 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra Flash: Scaling Real-Time Streaming Video Generation to High Resolutions
Jun 08, 2026While recent autoregressive video diffusion models achieve remarkable streaming quality, they remain confined to low resolutions (e.g., 480P), leaving efficient, scalable, real-time high-resolution video generation a fundamental open challenge. To bridge this gap, we present Ultra Flash, a cascaded streaming framework capable of real-time high-resolution video generation. Ultra Flash achieves ~30 FPS at 1K resolution and ~18 FPS at 2K resolution on a single GPU through three key contributions: (1) an architecture-preserving T2V-to-TV2V super-resolution training paradigm coupled with an AIGC-oriented data degradation pipeline that effectively preserves the generative capability of the base model, enabling enhanced high-resolution detail when cascaded after mainstream low-resolution generative models; (2) a causal streaming latent upsampler paired with a high-resolution decoder, which enhances spatiotemporal coherence while enabling efficient latent spatial scaling and precise high-resolution decoding with negligible computational overhead; and (3) a cascade high-resolution streaming video generation optimization scheme that first performs hybrid-reward-enhanced sparse causalization and single-step distillation of the super-resolution model, then introduces cascaded streaming self-forcing preference optimization with dynamic cache management, jointly enhancing overall coherence, improving quality, and enabling real-time high-resolution streaming video generation. Extensive experiments demonstrate that Ultra Flash reliably produces ultra-high-resolution streaming video while maintaining state-of-the-art visual quality and superior efficiency.
Awaking Spatial Intelligence in Unified Multimodal Understanding and Generation
May 05, 2026We present JoyAI-Image, a unified multimodal foundation model for visual understanding, text-to-image generation, and instruction-guided image editing. JoyAI-Image couples a spatially enhanced Multimodal Large Language Model (MLLM) with a Multimodal Diffusion Transformer (MMDiT), allowing perception and generation to interact through a shared multimodal interface. Around this architecture, we build a scalable training recipe that combines unified instruction tuning, long-text rendering supervision, spatially grounded data, and both general and spatial editing signals. This design gives the model broad multimodal capability while strengthening geometry-aware reasoning and controllable visual synthesis. Experiments across understanding, generation, long-text rendering, and editing benchmarks show that JoyAI-Image achieves state-of-the-art or highly competitive performance. More importantly, the bidirectional loop between enhanced understanding, controllable spatial editing, and novel-view-assisted reasoning enables the model to move beyond general visual competence toward stronger spatial intelligence. These results suggest a promising path for unified visual models in downstream applications such as vision-language-action systems and world models.
Benchmarking and Mitigate Psychological Sycophancy in Medical Vision-Language Models
Sep 26, 2025Vision language models(VLMs) are increasingly integrated into clinical workflows, but they often exhibit sycophantic behavior prioritizing alignment with user phrasing social cues or perceived authority over evidence based reasoning. This study evaluate clinical sycophancy in medical visual question answering through a novel clinically grounded benchmark. We propose a medical sycophancy dataset construct from PathVQA, SLAKE, and VQA-RAD stratified by different type organ system and modality. Using psychologically motivated pressure templates including various sycophancy. In our adversarial experiments on various VLMs, we found that these models are generally vulnerable, exhibiting significant variations in the occurrence of adversarial responses, with weak correlations to the model accuracy or size. Imitation and expert provided corrections were found to be the most effective triggers, suggesting that the models possess a bias mechanism independent of visual evidence. To address this, we propose Visual Information Purification for Evidence based Response (VIPER) a lightweight mitigation strategy that filters non evidentiary content for example social pressures and then generates constrained evidence first answers. This framework reduces sycophancy by an average amount outperforming baselines while maintaining interpretability. Our benchmark analysis and mitigation framework lay the groundwork for robust deployment of medical VLMs in real world clinician interactions emphasizing the need for evidence anchored defenses.
Aime: Towards Fully-Autonomous Multi-Agent Framework
Jul 16, 2025

Multi-Agent Systems (MAS) powered by Large Language Models (LLMs) are emerging as a powerful paradigm for solving complex, multifaceted problems. However, the potential of these systems is often constrained by the prevalent plan-and-execute framework, which suffers from critical limitations: rigid plan execution, static agent capabilities, and inefficient communication. These weaknesses hinder their adaptability and robustness in dynamic environments. This paper introduces Aime, a novel multi-agent framework designed to overcome these challenges through dynamic, reactive planning and execution. Aime replaces the conventional static workflow with a fluid and adaptive architecture. Its core innovations include: (1) a Dynamic Planner that continuously refines the overall strategy based on real-time execution feedback; (2) an Actor Factory that implements Dynamic Actor instantiation, assembling specialized agents on-demand with tailored tools and knowledge; and (3) a centralized Progress Management Module that serves as a single source of truth for coherent, system-wide state awareness. We empirically evaluated Aime on a diverse suite of benchmarks spanning general reasoning (GAIA), software engineering (SWE-bench Verified), and live web navigation (WebVoyager). The results demonstrate that Aime consistently outperforms even highly specialized state-of-the-art agents in their respective domains. Its superior adaptability and task success rate establish Aime as a more resilient and effective foundation for multi-agent collaboration.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
KST-GCN: A Knowledge-Driven Spatial-Temporal Graph Convolutional Network for Traffic Forecasting
Nov 26, 2020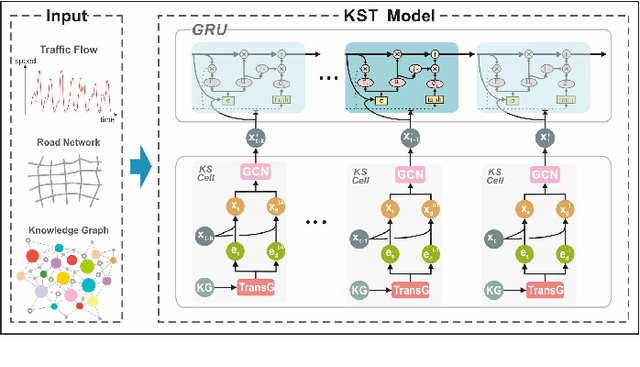
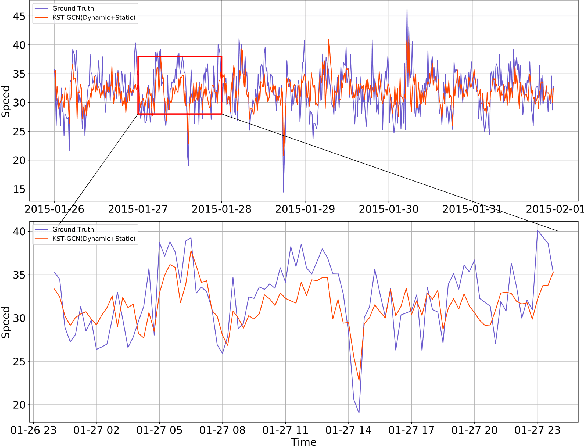
When considering the spatial and temporal features of traffic, capturing the impacts of various external factors on travel is an important step towards achieving accurate traffic forecasting. The impacts of external factors on the traffic flow have complex correlations. However, existing studies seldom consider external factors or neglecting the effect of the complex correlations among external factors on traffic. Intuitively, knowledge graphs can naturally describe these correlations, but knowledge graphs and traffic networks are essentially heterogeneous networks; thus, it is a challenging problem to integrate the information in both networks. We propose a knowledge representation-driven traffic forecasting method based on spatiotemporal graph convolutional networks. We first construct a city knowledge graph for traffic forecasting, then use KS-Cells to combine the information from the knowledge graph and the traffic network, and finally, capture the temporal changes of the traffic state with GRU. Testing on real-world datasets shows that the KST-GCN has higher accuracy than the baseline traffic forecasting methods at various prediction horizons. We provide a new way to integrate knowledge and the spatiotemporal features of data for traffic forecasting tasks. Without any loss of generality, the proposed method can also be extended to other spatiotemporal forecasting tasks.
The Impact of Isolation Kernel on Agglomerative Hierarchical Clustering Algorithms
Oct 12, 2020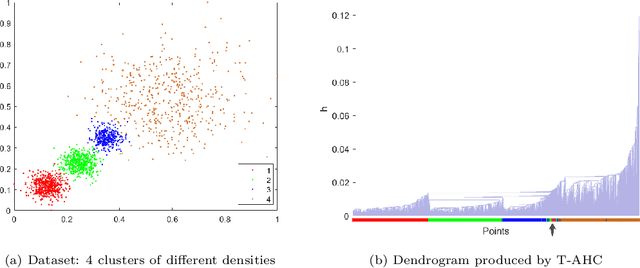
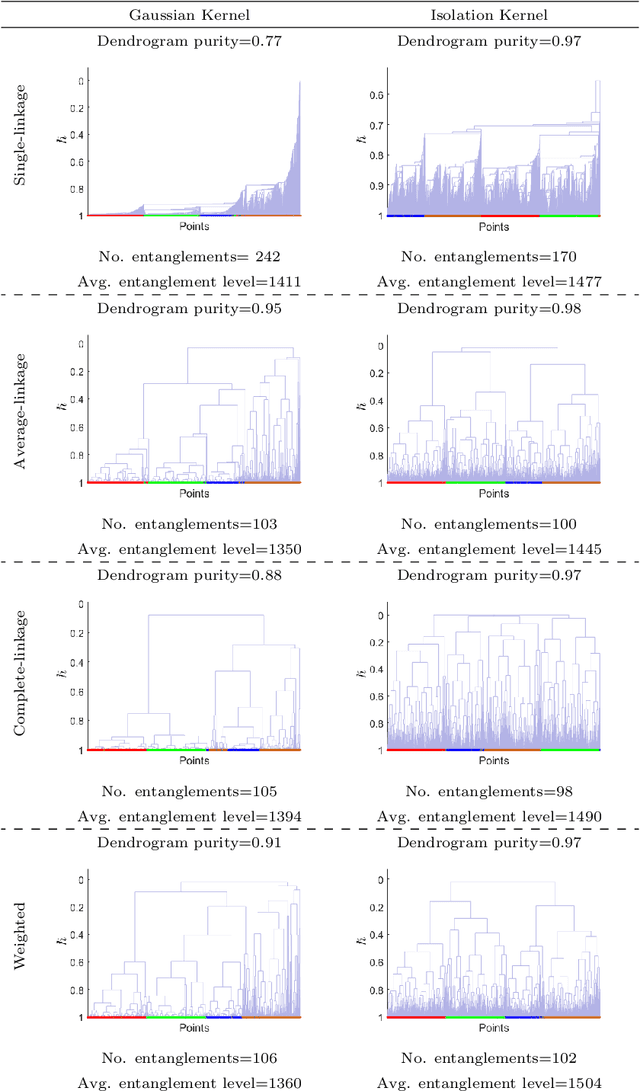
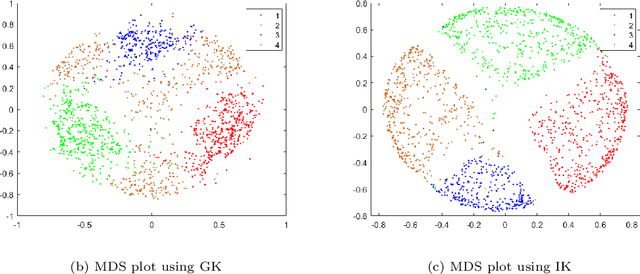
Agglomerative hierarchical clustering (AHC) is one of the popular clustering approaches. Existing AHC methods, which are based on a distance measure, have one key issue: it has difficulty in identifying adjacent clusters with varied densities, regardless of the cluster extraction methods applied on the resultant dendrogram. In this paper, we identify the root cause of this issue and show that the use of a data-dependent kernel (instead of distance or existing kernel) provides an effective means to address it. We analyse the condition under which existing AHC methods fail to extract clusters effectively; and the reason why the data-dependent kernel is an effective remedy. This leads to a new approach to kernerlise existing hierarchical clustering algorithms such as existing traditional AHC algorithms, HDBSCAN, GDL and PHA. In each of these algorithms, our empirical evaluation shows that a recently introduced Isolation Kernel produces a higher quality or purer dendrogram than distance, Gaussian Kernel and adaptive Gaussian Kernel.