20 to 40 \% corp production loss in yield and is highly related to the global economy. Rapid disease identification is critical to plan treatment promptly and reduce the corp losses. Rice disease diagnosis is still mainly performed manually. To achieve AI assisted rapid and accurate disease detection, we proposed the ADSNN-BO model based on MobileNet structure and augmented attention mechanism. Moreover, Bayesian optimization method is applied to tune hyper-parameters of the model. Cross-validated classification experiments are conducted based on a public rice disease dataset with four categories in total. The experimental results demonstrate that our mobile compatible ADSNN-BO model achieves a test accuracy of 94.65\%, which outperforms all of the state-of-the-art models tested. To check the interpretability of our proposed model, feature analysis including activation map and filters visualization approach are also conducted. Results show that our proposed attention-based mechanism can more effectively guide the ADSNN-BO model to learn informative features. The outcome of this research will promote the implementation of artificial intelligence for fast plant disease diagnosis and control in the agricultural field.
ERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation
Dec 31, 2021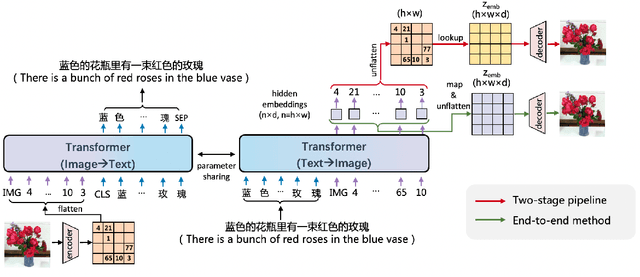
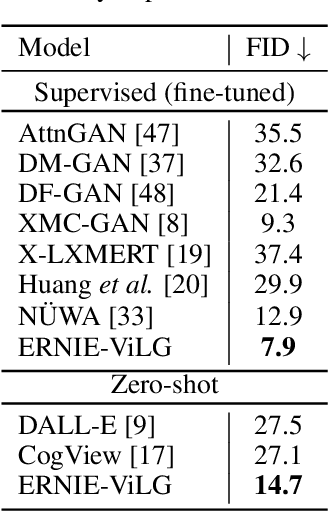
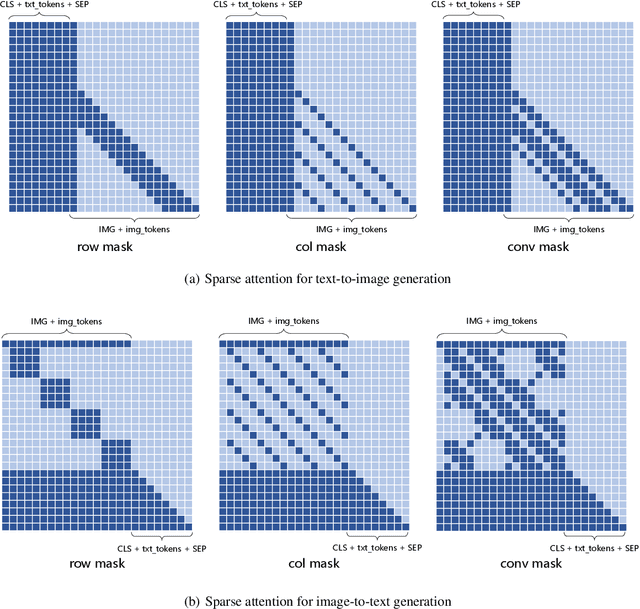

Conventional methods for the image-text generation tasks mainly tackle the naturally bidirectional generation tasks separately, focusing on designing task-specific frameworks to improve the quality and fidelity of the generated samples. Recently, Vision-Language Pre-training models have greatly improved the performance of the image-to-text generation tasks, but large-scale pre-training models for text-to-image synthesis task are still under-developed. In this paper, we propose ERNIE-ViLG, a unified generative pre-training framework for bidirectional image-text generation with transformer model. Based on the image quantization models, we formulate both image generation and text generation as autoregressive generative tasks conditioned on the text/image input. The bidirectional image-text generative modeling eases the semantic alignments across vision and language. For the text-to-image generation process, we further propose an end-to-end training method to jointly learn the visual sequence generator and the image reconstructor. To explore the landscape of large-scale pre-training for bidirectional text-image generation, we train a 10-billion parameter ERNIE-ViLG model on a large-scale dataset of 145 million (Chinese) image-text pairs which achieves state-of-the-art performance for both text-to-image and image-to-text tasks, obtaining an FID of 7.9 on MS-COCO for text-to-image synthesis and best results on COCO-CN and AIC-ICC for image captioning.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021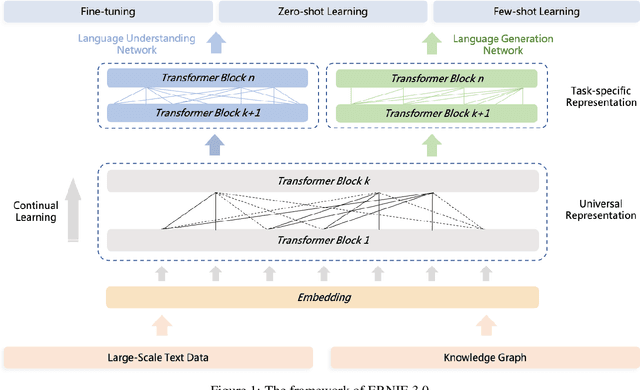
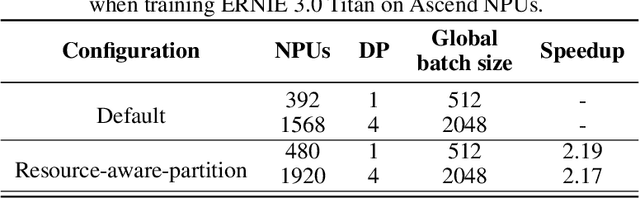
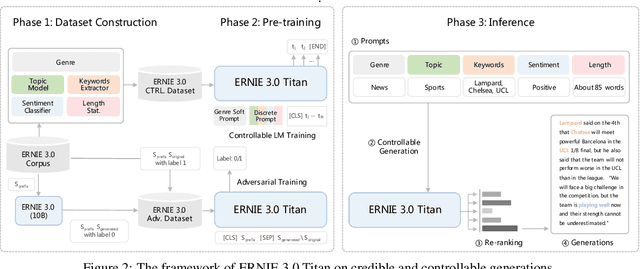
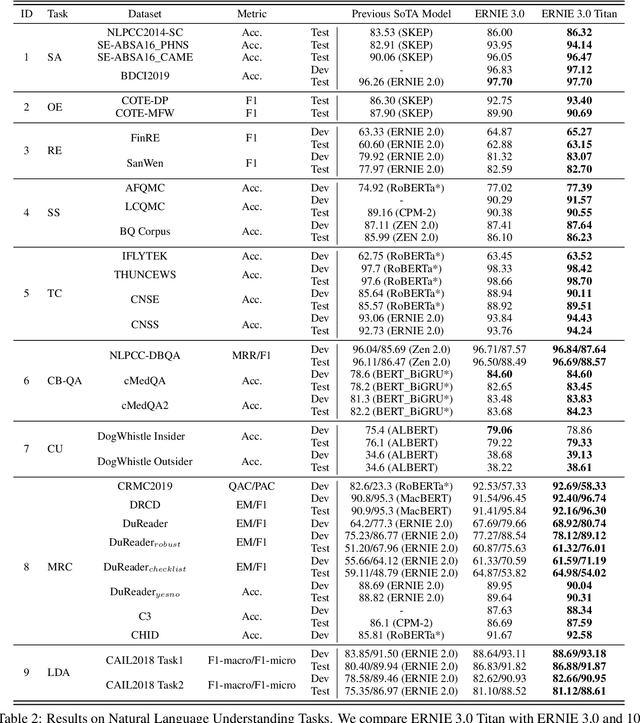
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.
TOD-DA: Towards Boosting the Robustness of Task-oriented Dialogue Modeling on Spoken Conversations
Dec 23, 2021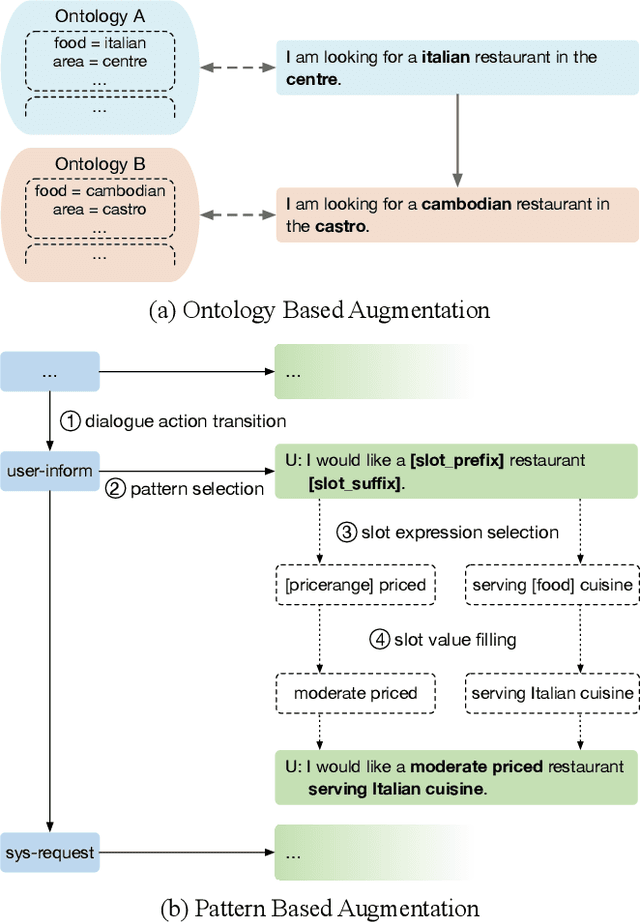
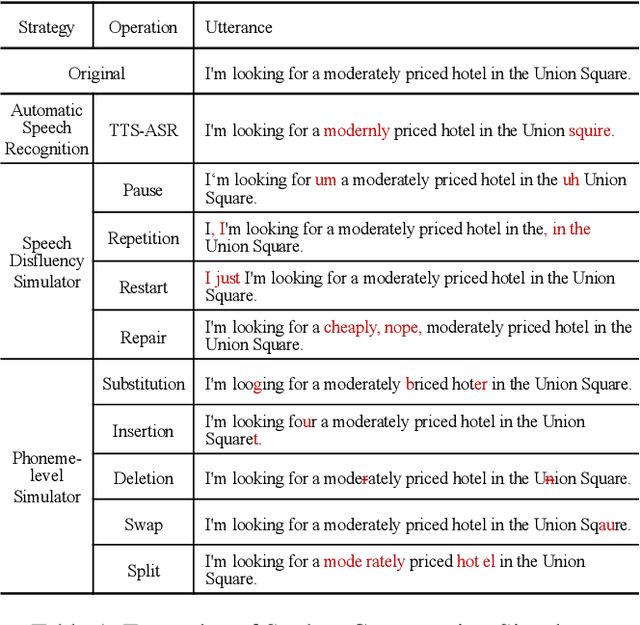
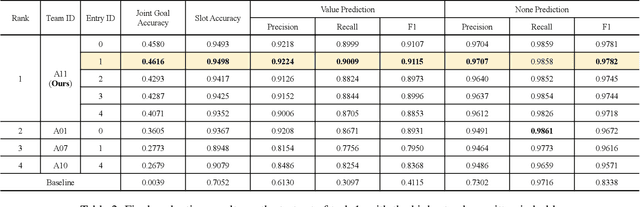
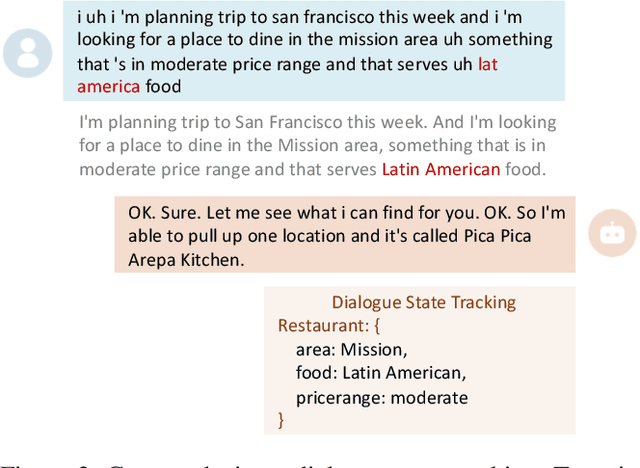
Task-oriented dialogue systems have been plagued by the difficulties of obtaining large-scale and high-quality annotated conversations. Furthermore, most of the publicly available datasets only include written conversations, which are insufficient to reflect actual human behaviors in practical spoken dialogue systems. In this paper, we propose Task-oriented Dialogue Data Augmentation (TOD-DA), a novel model-agnostic data augmentation paradigm to boost the robustness of task-oriented dialogue modeling on spoken conversations. The TOD-DA consists of two modules: 1) Dialogue Enrichment to expand training data on task-oriented conversations for easing data sparsity and 2) Spoken Conversation Simulator to imitate oral style expressions and speech recognition errors in diverse granularities for bridging the gap between written and spoken conversations. With such designs, our approach ranked first in both tasks of DSTC10 Track2, a benchmark for task-oriented dialogue modeling on spoken conversations, demonstrating the superiority and effectiveness of our proposed TOD-DA.
Equilibrated Zeroth-Order Unrolled Deep Networks for Accelerated MRI
Dec 23, 2021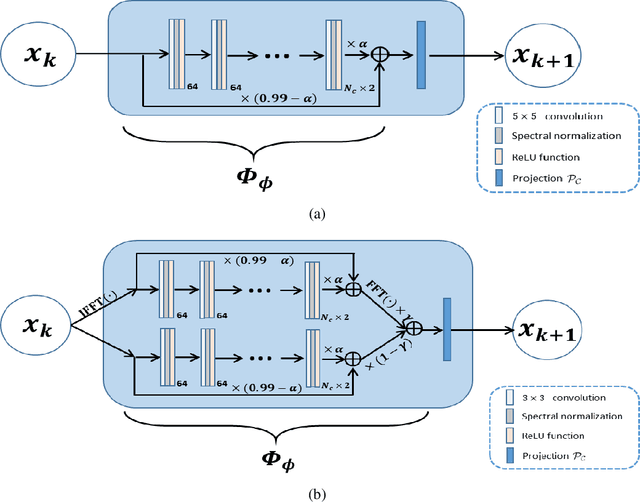
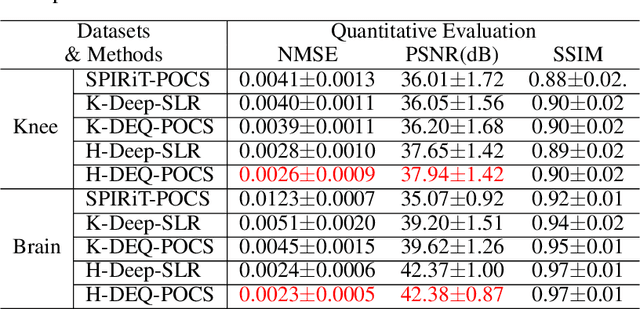

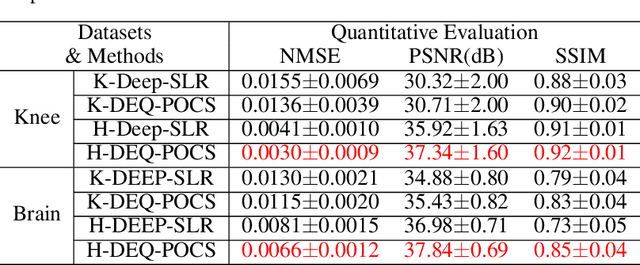
Recently, model-driven deep learning unrolls a certain iterative algorithm of a regularization model into a cascade network by replacing the first-order information (i.e., (sub)gradient or proximal operator) of the regularizer with a network module, which appears more explainable and predictable compared to common data-driven networks. Conversely, in theory, there is not necessarily such a functional regularizer whose first-order information matches the replaced network module, which means the network output may not be covered by the original regularization model. Moreover, up to now, there is also no theory to guarantee the global convergence and robustness (regularity) of unrolled networks under realistic assumptions. To bridge this gap, this paper propose to present a safeguarded methodology on network unrolling. Specifically, focusing on accelerated MRI, we unroll a zeroth-order algorithm, of which the network module represents the regularizer itself, so that the network output can be still covered by the regularization model. Furthermore, inspired by the ideal of deep equilibrium models, before backpropagating, we carry out the unrolled iterative network to converge to a fixed point to ensure the convergence. In case the measurement data contains noise, we prove that the proposed network is robust against noisy interference. Finally, numerical experiments show that the proposed network consistently outperforms the state-of-the-art MRI reconstruction methods including traditional regularization methods and other deep learning methods.
DuQM: A Chinese Dataset of Linguistically Perturbed Natural Questions for Evaluating the Robustness of Question Matching Models
Dec 16, 2021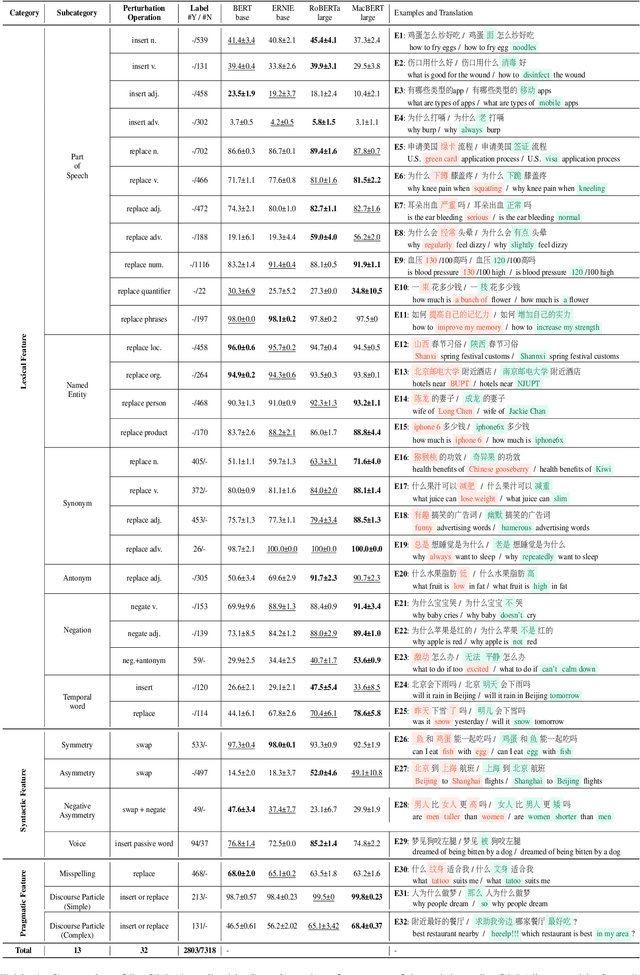
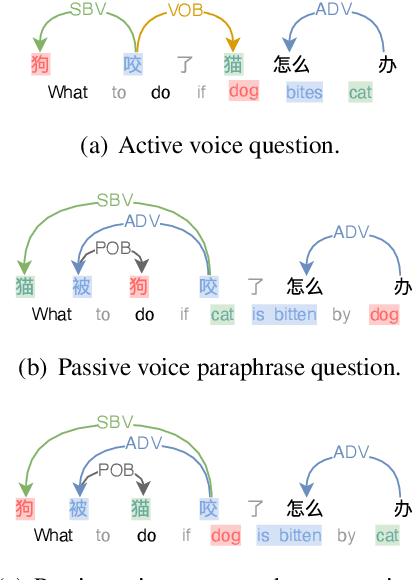
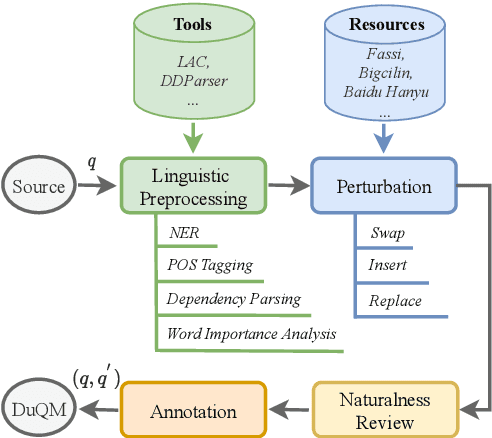
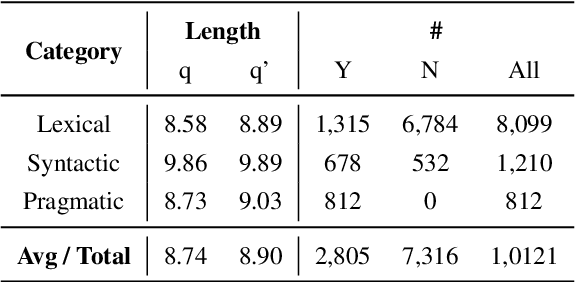
In this paper, we focus on studying robustness evaluation of Chinese question matching. Most of the previous work on analyzing robustness issue focus on just one or a few types of artificial adversarial examples. Instead, we argue that it is necessary to formulate a comprehensive evaluation about the linguistic capabilities of models on natural texts. For this purpose, we create a Chinese dataset namely DuQM which contains natural questions with linguistic perturbations to evaluate the robustness of question matching models. DuQM contains 3 categories and 13 subcategories with 32 linguistic perturbations. The extensive experiments demonstrate that DuQM has a better ability to distinguish different models. Importantly, the detailed breakdown of evaluation by linguistic phenomenon in DuQM helps us easily diagnose the strength and weakness of different models. Additionally, our experiment results show that the effect of artificial adversarial examples does not work on the natural texts.
End-to-end Adaptive Distributed Training on PaddlePaddle
Dec 06, 2021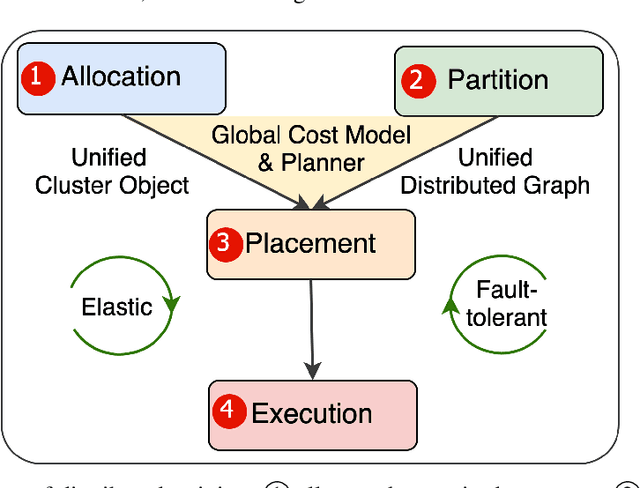
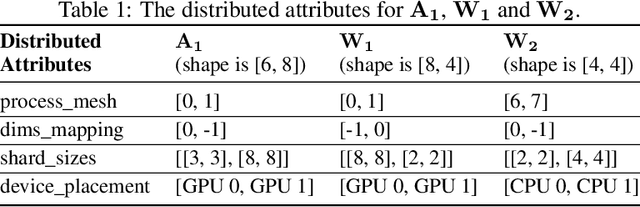
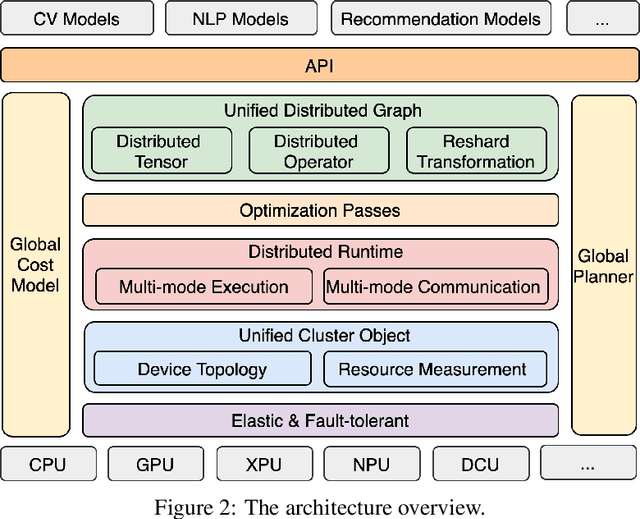
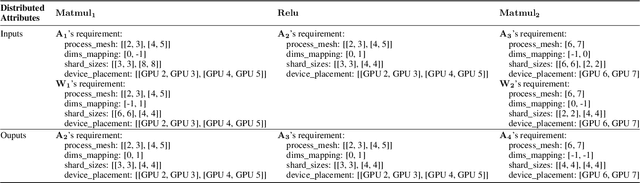
Distributed training has become a pervasive and effective approach for training a large neural network (NN) model with processing massive data. However, it is very challenging to satisfy requirements from various NN models, diverse computing resources, and their dynamic changes during a training job. In this study, we design our distributed training framework in a systematic end-to-end view to provide the built-in adaptive ability for different scenarios, especially for industrial applications and production environments, by fully considering resource allocation, model partition, task placement, and distributed execution. Based on the unified distributed graph and the unified cluster object, our adaptive framework is equipped with a global cost model and a global planner, which can enable arbitrary parallelism, resource-aware placement, multi-mode execution, fault-tolerant, and elastic distributed training. The experiments demonstrate that our framework can satisfy various requirements from the diversity of applications and the heterogeneity of resources with highly competitive performance. The ERNIE language model with 260 billion parameters is efficiently trained on thousands of AI processors with 91.7% weak scalability. The throughput of the model from the recommender system by employing the heterogeneous pipeline asynchronous execution can be increased up to 2.1 times and 3.3 times that of the GPU-only and CPU-only training respectively. Moreover, the fault-tolerant and elastic distributed training have been successfully applied to the online industrial applications, which give a reduction of 34.49% in the number of failed long-term training jobs and an increase of 33.91% for the global scheduling efficiency in the production environment.
CELLS: Cost-Effective Evolution in Latent Space for Goal-Directed Molecular Generation
Dec 05, 2021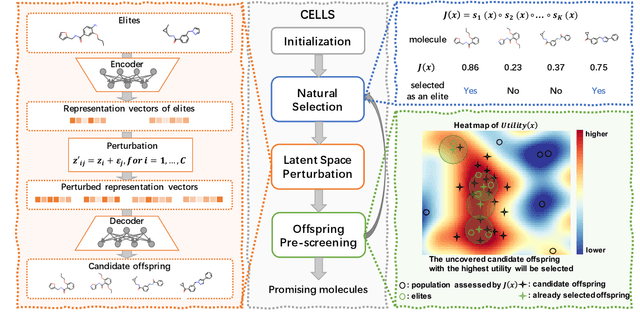
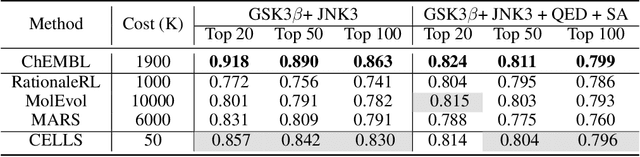
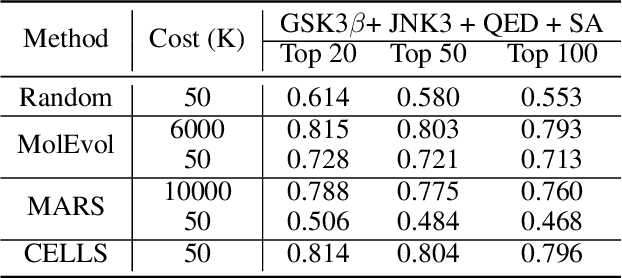
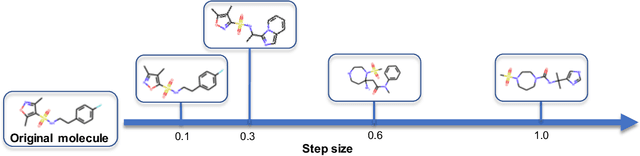
Efficiently discovering molecules that meet various property requirements can significantly benefit the drug discovery industry. Since it is infeasible to search over the entire chemical space, recent works adopt generative models for goal-directed molecular generation. They tend to utilize the iterative processes, optimizing the parameters of the molecular generative models at each iteration to produce promising molecules for further validation. Assessments are exploited to evaluate the generated molecules at each iteration, providing direction for model optimization. However, most previous works require a massive number of expensive and time-consuming assessments, e.g., wet experiments and molecular dynamic simulations, leading to the lack of practicability. To reduce the assessments in the iterative process, we propose a cost-effective evolution strategy in latent space, which optimizes the molecular latent representation vectors instead. We adopt a pre-trained molecular generative model to map the latent and observation spaces, taking advantage of the large-scale unlabeled molecules to learn chemical knowledge. To further reduce the number of expensive assessments, we introduce a pre-screener as the proxy to the assessments. We conduct extensive experiments on multiple optimization tasks comparing the proposed framework to several advanced techniques, showing that the proposed framework achieves better performance with fewer assessments.
Highly accelerated MR parametric mapping by undersampling the k-space and reducing the contrast number simultaneously with deep learning
Dec 01, 2021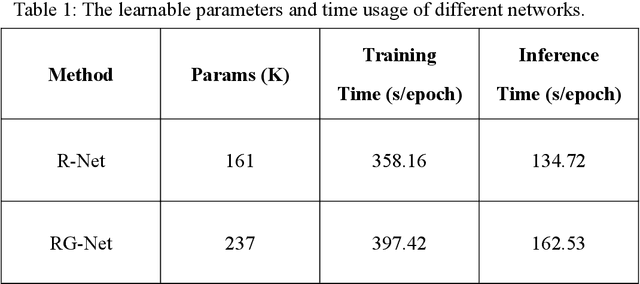
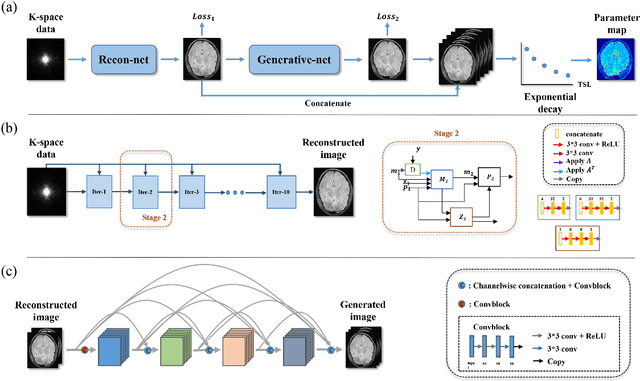
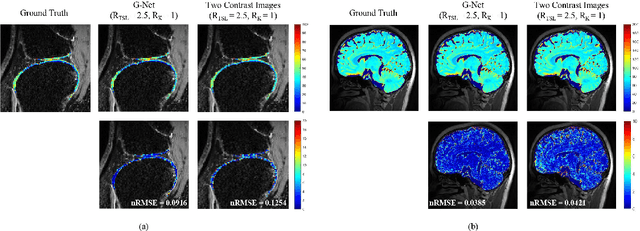
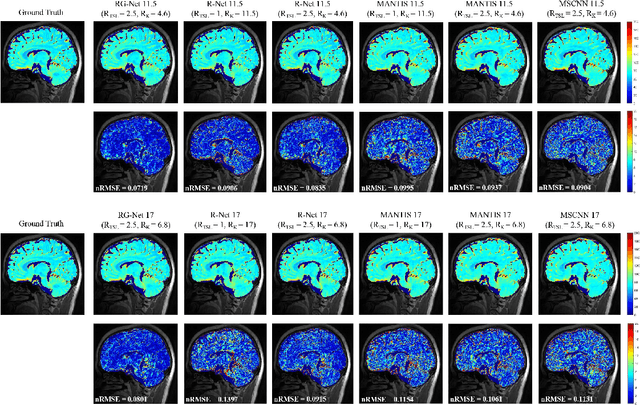
Purpose: To propose a novel deep learning-based method called RG-Net (reconstruction and generation network) for highly accelerated MR parametric mapping by undersampling k-space and reducing the acquired contrast number simultaneously. Methods: The proposed framework consists of a reconstruction module and a generative module. The reconstruction module reconstructs MR images from the acquired few undersampled k-space data with the help of a data prior. The generative module then synthesizes the remaining multi-contrast images from the reconstructed images, where the exponential model is implicitly incorporated into the image generation through the supervision of fully sampled labels. The RG-Net was evaluated on the T1\r{ho} mapping data of knee and brain at different acceleration rates. Regional T1\r{ho} analysis for cartilage and the brain was performed to access the performance of RG-Net. Results: RG-Net yields a high-quality T1\r{ho} map at a high acceleration rate of 17. Compared with the competing methods that only undersample k-space, our framework achieves better performance in T1\r{ho} value analysis. Our method also improves quality of T1\r{ho} maps on patient with glioma. Conclusion: The proposed RG-Net that adopted a new strategy by undersampling k-space and reducing the contrast number simultaneously for fast MR parametric mapping, can achieve a high acceleration rate while maintaining good reconstruction quality. The generative module of our framework can also be used as an insert module in other fast MR parametric mapping methods. Keywords: Deep learning, convolutional neural network, fast MR parametric mapping
Docking-based Virtual Screening with Multi-Task Learning
Nov 18, 2021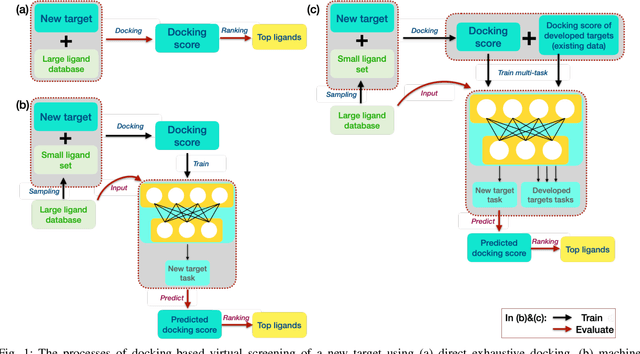
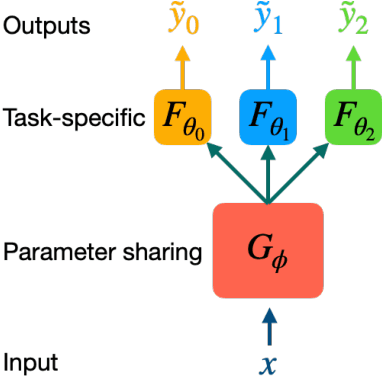
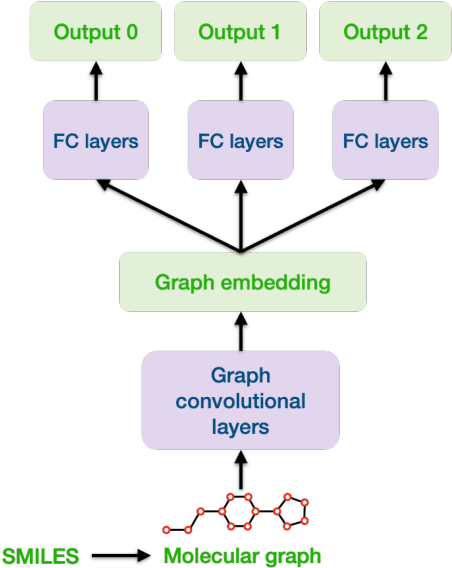
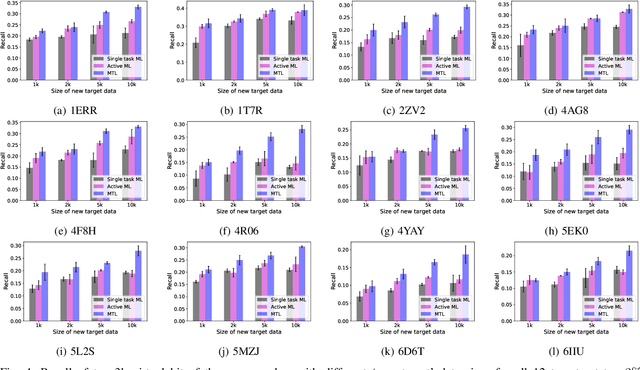
Machine learning shows great potential in virtual screening for drug discovery. Current efforts on accelerating docking-based virtual screening do not consider using existing data of other previously developed targets. To make use of the knowledge of the other targets and take advantage of the existing data, in this work, we apply multi-task learning to the problem of docking-based virtual screening. With two large docking datasets, the results of extensive experiments show that multi-task learning can achieve better performances on docking score prediction. By learning knowledge across multiple targets, the model trained by multi-task learning shows a better ability to adapt to a new target. Additional empirical study shows that other problems in drug discovery, such as the experimental drug-target affinity prediction, may also benefit from multi-task learning. Our results demonstrate that multi-task learning is a promising machine learning approach for docking-based virtual screening and accelerating the process of drug discovery.