 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Mitigate Psychological Sycophancy in Medical Vision-Language Models
Sep 26, 2025Vision language models(VLMs) are increasingly integrated into clinical workflows, but they often exhibit sycophantic behavior prioritizing alignment with user phrasing social cues or perceived authority over evidence based reasoning. This study evaluate clinical sycophancy in medical visual question answering through a novel clinically grounded benchmark. We propose a medical sycophancy dataset construct from PathVQA, SLAKE, and VQA-RAD stratified by different type organ system and modality. Using psychologically motivated pressure templates including various sycophancy. In our adversarial experiments on various VLMs, we found that these models are generally vulnerable, exhibiting significant variations in the occurrence of adversarial responses, with weak correlations to the model accuracy or size. Imitation and expert provided corrections were found to be the most effective triggers, suggesting that the models possess a bias mechanism independent of visual evidence. To address this, we propose Visual Information Purification for Evidence based Response (VIPER) a lightweight mitigation strategy that filters non evidentiary content for example social pressures and then generates constrained evidence first answers. This framework reduces sycophancy by an average amount outperforming baselines while maintaining interpretability. Our benchmark analysis and mitigation framework lay the groundwork for robust deployment of medical VLMs in real world clinician interactions emphasizing the need for evidence anchored defenses.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
D-LEAF: Localizing and Correcting Hallucinations in Multimodal LLMs via Layer-to-head Attention Diagnostics
Sep 09, 2025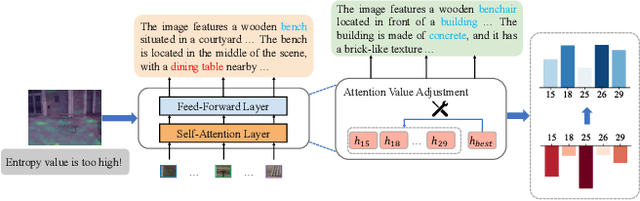

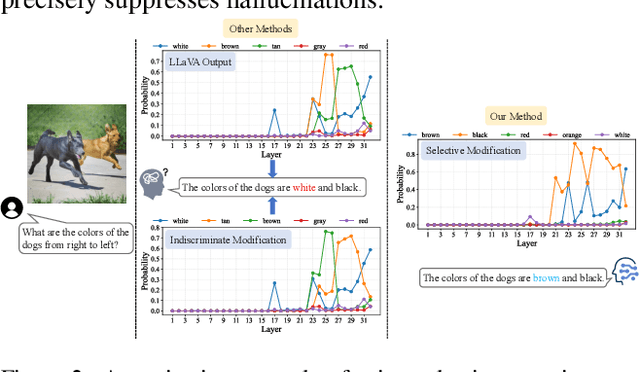
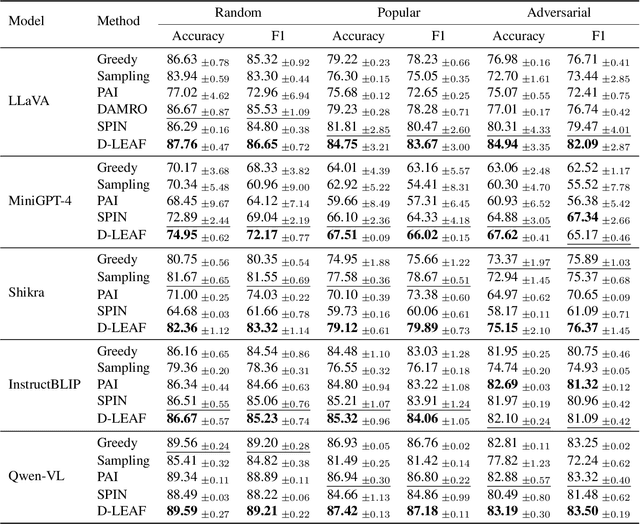
Multimodal Large Language Models (MLLMs) achieve strong performance on tasks like image captioning and visual question answering, but remain prone to hallucinations, where generated text conflicts with the visual input. Prior work links this partly to insufficient visual attention, but existing attention-based detectors and mitigation typically apply uniform adjustments across layers and heads, obscuring where errors originate. In this paper, we first show these methods fail to accurately localize problematic layers. Then, we introduce two diagnostics: Layer Image Attention Entropy (LIAE) which flags anomalous layers, and Image Attention Focus (IAF) which scores attention heads within those layers. Analysis shows that LIAE pinpoints faulty layers and IAF reliably ranks heads that warrant correction. Guided by these signals, we propose Dynamic Layer-wise Entropy and Attention Fusion (D-LEAF), a task-agnostic, attention-guided method that dynamically localizes and corrects errors during inference with negligible overhead. Results show our D-LEAF delivers a 53% relative improvement on standard captioning benchmarks, and on VQA both accuracy and F1-score improve by approximately 4%, substantially suppressing hallucinations while preserving efficiency.
Hunyuan-MT Technical Report
Sep 05, 2025In this report, we introduce Hunyuan-MT-7B, our first open-source multilingual translation model, which supports bidirectional translation across 33 major languages and places a special emphasis on translation between Mandarin and several ethnic minority languages as well as dialects. Furthermore, to serve and address diverse translation scenarios and enhance model performance at test time, we introduce Hunyuan-MT-Chimera-7B, a translation model inspired by the slow thinking mode. This model integrates multiple outputs generated by the Hunyuan-MT-7B model under varying parameter settings, thereby achieving performance superior to that of conventional slow-thinking models based on Chain-of-Thought (CoT). The development of our models follows a holistic training process specifically engineered for multilingual translation, which begins with general and MT-oriented pre-training to build foundational capabilities, proceeds to Supervised Fine-Tuning (SFT) for task-specific adaptation, and culminates in advanced alignment through Reinforcement Learning (RL) and weak-to-strong RL. Through comprehensive experimentation, we demonstrate that both Hunyuan-MT-7B and Hunyuan-MT-Chimera-7B significantly outperform all translation-specific models of comparable parameter size and most of the SOTA large models, particularly on the task of translation between Mandarin and minority languages as well as dialects. In the WMT2025 shared task (General Machine Translation), our models demonstrate state-of-the-art performance, ranking first in 30 out of 31 language pairs. This result highlights the robustness of our models across a diverse linguistic spectrum, encompassing high-resource languages such as Chinese, English, and Japanese, as well as low-resource languages including Czech, Marathi, Estonian, and Icelandic.
Beyond Ordinary Lipschitz Constraints: Differentially Private Stochastic Optimization with Tsybakov Noise Condition
Sep 04, 2025



We study Stochastic Convex Optimization in the Differential Privacy model (DP-SCO). Unlike previous studies, here we assume the population risk function satisfies the Tsybakov Noise Condition (TNC) with some parameter $\theta>1$, where the Lipschitz constant of the loss could be extremely large or even unbounded, but the $\ell_2$-norm gradient of the loss has bounded $k$-th moment with $k\geq 2$. For the Lipschitz case with $\theta\geq 2$, we first propose an $(\varepsilon, \delta)$-DP algorithm whose utility bound is $\Tilde{O}\left(\left(\tilde{r}_{2k}(\frac{1}{\sqrt{n}}+(\frac{\sqrt{d}}{n\varepsilon}))^\frac{k-1}{k}\right)^\frac{\theta}{\theta-1}\right)$ in high probability, where $n$ is the sample size, $d$ is the model dimension, and $\tilde{r}_{2k}$ is a term that only depends on the $2k$-th moment of the gradient. It is notable that such an upper bound is independent of the Lipschitz constant. We then extend to the case where $\theta\geq \bar{\theta}> 1$ for some known constant $\bar{\theta}$. Moreover, when the privacy budget $\varepsilon$ is small enough, we show an upper bound of $\tilde{O}\left(\left(\tilde{r}_{k}(\frac{1}{\sqrt{n}}+(\frac{\sqrt{d}}{n\varepsilon}))^\frac{k-1}{k}\right)^\frac{\theta}{\theta-1}\right)$ even if the loss function is not Lipschitz. For the lower bound, we show that for any $\theta\geq 2$, the private minimax rate for $\rho$-zero Concentrated Differential Privacy is lower bounded by $\Omega\left(\left(\tilde{r}_{k}(\frac{1}{\sqrt{n}}+(\frac{\sqrt{d}}{n\sqrt{\rho}}))^\frac{k-1}{k}\right)^\frac{\theta}{\theta-1}\right)$.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
Proximal Supervised Fine-Tuning
Aug 25, 2025



Supervised fine-tuning (SFT) of foundation models often leads to poor generalization, where prior capabilities deteriorate after tuning on new tasks or domains. Inspired by trust-region policy optimization (TRPO) and proximal policy optimization (PPO) in reinforcement learning (RL), we propose Proximal SFT (PSFT). This fine-tuning objective incorporates the benefits of trust-region, effectively constraining policy drift during SFT while maintaining competitive tuning. By viewing SFT as a special case of policy gradient methods with constant positive advantages, we derive PSFT that stabilizes optimization and leads to generalization, while leaving room for further optimization in subsequent post-training stages. Experiments across mathematical and human-value domains show that PSFT matches SFT in-domain, outperforms it in out-of-domain generalization, remains stable under prolonged training without causing entropy collapse, and provides a stronger foundation for the subsequent optimization.
Speculating LLMs' Chinese Training Data Pollution from Their Tokens
Aug 25, 2025



Tokens are basic elements in the datasets for LLM training. It is well-known that many tokens representing Chinese phrases in the vocabulary of GPT (4o/4o-mini/o1/o3/4.5/4.1/o4-mini) are indicating contents like pornography or online gambling. Based on this observation, our goal is to locate Polluted Chinese (PoC) tokens in LLMs and study the relationship between PoC tokens' existence and training data. (1) We give a formal definition and taxonomy of PoC tokens based on the GPT's vocabulary. (2) We build a PoC token detector via fine-tuning an LLM to label PoC tokens in vocabularies by considering each token's both semantics and related contents from the search engines. (3) We study the speculation on the training data pollution via PoC tokens' appearances (token ID). Experiments on GPT and other 23 LLMs indicate that tokens widely exist while GPT's vocabulary behaves the worst: more than 23% long Chinese tokens (i.e., a token with more than two Chinese characters) are either porn or online gambling. We validate the accuracy of our speculation method on famous pre-training datasets like C4 and Pile. Then, considering GPT-4o, we speculate that the ratio of "Yui Hatano" related webpages in GPT-4o's training data is around 0.5%.
Advancing Weakly-Supervised Change Detection in Satellite Images via Adversarial Class Prompting
Aug 24, 2025



Weakly-Supervised Change Detection (WSCD) aims to distinguish specific object changes (e.g., objects appearing or disappearing) from background variations (e.g., environmental changes due to light, weather, or seasonal shifts) in paired satellite images, relying only on paired image (i.e., image-level) classification labels. This technique significantly reduces the need for dense annotations required in fully-supervised change detection. However, as image-level supervision only indicates whether objects have changed in a scene, WSCD methods often misclassify background variations as object changes, especially in complex remote-sensing scenarios. In this work, we propose an Adversarial Class Prompting (AdvCP) method to address this co-occurring noise problem, including two phases: a) Adversarial Prompt Mining: After each training iteration, we introduce adversarial prompting perturbations, using incorrect one-hot image-level labels to activate erroneous feature mappings. This process reveals co-occurring adversarial samples under weak supervision, namely background variation features that are likely to be misclassified as object changes. b) Adversarial Sample Rectification: We integrate these adversarially prompt-activated pixel samples into training by constructing an online global prototype. This prototype is built from an exponentially weighted moving average of the current batch and all historical training data. Our AdvCP can be seamlessly integrated into current WSCD methods without adding additional inference cost. Experiments on ConvNet, Transformer, and Segment Anything Model (SAM)-based baselines demonstrate significant performance enhancements. Furthermore, we demonstrate the generalizability of AdvCP to other multi-class weakly-supervised dense prediction scenarios. Code is available at https://github.com/zhenghuizhao/AdvCP
RepreGuard: Detecting LLM-Generated Text by Revealing Hidden Representation Patterns
Aug 18, 2025



Detecting content generated by large language models (LLMs) is crucial for preventing misuse and building trustworthy AI systems. Although existing detection methods perform well, their robustness in out-of-distribution (OOD) scenarios is still lacking. In this paper, we hypothesize that, compared to features used by existing detection methods, the internal representations of LLMs contain more comprehensive and raw features that can more effectively capture and distinguish the statistical pattern differences between LLM-generated texts (LGT) and human-written texts (HWT). We validated this hypothesis across different LLMs and observed significant differences in neural activation patterns when processing these two types of texts. Based on this, we propose RepreGuard, an efficient statistics-based detection method. Specifically, we first employ a surrogate model to collect representation of LGT and HWT, and extract the distinct activation feature that can better identify LGT. We can classify the text by calculating the projection score of the text representations along this feature direction and comparing with a precomputed threshold. Experimental results show that RepreGuard outperforms all baselines with average 94.92% AUROC on both in-distribution (ID) and OOD scenarios, while also demonstrating robust resilience to various text sizes and mainstream attacks. Data and code are publicly available at: https://github.com/NLP2CT/RepreGuard