 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
AcademicGPT: Empowering Academic Research
Nov 21, 2023



Large Language Models (LLMs) have demonstrated exceptional capabilities across various natural language processing tasks. Yet, many of these advanced LLMs are tailored for broad, general-purpose applications. In this technical report, we introduce AcademicGPT, designed specifically to empower academic research. AcademicGPT is a continual training model derived from LLaMA2-70B. Our training corpus mainly consists of academic papers, thesis, content from some academic domain, high-quality Chinese data and others. While it may not be extensive in data scale, AcademicGPT marks our initial venture into a domain-specific GPT tailored for research area. We evaluate AcademicGPT on several established public benchmarks such as MMLU and CEval, as well as on some specialized academic benchmarks like PubMedQA, SCIEval, and our newly-created ComputerScienceQA, to demonstrate its ability from general knowledge ability, to Chinese ability, and to academic ability. Building upon AcademicGPT's foundation model, we also developed several applications catered to the academic area, including General Academic Question Answering, AI-assisted Paper Reading, Paper Review, and AI-assisted Title and Abstract Generation.
TOD-DA: Towards Boosting the Robustness of Task-oriented Dialogue Modeling on Spoken Conversations
Dec 23, 2021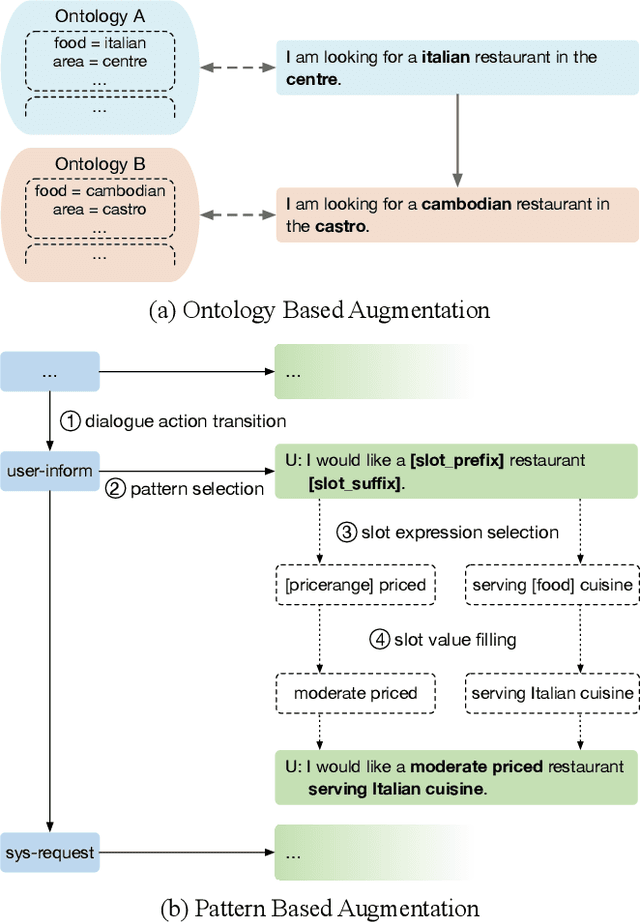
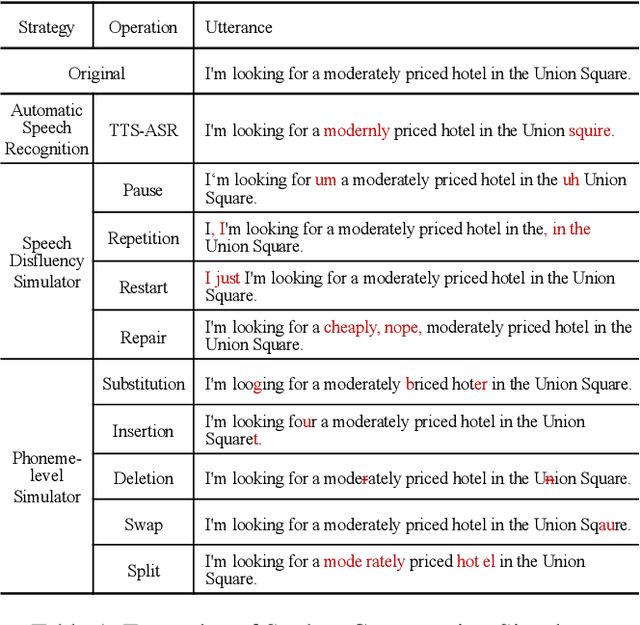
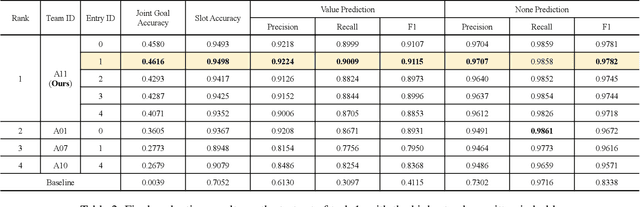
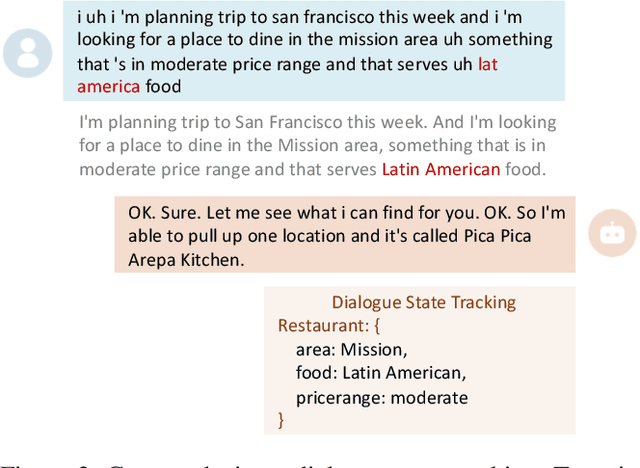
Task-oriented dialogue systems have been plagued by the difficulties of obtaining large-scale and high-quality annotated conversations. Furthermore, most of the publicly available datasets only include written conversations, which are insufficient to reflect actual human behaviors in practical spoken dialogue systems. In this paper, we propose Task-oriented Dialogue Data Augmentation (TOD-DA), a novel model-agnostic data augmentation paradigm to boost the robustness of task-oriented dialogue modeling on spoken conversations. The TOD-DA consists of two modules: 1) Dialogue Enrichment to expand training data on task-oriented conversations for easing data sparsity and 2) Spoken Conversation Simulator to imitate oral style expressions and speech recognition errors in diverse granularities for bridging the gap between written and spoken conversations. With such designs, our approach ranked first in both tasks of DSTC10 Track2, a benchmark for task-oriented dialogue modeling on spoken conversations, demonstrating the superiority and effectiveness of our proposed TOD-DA.
Amendable Generation for Dialogue State Tracking
Oct 29, 2021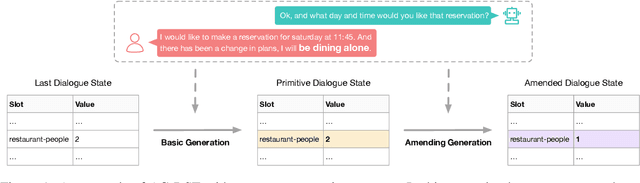
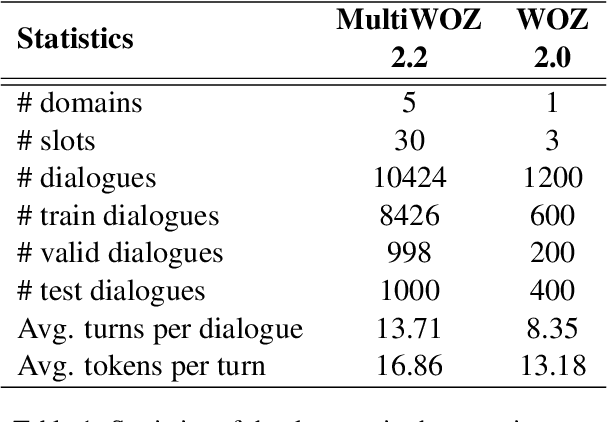
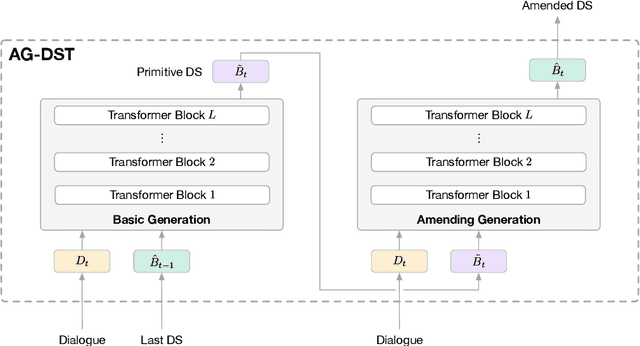
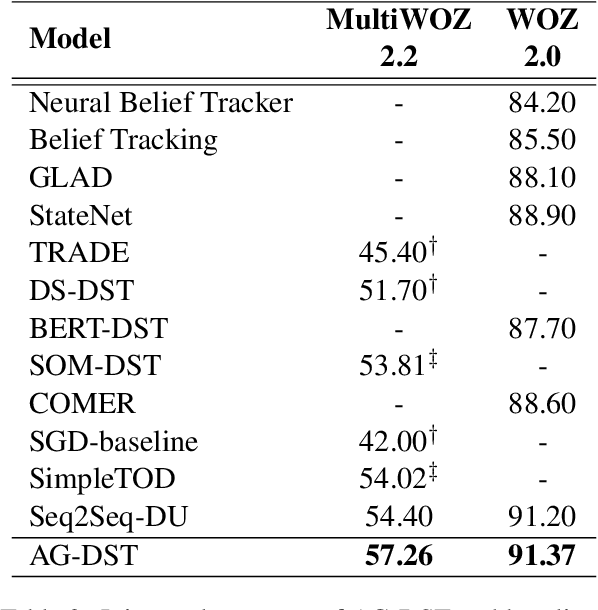
In task-oriented dialogue systems, recent dialogue state tracking methods tend to perform one-pass generation of the dialogue state based on the previous dialogue state. The mistakes of these models made at the current turn are prone to be carried over to the next turn, causing error propagation. In this paper, we propose a novel Amendable Generation for Dialogue State Tracking (AG-DST), which contains a two-pass generation process: (1) generating a primitive dialogue state based on the dialogue of the current turn and the previous dialogue state, and (2) amending the primitive dialogue state from the first pass. With the additional amending generation pass, our model is tasked to learn more robust dialogue state tracking by amending the errors that still exist in the primitive dialogue state, which plays the role of reviser in the double-checking process and alleviates unnecessary error propagation. Experimental results show that AG-DST significantly outperforms previous works in two active DST datasets (MultiWOZ 2.2 and WOZ 2.0), achieving new state-of-the-art performances.