 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Brewing to Resolution: Tracing the Internal Lifecycle of Code Reasoning in LLMs
Jun 16, 2026Standard accuracy metrics cannot explain why LLMs handle variable tracking but fail on semantically equivalent loops. We study an internal lifecycle of code reasoning in which models first brew the answer, making it linearly recoverable many layers before it becomes self-decodable, and then diverge into one of four resolution outcomes: Resolved, Overprocessed, Misresolved, or Unresolved. Understanding this lifecycle matters because similar task accuracies can mask fundamentally different failure modes that surface-level evaluation cannot detect. We introduce a dual diagnostic framework pairing layer-wise linear probing with Context-Stripped Decoding (CSD) and apply it to six code-reasoning task families across 16 models spanning Qwen, Llama, and DeepSeek architectures. All four outcomes carry substantial mass in every task family: overall Resolved is only 41.5%, with multiple tasks below 30%. Controlled sweeps over structure, depth, and operators expose task-specific failure bottlenecks: Function Call Resolved plunges from 61.1% to 2.5% as call depth increases from one to three. Across architectures and scales, the brewing scaffold remains stable, with normalized brewing duration 24-42% across all 16 models, while resolution success varies with capability. This indicates that the scaffold is a stable empirical regularity across the tested decoder-only Transformer families, whereas resolution success covaries with capability, scale, and training. Code: https://github.com/euyis1019/llm-brewing
Skill or Skip? Learning Selective Skill Invocation in Agentic Tasks via Dual-Granularity Preference Learning
May 30, 2026Agent skills are callable procedural modules that provide reusable knowledge and execution policies for complex agentic tasks. However, existing methods mainly focus on selecting relevant skills or improving the skills themselves, while overlooking whether a relevant skill should actually be invoked at the current decision point. Unhelpful invocations may introduce irrelevant context and disrupt an otherwise correct execution process. To address this issue, we propose SelSkill, a dual-granularity preference-learning framework for selective skill invocation. SelSkill formulates skill use as a skill-or-skip decision, uses predictive uncertainty to prioritize candidate decision points, and constructs controlled invoke-skip preference pairs from shared trajectory prefixes. It further combines episode-level outcome preferences with step-level invocation preferences to capture both overall trajectory quality and the local effectiveness of skill invocation. On ALFWorld with Qwen3-8B, SelSkill improves task success by 10.9 percentage points and execution precision by 29.1 percentage points. On BFCL, it improves task success by 5.7 percentage points and execution precision by 29.5 percentage points. Zero-shot results on Tau-bench and PopQA further suggest that the learned invocation policy transfers to new domains with previously unseen skills.
TrajShield: Trajectory-Level Safety Mediation for Defending Text-to-Video Models Against Jailbreak Attacks
May 03, 2026Text-to-Video (T2V) models have demonstrated remarkable capability in generating temporally coherent videos from natural language prompts, yet they also risk producing unsafe content such as violence or explicit material. Existing prompt-level defenses are largely inherited from text-to-image safety and operate on the lexical surface of the input, making them vulnerable to jailbreak attacks that disguise harmful intent through rephrasing or adversarial prompting. Moreover, T2V generation introduces a distinctive challenge overlooked by prior work: temporally emergent risk, where a seemingly benign prompt leads to unsafe content through the generator's temporal extrapolation toward narrative coherence. We propose \method{}, a training-free, inference-time defense framework that reformulates T2V safety as a causal intervention in a temporally structured semantic space. TrajShield handles explicit unsafe prompts, jailbreak attacks, and temporally emergent risks in a unified manner by simulating the implied trajectory of a prompt, localizing the causal origin of potential risk, and applying a minimally invasive rewrite that neutralizes the risk while preserving safety-irrelevant semantics. Experiments on T2VSafetyBench across 14 safety categories and multiple T2V backends demonstrate that TrajShield achieves state-of-the-art defenseive performance while maintaining high semantic fidelity, substantially outperforming existing defenses, with an average ASR reduction of 52.44\%.
From $\boldsymbol{\logπ}$ to $\boldsymbolπ$: Taming Divergence in Soft Clipping via Bilateral Decoupled Decay of Probability Gradient Weight
Mar 15, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has catalyzed a leap in Large Language Model (LLM) reasoning, yet its optimization dynamics remain fragile. Standard algorithms like GRPO enforce stability via ``hard clipping'', which inadvertently stifles exploration by discarding gradients of tokens outside the trust region. While recent ``soft clipping'' methods attempt to recover these gradients, they suffer from a critical challenge: relying on log-probability gradient ($\nabla_θ\log π_θ$) yields divergent weights as probabilities vanish, destabilizing LLM training. We rethink this convention by establishing probability gradient ($\nabla_θπ_θ$) as the superior optimization primitive. Accordingly, we propose Decoupled Gradient Policy Optimization (DGPO), which employs a decoupled decay mechanism based on importance sampling ratios. By applying asymmetric, continuous decay to boundary tokens, DGPO resolves the conflict between stability and sustained exploration. Extensive experiments across DeepSeek-R1-Distill-Qwen series models (1.5B/7B/14B) demonstrate that DGPO consistently outperforms strong baselines on various mathematical benchmarks, offering a robust and scalable solution for RLVR. Our code and implementation are available at: https://github.com/VenomRose-Juri/DGPO-RL.
Proximity-Based Multi-Turn Optimization: Practical Credit Assignment for LLM Agent Training
Feb 22, 2026Multi-turn LLM agents are becoming pivotal to production systems, spanning customer service automation, e-commerce assistance, and interactive task management, where accurately distinguishing high-value informative signals from stochastic noise is critical for sample-efficient training. In real-world scenarios, a failure in a trivial task may reflect random instability, whereas success in a high-difficulty task signifies a genuine capability breakthrough. Yet, existing group-based policy optimization methods rigidly rely on statistical deviation within discrete batches, frequently misallocating credit when task difficulty fluctuates. To address this issue, we propose Proximity-based Multi-turn Optimization (ProxMO), a practical and robust framework engineered specifically for the constraints of real-world deployment. ProxMO integrates global context via two lightweight mechanisms: success-rate-aware modulation dynamically adapts gradient intensity based on episode-level difficulty, while proximity-based soft aggregation derives baselines through continuous semantic weighting at the step level. Extensive evaluations on ALFWorld and WebShop benchmarks demonstrate that ProxMO yields substantial performance gains over existing baselines with negligible computational cost. Ablation studies further validate the independent and synergistic efficacy of both mechanisms. Crucially, ProxMO offers plug-and-play compatibility with standard GRPO frameworks, facilitating immediate, low-friction adoption in existing industrial training pipelines. Our implementation is available at: \href{https://anonymous.4open.science/r/proxmo-B7E7/README.md}{https://anonymous.4open.science/r/proxmo}.
How to Allocate, How to Learn? Dynamic Rollout Allocation and Advantage Modulation for Policy Optimization
Feb 22, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for Large Language Model (LLM) reasoning, yet current methods face key challenges in resource allocation and policy optimization dynamics: (i) uniform rollout allocation ignores gradient variance heterogeneity across problems, and (ii) the softmax policy structure causes gradient attenuation for high-confidence correct actions, while excessive gradient updates may destabilize training. Therefore, we propose DynaMO, a theoretically-grounded dual-pronged optimization framework. At the sequence level, we prove that uniform allocation is suboptimal and derive variance-minimizing allocation from the first principle, establishing Bernoulli variance as a computable proxy for gradient informativeness. At the token level, we develop gradient-aware advantage modulation grounded in theoretical analysis of gradient magnitude bounds. Our framework compensates for gradient attenuation of high-confidence correct actions while utilizing entropy changes as computable indicators to stabilize excessive update magnitudes. Extensive experiments conducted on a diverse range of mathematical reasoning benchmarks demonstrate consistent improvements over strong RLVR baselines. Our implementation is available at: \href{https://anonymous.4open.science/r/dynamo-680E/README.md}{https://anonymous.4open.science/r/dynamo}.
MASPO: Unifying Gradient Utilization, Probability Mass, and Signal Reliability for Robust and Sample-Efficient LLM Reasoning
Feb 19, 2026Existing Reinforcement Learning with Verifiable Rewards (RLVR) algorithms, such as GRPO, rely on rigid, uniform, and symmetric trust region mechanisms that are fundamentally misaligned with the complex optimization dynamics of Large Language Models (LLMs). In this paper, we identify three critical challenges in these methods: (1) inefficient gradient utilization caused by the binary cutoff of hard clipping, (2) insensitive probability mass arising from uniform ratio constraints that ignore the token distribution, and (3) asymmetric signal reliability stemming from the disparate credit assignment ambiguity between positive and negative samples. To bridge these gaps, we propose Mass-Adaptive Soft Policy Optimization (MASPO), a unified framework designed to harmonize these three dimensions. MASPO integrates a differentiable soft Gaussian gating to maximize gradient utility, a mass-adaptive limiter to balance exploration across the probability spectrum, and an asymmetric risk controller to align update magnitudes with signal confidence. Extensive evaluations demonstrate that MASPO serves as a robust, all-in-one RLVR solution, significantly outperforming strong baselines. Our code is available at: https://anonymous.4open.science/r/ma1/README.md.
BrowseComp-$V^3$: A Visual, Vertical, and Verifiable Benchmark for Multimodal Browsing Agents
Feb 13, 2026Multimodal large language models (MLLMs), equipped with increasingly advanced planning and tool-use capabilities, are evolving into autonomous agents capable of performing multimodal web browsing and deep search in open-world environments. However, existing benchmarks for multimodal browsing remain limited in task complexity, evidence accessibility, and evaluation granularity, hindering comprehensive and reproducible assessments of deep search capabilities. To address these limitations, we introduce BrowseComp-$V^3$, a novel benchmark consisting of 300 carefully curated and challenging questions spanning diverse domains. The benchmark emphasizes deep, multi-level, and cross-modal multi-hop reasoning, where critical evidence is interleaved across textual and visual modalities within and across web pages. All supporting evidence is strictly required to be publicly searchable, ensuring fairness and reproducibility. Beyond final-answer accuracy, we incorporate an expert-validated, subgoal-driven process evaluation mechanism that enables fine-grained analysis of intermediate reasoning behaviors and systematic characterization of capability boundaries. In addition, we propose OmniSeeker, a unified multimodal browsing agent framework integrating diverse web search and visual perception tools. Comprehensive experiments demonstrate that even state-of-the-art models achieve only 36% accuracy on our benchmark, revealing critical bottlenecks in multimodal information integration and fine-grained perception. Our results highlight a fundamental gap between current model capabilities and robust multimodal deep search in real-world settings.
Octopus: Agentic Multimodal Reasoning with Six-Capability Orchestration
Nov 19, 2025Existing multimodal reasoning models and frameworks suffer from fundamental architectural limitations: most lack the human-like ability to autonomously explore diverse reasoning pathways-whether in direct inference, tool-driven visual exploration, programmatic visual manipulation, or intrinsic visual imagination. Consequently, they struggle to adapt to dynamically changing capability requirements in real-world tasks. Meanwhile, humans exhibit a complementary set of thinking abilities when addressing such tasks, whereas existing methods typically cover only a subset of these dimensions. Inspired by this, we propose Octopus: Agentic Multimodal Reasoning with Six-Capability Orchestration, a new paradigm for multimodal agentic reasoning. We define six core capabilities essential for multimodal reasoning and organize a comprehensive evaluation benchmark, Octopus-Bench, accordingly. Octopus is capable of autonomously exploring during reasoning and dynamically selecting the most appropriate capability based on the current state. Experimental results show that Octopus achieves the best performance on the vast majority of tasks in Octopus-Bench, highlighting the crucial role of capability coordination in agentic multimodal reasoning.
D-LEAF: Localizing and Correcting Hallucinations in Multimodal LLMs via Layer-to-head Attention Diagnostics
Sep 09, 2025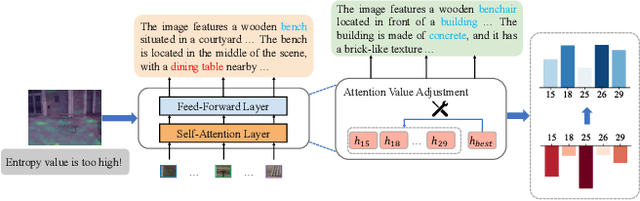

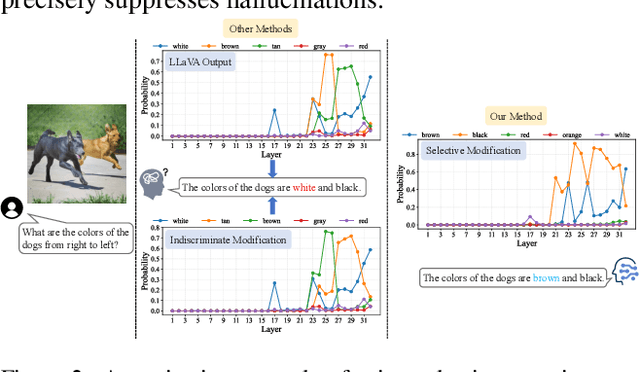
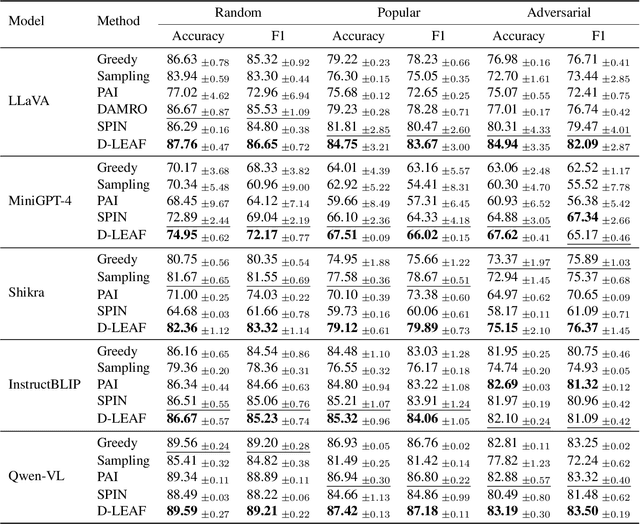
Multimodal Large Language Models (MLLMs) achieve strong performance on tasks like image captioning and visual question answering, but remain prone to hallucinations, where generated text conflicts with the visual input. Prior work links this partly to insufficient visual attention, but existing attention-based detectors and mitigation typically apply uniform adjustments across layers and heads, obscuring where errors originate. In this paper, we first show these methods fail to accurately localize problematic layers. Then, we introduce two diagnostics: Layer Image Attention Entropy (LIAE) which flags anomalous layers, and Image Attention Focus (IAF) which scores attention heads within those layers. Analysis shows that LIAE pinpoints faulty layers and IAF reliably ranks heads that warrant correction. Guided by these signals, we propose Dynamic Layer-wise Entropy and Attention Fusion (D-LEAF), a task-agnostic, attention-guided method that dynamically localizes and corrects errors during inference with negligible overhead. Results show our D-LEAF delivers a 53% relative improvement on standard captioning benchmarks, and on VQA both accuracy and F1-score improve by approximately 4%, substantially suppressing hallucinations while preserving efficiency.