 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatchLM2Lite: A Scalable MLLM-to-Lite Framework for Reproduced Content Identification
Jun 10, 2026Content moderation is critical for online video platforms to ensure content safety, protect creators, and sustain positive user experiences. Beyond filtering harmful content, platforms must guarantee content authenticity at scale so that users are exposed to diverse, original videos rather than low-value reproductions. We present MatchLM2Lite, a real-time, production-grade reproduced content identification (RCI) system that leverages the powerful understanding of a multimodal large language model (MLLM) distilled into a small and fast-inference model. Our system jointly models video, audio, and text signals, operating on pairs of videos to produce fine-grained reproduction scores. The system comprises two modules, MatchLM and MatchLite, and a two-stage training recipe. First, our high-capacity MLLM, MatchLM, serves as a teacher model to define the upper bound of RCI performance. Its capabilities are then distilled into a compact student model, MatchLite. This design allows MatchLite to deliver low-latency, high-throughput inference on video pairs while preserving much of MatchLM's accuracy, making it suitable for integration into real-time recommendation systems. MatchLM achieves an F1-score improvement of +8.57 compared to our previous production model. After knowledge distillation, MatchLite retains a +6.55 gain in F1-score while reducing computational cost by 35x. Deployed at scale, MatchLM2Lite enables efficient, pairwise multimodal RCI, stably serving online traffic at high queries per second (QPS) with an end-to-end latency below 30 seconds. This system has reduced the reproduced video view rate on our platform by 2.5% without degrading user engagement, demonstrating its effectiveness in a large-scale production environment.
Improving Channel Estimation via Multimodal Diffusion Models with Flow Matching
Mar 13, 2026Deep generative models offer a powerful alternative to conventional channel estimation by learning complex channel distributions. By integrating the rich environmental information available in modern sensing-aided networks, this paper proposes MultiCE-Flow, a multimodal channel estimation framework based on flow matching and diffusion transformer (DiT). We design a specialized multimodal perception module that fuses LiDAR, camera, and location data into a semantic condition, while treating sparse pilots as a structural condition. These conditions guide a DiT backbone to reconstruct high-fidelity channels. Unlike standard diffusion models, we employ flow matching to learn a linear trajectory from noise to data, enabling efficient one-step sampling. By leveraging environmental semantics, our method mitigates the ill-posed nature of estimation with sparse pilots. Extensive experiments demonstrate that MultiCE-Flow consistently outperforms traditional baselines and existing generative models. Notably, it exhibits superior robustness to out-of-distribution scenarios and varying pilot densities, making it suitable for environment-aware communication systems.
CELLS: Cost-Effective Evolution in Latent Space for Goal-Directed Molecular Generation
Dec 05, 2021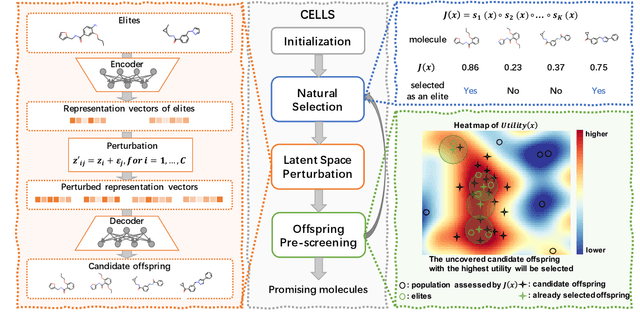
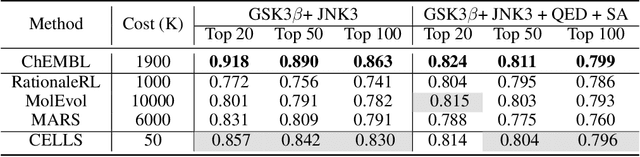
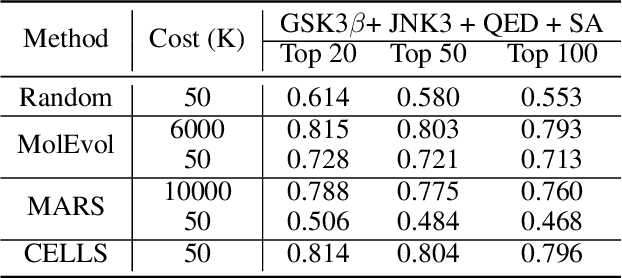
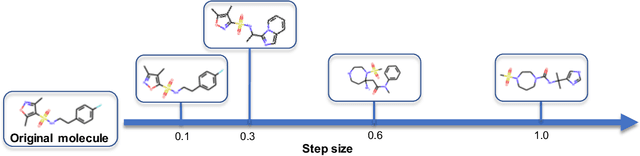
Efficiently discovering molecules that meet various property requirements can significantly benefit the drug discovery industry. Since it is infeasible to search over the entire chemical space, recent works adopt generative models for goal-directed molecular generation. They tend to utilize the iterative processes, optimizing the parameters of the molecular generative models at each iteration to produce promising molecules for further validation. Assessments are exploited to evaluate the generated molecules at each iteration, providing direction for model optimization. However, most previous works require a massive number of expensive and time-consuming assessments, e.g., wet experiments and molecular dynamic simulations, leading to the lack of practicability. To reduce the assessments in the iterative process, we propose a cost-effective evolution strategy in latent space, which optimizes the molecular latent representation vectors instead. We adopt a pre-trained molecular generative model to map the latent and observation spaces, taking advantage of the large-scale unlabeled molecules to learn chemical knowledge. To further reduce the number of expensive assessments, we introduce a pre-screener as the proxy to the assessments. We conduct extensive experiments on multiple optimization tasks comparing the proposed framework to several advanced techniques, showing that the proposed framework achieves better performance with fewer assessments.