 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERE: Structural Example Retrieval for Enhancing LLMs in Event Causality Identification
May 05, 2026Event Causality Identification (ECI) requires models to determine whether a given pair of events in a context exhibits a causal relationship. While Large Language Models (LLMs) have demonstrated strong performance across various NLP tasks, their effectiveness in ECI remains limited due to biases in causal reasoning, often leading to overprediction of causal relationships (causal hallucination). To mitigate these issues and enhance LLM performance in ECI, we propose SERE, a structural example retrieval framework that leverages LLMs' few-shot learning capabilities. SERE introduces an innovative retrieval mechanism based on three structural concepts: (i) Conceptual Path Metric, which measures the conceptual relationship between events using edit distance in ConceptNet; (ii) Syntactic Metric, which quantifies structural similarity through tree edit distance on syntactic trees; and (iii) Causal Pattern Filtering, which filters examples based on predefined causal structures using LLMs. By integrating these structural retrieval strategies, SERE selects more relevant examples to guide LLMs in causal reasoning, mitigating bias and improving accuracy in ECI tasks. Extensive experiments on multiple ECI datasets validate the effectiveness of SERE. The source code is publicly available at https://github.com/DMIRLAB-Group/SERE.
What Gets Activated: Uncovering Domain and Driver Experts in MoE Language Models
Jan 15, 2026Most interpretability work focuses on layer- or neuron-level mechanisms in Transformers, leaving expert-level behavior in MoE LLMs underexplored. Motivated by functional specialization in the human brain, we analyze expert activation by distinguishing domain and driver experts. In this work, we study expert activation in MoE models across three public domains and address two key questions: (1) which experts are activated, and whether certain expert types exhibit consistent activation patterns; and (2) how tokens are associated with and trigger the activation of specific experts. To answer these questions, we introduce entropy-based and causal-effect metrics to assess whether an expert is strongly favored for a particular domain, and how strongly expert activation contributes causally to the model's output, thus identify domain and driver experts, respectively. Furthermore, we explore how individual tokens are associated with the activation of specific experts. Our analysis reveals that (1) Among the activated experts, some show clear domain preferences, while others exert strong causal influence on model performance, underscoring their decisive roles. (2) tokens occurring earlier in a sentence are more likely to trigger the driver experts, and (3) adjusting the weights of domain and driver experts leads to significant performance gains across all three models and domains. These findings shed light on the internal mechanisms of MoE models and enhance their interpretability.
D-LEAF: Localizing and Correcting Hallucinations in Multimodal LLMs via Layer-to-head Attention Diagnostics
Sep 09, 2025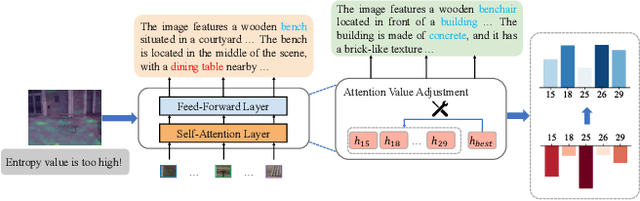

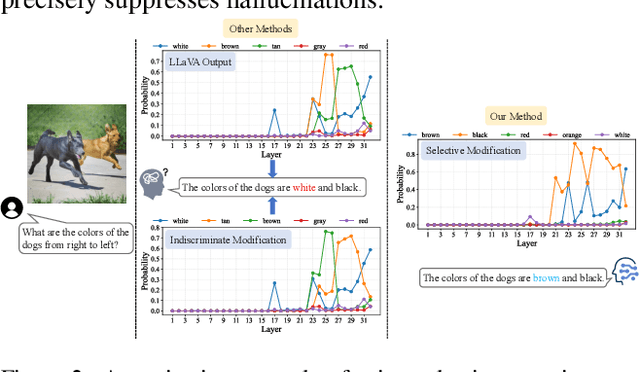
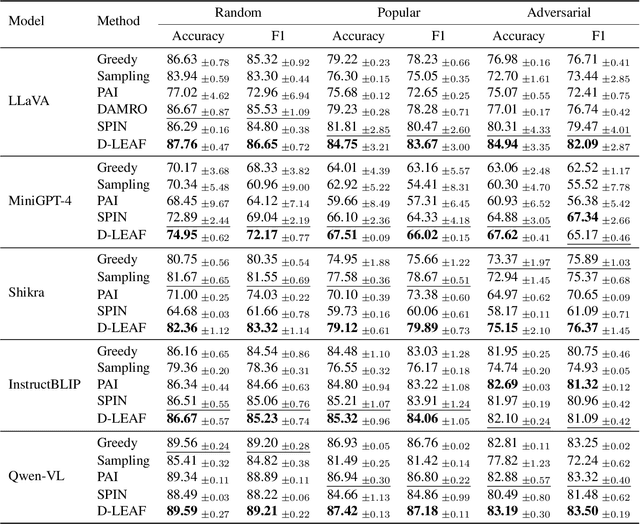
Multimodal Large Language Models (MLLMs) achieve strong performance on tasks like image captioning and visual question answering, but remain prone to hallucinations, where generated text conflicts with the visual input. Prior work links this partly to insufficient visual attention, but existing attention-based detectors and mitigation typically apply uniform adjustments across layers and heads, obscuring where errors originate. In this paper, we first show these methods fail to accurately localize problematic layers. Then, we introduce two diagnostics: Layer Image Attention Entropy (LIAE) which flags anomalous layers, and Image Attention Focus (IAF) which scores attention heads within those layers. Analysis shows that LIAE pinpoints faulty layers and IAF reliably ranks heads that warrant correction. Guided by these signals, we propose Dynamic Layer-wise Entropy and Attention Fusion (D-LEAF), a task-agnostic, attention-guided method that dynamically localizes and corrects errors during inference with negligible overhead. Results show our D-LEAF delivers a 53% relative improvement on standard captioning benchmarks, and on VQA both accuracy and F1-score improve by approximately 4%, substantially suppressing hallucinations while preserving efficiency.
Debiasing Multilingual LLMs in Cross-lingual Latent Space
Aug 25, 2025Debiasing techniques such as SentDebias aim to reduce bias in large language models (LLMs). Previous studies have evaluated their cross-lingual transferability by directly applying these methods to LLM representations, revealing their limited effectiveness across languages. In this work, we therefore propose to perform debiasing in a joint latent space rather than directly on LLM representations. We construct a well-aligned cross-lingual latent space using an autoencoder trained on parallel TED talk scripts. Our experiments with Aya-expanse and two debiasing techniques across four languages (English, French, German, Dutch) demonstrate that a) autoencoders effectively construct a well-aligned cross-lingual latent space, and b) applying debiasing techniques in the learned cross-lingual latent space significantly improves both the overall debiasing performance and cross-lingual transferability.
HapticLLaMA: A Multimodal Sensory Language Model for Haptic Captioning
Aug 08, 2025Haptic captioning is the task of generating natural language descriptions from haptic signals, such as vibrations, for use in virtual reality, accessibility, and rehabilitation applications. While previous multimodal research has focused primarily on vision and audio, haptic signals for the sense of touch remain underexplored. To address this gap, we formalize the haptic captioning task and propose HapticLLaMA, a multimodal sensory language model that interprets vibration signals into descriptions in a given sensory, emotional, or associative category. We investigate two types of haptic tokenizers, a frequency-based tokenizer and an EnCodec-based tokenizer, that convert haptic signals into sequences of discrete units, enabling their integration with the LLaMA model. HapticLLaMA is trained in two stages: (1) supervised fine-tuning using the LLaMA architecture with LoRA-based adaptation, and (2) fine-tuning via reinforcement learning from human feedback (RLHF). We assess HapticLLaMA's captioning performance using both automated n-gram metrics and human evaluation. HapticLLaMA demonstrates strong capability in interpreting haptic vibration signals, achieving a METEOR score of 59.98 and a BLEU-4 score of 32.06 respectively. Additionally, over 61% of the generated captions received human ratings above 3.5 on a 7-point scale, with RLHF yielding a 10% improvement in the overall rating distribution, indicating stronger alignment with human haptic perception. These findings highlight the potential of large language models to process and adapt to sensory data.
HapticCap: A Multimodal Dataset and Task for Understanding User Experience of Vibration Haptic Signals
Jul 17, 2025Haptic signals, from smartphone vibrations to virtual reality touch feedback, can effectively convey information and enhance realism, but designing signals that resonate meaningfully with users is challenging. To facilitate this, we introduce a multimodal dataset and task, of matching user descriptions to vibration haptic signals, and highlight two primary challenges: (1) lack of large haptic vibration datasets annotated with textual descriptions as collecting haptic descriptions is time-consuming, and (2) limited capability of existing tasks and models to describe vibration signals in text. To advance this area, we create HapticCap, the first fully human-annotated haptic-captioned dataset, containing 92,070 haptic-text pairs for user descriptions of sensory, emotional, and associative attributes of vibrations. Based on HapticCap, we propose the haptic-caption retrieval task and present the results of this task from a supervised contrastive learning framework that brings together text representations within specific categories and vibrations. Overall, the combination of language model T5 and audio model AST yields the best performance in the haptic-caption retrieval task, especially when separately trained for each description category.
Partitioner Guided Modal Learning Framework
Jul 15, 2025Multimodal learning benefits from multiple modal information, and each learned modal representations can be divided into uni-modal that can be learned from uni-modal training and paired-modal features that can be learned from cross-modal interaction. Building on this perspective, we propose a partitioner-guided modal learning framework, PgM, which consists of the modal partitioner, uni-modal learner, paired-modal learner, and uni-paired modal decoder. Modal partitioner segments the learned modal representation into uni-modal and paired-modal features. Modal learner incorporates two dedicated components for uni-modal and paired-modal learning. Uni-paired modal decoder reconstructs modal representation based on uni-modal and paired-modal features. PgM offers three key benefits: 1) thorough learning of uni-modal and paired-modal features, 2) flexible distribution adjustment for uni-modal and paired-modal representations to suit diverse downstream tasks, and 3) different learning rates across modalities and partitions. Extensive experiments demonstrate the effectiveness of PgM across four multimodal tasks and further highlight its transferability to existing models. Additionally, we visualize the distribution of uni-modal and paired-modal features across modalities and tasks, offering insights into their respective contributions.
Mitigating Behavioral Hallucination in Multimodal Large Language Models for Sequential Images
Jun 08, 2025



While multimodal large language models excel at various tasks, they still suffer from hallucinations, which limit their reliability and scalability for broader domain applications. To address this issue, recent research mainly focuses on objective hallucination. However, for sequential images, besides objective hallucination, there is also behavioral hallucination, which is less studied. This work aims to fill in the gap. We first reveal that behavioral hallucinations mainly arise from two key factors: prior-driven bias and the snowball effect. Based on these observations, we introduce SHE (Sequence Hallucination Eradication), a lightweight, two-stage framework that (1) detects hallucinations via visual-textual alignment check using our proposed adaptive temporal window and (2) mitigates them via orthogonal projection onto the joint embedding space. We also propose a new metric (BEACH) to quantify behavioral hallucination severity. Empirical results on standard benchmarks demonstrate that SHE reduces behavioral hallucination by over 10% on BEACH while maintaining descriptive accuracy.
C^2 ATTACK: Towards Representation Backdoor on CLIP via Concept Confusion
Mar 12, 2025Backdoor attacks pose a significant threat to deep learning models, enabling adversaries to embed hidden triggers that manipulate the behavior of the model during inference. Traditional backdoor attacks typically rely on inserting explicit triggers (e.g., external patches, or perturbations) into input data, but they often struggle to evade existing defense mechanisms. To address this limitation, we investigate backdoor attacks through the lens of the reasoning process in deep learning systems, drawing insights from interpretable AI. We conceptualize backdoor activation as the manipulation of learned concepts within the model's latent representations. Thus, existing attacks can be seen as implicit manipulations of these activated concepts during inference. This raises interesting questions: why not manipulate the concepts explicitly? This idea leads to our novel backdoor attack framework, Concept Confusion Attack (C^2 ATTACK), which leverages internal concepts in the model's reasoning as "triggers" without introducing explicit external modifications. By avoiding the use of real triggers and directly activating or deactivating specific concepts in latent spaces, our approach enhances stealth, making detection by existing defenses significantly harder. Using CLIP as a case study, experimental results demonstrate the effectiveness of C^2 ATTACK, achieving high attack success rates while maintaining robustness against advanced defenses.
Grounding Emotional Descriptions to Electrovibration Haptic Signals
Nov 04, 2024



Designing and displaying haptic signals with sensory and emotional attributes can improve the user experience in various applications. Free-form user language provides rich sensory and emotional information for haptic design (e.g., ``This signal feels smooth and exciting''), but little work exists on linking user descriptions to haptic signals (i.e., language grounding). To address this gap, we conducted a study where 12 users described the feel of 32 signals perceived on a surface haptics (i.e., electrovibration) display. We developed a computational pipeline using natural language processing (NLP) techniques, such as GPT-3.5 Turbo and word embedding methods, to extract sensory and emotional keywords and group them into semantic clusters (i.e., concepts). We linked the keyword clusters to haptic signal features (e.g., pulse count) using correlation analysis. The proposed pipeline demonstrates the viability of a computational approach to analyzing haptic experiences. We discuss our future plans for creating a predictive model of haptic experience.