 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatryoshka Concept Bottleneck Models
May 20, 2026Concept Bottleneck Models (CBMs) have emerged as a prominent paradigm for interpretable deep learning, learning by grounding predictions in human-understandable concepts. However, their practical deployment is hindered by the high cost of test-time intervention, as correcting model errors typically requires human experts to manually inspect and verify a large set of predicted concepts. Existing approaches suffer from a fundamental structural limitation: they either adopt a single static concept set, forcing experts to exhaustively annotate concepts and incurring prohibitive intervention costs, or train multiple models tailored to different concept budgets, resulting in substantial computational and maintenance overhead. To address this challenge, we propose the Matryoshka Concept Bottleneck Model (MCBM), a unified architecture that enables adaptive concept utilization within a single model. Inspired by Matryoshka Representation Learning, MCBM organizes concepts into a nested hierarchy based on maximum relevance and minimum redundancy, allowing inference at multiple levels of conceptual granularity without retraining. Theoretically, we show that MCBM reduces the expected intervention costs from linear to logarithmic order, $O(\log K)$, while guaranteeing monotonic performance improvement. Empirically, extensive experiments demonstrate that MCBM matches the performance of independently trained models while enabling dynamic and efficient expert interaction.
FaithAct: Faithfulness Planning and Acting in MLLMs
Nov 11, 2025Unfaithfulness remains a persistent challenge for large language models (LLMs), which often produce plausible yet ungrounded reasoning chains that diverge from perceptual evidence or final conclusions. We distinguish between behavioral faithfulness (alignment between reasoning and output) and perceptual faithfulness (alignment between reasoning and input), and introduce FaithEval for quantifying step-level and chain-level faithfulness by evaluating whether each claimed object is visually supported by the image. Building on these insights, we propose FaithAct, a faithfulness-first planning and acting framework that enforces evidential grounding at every reasoning step. Experiments across multiple reasoning benchmarks demonstrate that FaithAct improves perceptual faithfulness by up to 26% without degrading task accuracy compared to prompt-based and tool-augmented baselines. Our analysis shows that treating faithfulness as a guiding principle not only mitigates hallucination but also leads to more stable reasoning trajectories. This work thereby establishes a unified framework for both evaluating and enforcing faithfulness in multimodal reasoning.
Evaluating LLM Understanding via Structured Tabular Decision Simulations
Nov 07, 2025



Large language models (LLMs) often achieve impressive predictive accuracy, yet correctness alone does not imply genuine understanding. True LLM understanding, analogous to human expertise, requires making consistent, well-founded decisions across multiple instances and diverse domains, relying on relevant and domain-grounded decision factors. We introduce Structured Tabular Decision Simulations (STaDS), a suite of expert-like decision settings that evaluate LLMs as if they were professionals undertaking structured decision ``exams''. In this context, understanding is defined as the ability to identify and rely on the correct decision factors, features that determine outcomes within a domain. STaDS jointly assesses understanding through: (i) question and instruction comprehension, (ii) knowledge-based prediction, and (iii) reliance on relevant decision factors. By analyzing 9 frontier LLMs across 15 diverse decision settings, we find that (a) most models struggle to achieve consistently strong accuracy across diverse domains; (b) models can be accurate yet globally unfaithful, and there are frequent mismatches between stated rationales and factors driving predictions. Our findings highlight the need for global-level understanding evaluation protocols and advocate for novel frameworks that go beyond accuracy to enhance LLMs' understanding ability.
Benchmarking and Mitigate Psychological Sycophancy in Medical Vision-Language Models
Sep 26, 2025Vision language models(VLMs) are increasingly integrated into clinical workflows, but they often exhibit sycophantic behavior prioritizing alignment with user phrasing social cues or perceived authority over evidence based reasoning. This study evaluate clinical sycophancy in medical visual question answering through a novel clinically grounded benchmark. We propose a medical sycophancy dataset construct from PathVQA, SLAKE, and VQA-RAD stratified by different type organ system and modality. Using psychologically motivated pressure templates including various sycophancy. In our adversarial experiments on various VLMs, we found that these models are generally vulnerable, exhibiting significant variations in the occurrence of adversarial responses, with weak correlations to the model accuracy or size. Imitation and expert provided corrections were found to be the most effective triggers, suggesting that the models possess a bias mechanism independent of visual evidence. To address this, we propose Visual Information Purification for Evidence based Response (VIPER) a lightweight mitigation strategy that filters non evidentiary content for example social pressures and then generates constrained evidence first answers. This framework reduces sycophancy by an average amount outperforming baselines while maintaining interpretability. Our benchmark analysis and mitigation framework lay the groundwork for robust deployment of medical VLMs in real world clinician interactions emphasizing the need for evidence anchored defenses.
GuideBench: Benchmarking Domain-Oriented Guideline Following for LLM Agents
May 16, 2025Large language models (LLMs) have been widely deployed as autonomous agents capable of following user instructions and making decisions in real-world applications. Previous studies have made notable progress in benchmarking the instruction following capabilities of LLMs in general domains, with a primary focus on their inherent commonsense knowledge. Recently, LLMs have been increasingly deployed as domain-oriented agents, which rely on domain-oriented guidelines that may conflict with their commonsense knowledge. These guidelines exhibit two key characteristics: they consist of a wide range of domain-oriented rules and are subject to frequent updates. Despite these challenges, the absence of comprehensive benchmarks for evaluating the domain-oriented guideline following capabilities of LLMs presents a significant obstacle to their effective assessment and further development. In this paper, we introduce GuideBench, a comprehensive benchmark designed to evaluate guideline following performance of LLMs. GuideBench evaluates LLMs on three critical aspects: (i) adherence to diverse rules, (ii) robustness to rule updates, and (iii) alignment with human preferences. Experimental results on a range of LLMs indicate substantial opportunities for improving their ability to follow domain-oriented guidelines.
Concept-Based Unsupervised Domain Adaptation
May 08, 2025Concept Bottleneck Models (CBMs) enhance interpretability by explaining predictions through human-understandable concepts but typically assume that training and test data share the same distribution. This assumption often fails under domain shifts, leading to degraded performance and poor generalization. To address these limitations and improve the robustness of CBMs, we propose the Concept-based Unsupervised Domain Adaptation (CUDA) framework. CUDA is designed to: (1) align concept representations across domains using adversarial training, (2) introduce a relaxation threshold to allow minor domain-specific differences in concept distributions, thereby preventing performance drop due to over-constraints of these distributions, (3) infer concepts directly in the target domain without requiring labeled concept data, enabling CBMs to adapt to diverse domains, and (4) integrate concept learning into conventional domain adaptation (DA) with theoretical guarantees, improving interpretability and establishing new benchmarks for DA. Experiments demonstrate that our approach significantly outperforms the state-of-the-art CBM and DA methods on real-world datasets.
Energy-Based Concept Bottleneck Models: Unifying Prediction, Concept Intervention, and Conditional Interpretations
Jan 25, 2024



Existing methods, such as concept bottleneck models (CBMs), have been successful in providing concept-based interpretations for black-box deep learning models. They typically work by predicting concepts given the input and then predicting the final class label given the predicted concepts. However, (1) they often fail to capture the high-order, nonlinear interaction between concepts, e.g., correcting a predicted concept (e.g., "yellow breast") does not help correct highly correlated concepts (e.g., "yellow belly"), leading to suboptimal final accuracy; (2) they cannot naturally quantify the complex conditional dependencies between different concepts and class labels (e.g., for an image with the class label "Kentucky Warbler" and a concept "black bill", what is the probability that the model correctly predicts another concept "black crown"), therefore failing to provide deeper insight into how a black-box model works. In response to these limitations, we propose Energy-based Concept Bottleneck Models (ECBMs). Our ECBMs use a set of neural networks to define the joint energy of candidate (input, concept, class) tuples. With such a unified interface, prediction, concept correction, and conditional dependency quantification are then represented as conditional probabilities, which are generated by composing different energy functions. Our ECBMs address both limitations of existing CBMs, providing higher accuracy and richer concept interpretations. Empirical results show that our approach outperforms the state-of-the-art on real-world datasets.
Dynamic Data Augmentation via MCTS for Prostate MRI Segmentation
May 25, 2023Medical image data are often limited due to the expensive acquisition and annotation process. Hence, training a deep-learning model with only raw data can easily lead to overfitting. One solution to this problem is to augment the raw data with various transformations, improving the model's ability to generalize to new data. However, manually configuring a generic augmentation combination and parameters for different datasets is non-trivial due to inconsistent acquisition approaches and data distributions. Therefore, automatic data augmentation is proposed to learn favorable augmentation strategies for different datasets while incurring large GPU overhead. To this end, we present a novel method, called Dynamic Data Augmentation (DDAug), which is efficient and has negligible computation cost. Our DDAug develops a hierarchical tree structure to represent various augmentations and utilizes an efficient Monte-Carlo tree searching algorithm to update, prune, and sample the tree. As a result, the augmentation pipeline can be optimized for each dataset automatically. Experiments on multiple Prostate MRI datasets show that our method outperforms the current state-of-the-art data augmentation strategies.
Reliable and Efficient Evaluation of Adversarial Robustness for Deep Hashing-Based Retrieval
Mar 22, 2023



Deep hashing has been extensively applied to massive image retrieval due to its efficiency and effectiveness. Recently, several adversarial attacks have been presented to reveal the vulnerability of deep hashing models against adversarial examples. However, existing attack methods suffer from degraded performance or inefficiency because they underutilize the semantic relations between original samples or spend a lot of time learning these relations with a deep neural network. In this paper, we propose a novel Pharos-guided Attack, dubbed PgA, to evaluate the adversarial robustness of deep hashing networks reliably and efficiently. Specifically, we design pharos code to represent the semantics of the benign image, which preserves the similarity to semantically relevant samples and dissimilarity to irrelevant ones. It is proven that we can quickly calculate the pharos code via a simple math formula. Accordingly, PgA can directly conduct a reliable and efficient attack on deep hashing-based retrieval by maximizing the similarity between the hash code of the adversarial example and the pharos code. Extensive experiments on the benchmark datasets verify that the proposed algorithm outperforms the prior state-of-the-arts in both attack strength and speed.
Subgraph Frequency Distribution Estimation using Graph Neural Networks
Jul 14, 2022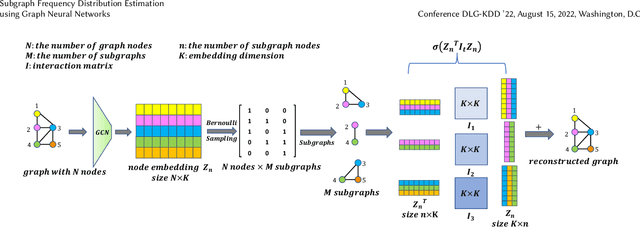
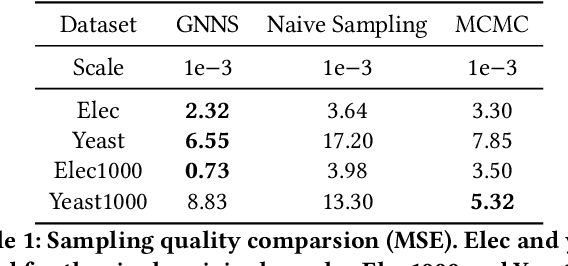
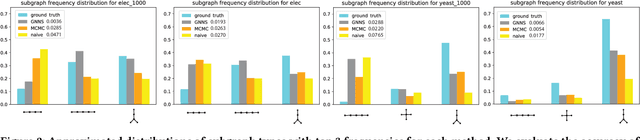
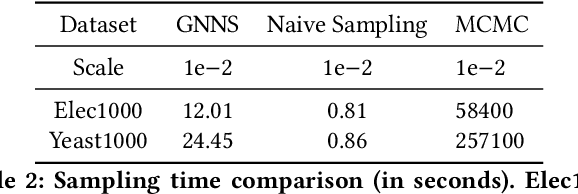
Small subgraphs (graphlets) are important features to describe fundamental units of a large network. The calculation of the subgraph frequency distributions has a wide application in multiple domains including biology and engineering. Unfortunately due to the inherent complexity of this task, most of the existing methods are computationally intensive and inefficient. In this work, we propose GNNS, a novel representational learning framework that utilizes graph neural networks to sample subgraphs efficiently for estimating their frequency distribution. Our framework includes an inference model and a generative model that learns hierarchical embeddings of nodes, subgraphs, and graph types. With the learned model and embeddings, subgraphs are sampled in a highly scalable and parallel way and the frequency distribution estimation is then performed based on these sampled subgraphs. Eventually, our methods achieve comparable accuracy and a significant speedup by three orders of magnitude compared to existing methods.