 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Policy Distillation for LLMs
Apr 22, 2026Knowledge distillation (KD) is a powerful paradigm for compressing large language models (LLMs), whose effectiveness depends on intertwined choices of divergence direction, optimization strategy, and data regime. We break down the design of existing KD methods and present a unified view that establishes connections between them, reformulating KD as a reweighted log-likelihood objective at the token level. We further propose Hybrid Policy Distillation (HPD), which integrates the complementary advantages of forward and reverse KL to balance mode coverage and mode-seeking, and combines off-policy data with lightweight, approximate on-policy sampling. We validate HPD on long-generation math reasoning as well as short-generation dialogue and code tasks, demonstrating improved optimization stability, computational efficiency, and final performance across diverse model families and scales. The code related to this work is available at https://github.com/zwhong714/Hybrid-Policy-Distillation.
MrRoPE: Mixed-radix Rotary Position Embedding
Jan 28, 2026Rotary Position Embedding (RoPE)-extension refers to modifying or generalizing the Rotary Position Embedding scheme to handle longer sequences than those encountered during pre-training. However, current extension strategies are highly diverse and lack a unified theoretical foundation. In this paper, we propose MrRoPE (Mixed-radix RoPE), a generalized encoding formulation based on a radix system conversion perspective, which elegantly unifies various RoPE-extension approaches as distinct radix conversion strategies. Based on this theory, we introduce two training-free extensions, MrRoPE-Uni and MrRoPE-Pro, which leverage uniform and progressive radix conversion strategies, respectively, to achieve 'train short, test long' generalization. Without fine-tuning, MrRoPE-Pro sustains over 85% recall in the 128K-context Needle-in-a-Haystack test and achieves more than double YaRN's accuracy on Infinite-Bench retrieval and dialogue subsets. Theoretical analysis confirms that MrRoPE-Pro effectively raises the upper bound of RoPE's attainable encoding length, which further validates the reliability and utility of our theory and methodology.
InnovatorBench: Evaluating Agents' Ability to Conduct Innovative LLM Research
Nov 03, 2025
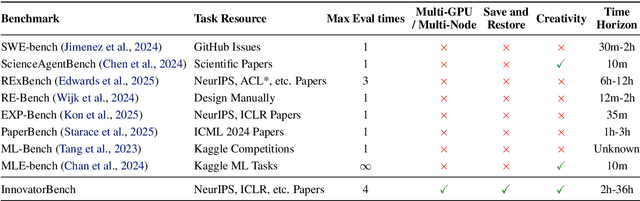


AI agents could accelerate scientific discovery by automating hypothesis formation, experiment design, coding, execution, and analysis, yet existing benchmarks probe narrow skills in simplified settings. To address this gap, we introduce InnovatorBench, a benchmark-platform pair for realistic, end-to-end assessment of agents performing Large Language Model (LLM) research. It comprises 20 tasks spanning Data Construction, Filtering, Augmentation, Loss Design, Reward Design, and Scaffold Construction, which require runnable artifacts and assessment of correctness, performance, output quality, and uncertainty. To support agent operation, we develop ResearchGym, a research environment offering rich action spaces, distributed and long-horizon execution, asynchronous monitoring, and snapshot saving. We also implement a lightweight ReAct agent that couples explicit reasoning with executable planning using frontier models such as Claude-4, GPT-5, GLM-4.5, and Kimi-K2. Our experiments demonstrate that while frontier models show promise in code-driven research tasks, they struggle with fragile algorithm-related tasks and long-horizon decision making, such as impatience, poor resource management, and overreliance on template-based reasoning. Furthermore, agents require over 11 hours to achieve their best performance on InnovatorBench, underscoring the benchmark's difficulty and showing the potential of InnovatorBench to be the next generation of code-based research benchmark.
Proximal Supervised Fine-Tuning
Aug 25, 2025



Supervised fine-tuning (SFT) of foundation models often leads to poor generalization, where prior capabilities deteriorate after tuning on new tasks or domains. Inspired by trust-region policy optimization (TRPO) and proximal policy optimization (PPO) in reinforcement learning (RL), we propose Proximal SFT (PSFT). This fine-tuning objective incorporates the benefits of trust-region, effectively constraining policy drift during SFT while maintaining competitive tuning. By viewing SFT as a special case of policy gradient methods with constant positive advantages, we derive PSFT that stabilizes optimization and leads to generalization, while leaving room for further optimization in subsequent post-training stages. Experiments across mathematical and human-value domains show that PSFT matches SFT in-domain, outperforms it in out-of-domain generalization, remains stable under prolonged training without causing entropy collapse, and provides a stronger foundation for the subsequent optimization.
Flexible Realignment of Language Models
Jun 15, 2025



Realignment becomes necessary when a language model (LM) fails to meet expected performance. We propose a flexible realignment framework that supports quantitative control of alignment degree during training and inference. This framework incorporates Training-time Realignment (TrRa), which efficiently realigns the reference model by leveraging the controllable fusion of logits from both the reference and already aligned models. For example, TrRa reduces token usage by 54.63% on DeepSeek-R1-Distill-Qwen-1.5B without any performance degradation, outperforming DeepScaleR-1.5B's 33.86%. To complement TrRa during inference, we introduce a layer adapter that enables smooth Inference-time Realignment (InRa). This adapter is initialized to perform an identity transformation at the bottom layer and is inserted preceding the original layers. During inference, input embeddings are simultaneously processed by the adapter and the original layer, followed by the remaining layers, and then controllably interpolated at the logit level. We upgraded DeepSeek-R1-Distill-Qwen-7B from a slow-thinking model to one that supports both fast and slow thinking, allowing flexible alignment control even during inference. By encouraging deeper reasoning, it even surpassed its original performance.
Adding Alignment Control to Language Models
Mar 07, 2025



Post-training alignment has increasingly become a crucial factor in enhancing the usability of language models (LMs). However, the strength of alignment varies depending on individual preferences. This paper proposes a method to incorporate alignment control into a single model, referred to as CLM. This approach adds one identity layer preceding the initial layers and performs preference learning only on this layer to map unaligned input token embeddings into the aligned space. Experimental results demonstrate that this efficient fine-tuning method performs comparable to full fine-tuning. During inference, the input embeddings are processed through the aligned and unaligned layers, which are then merged through the interpolation coefficient. By controlling this parameter, the alignment exhibits a clear interpolation and extrapolation phenomenon.
Do Large Language Models Truly Understand Geometric Structures?
Jan 23, 2025



Geometric ability is a significant challenge for large language models (LLMs) due to the need for advanced spatial comprehension and abstract thinking. Existing datasets primarily evaluate LLMs on their final answers, but they cannot truly measure their true understanding of geometric structures, as LLMs can arrive at correct answers by coincidence. To fill this gap, we introduce the GeomRel dataset, designed to evaluate LLMs' understanding of geometric structures by isolating the core step of geometric relationship identification in problem-solving. Using this benchmark, we conduct thorough evaluations of diverse LLMs and identify key limitations in understanding geometric structures. We further propose the Geometry Chain-of-Thought (GeoCoT) method, which enhances LLMs' ability to identify geometric relationships, resulting in significant performance improvements.
Weak-to-Strong Preference Optimization: Stealing Reward from Weak Aligned Model
Oct 24, 2024



Aligning language models (LMs) with human preferences has become a key area of research, enabling these models to meet diverse user needs better. Inspired by weak-to-strong generalization, where a strong LM fine-tuned on labels generated by a weaker model can consistently outperform its weak supervisor, we extend this idea to model alignment. In this work, we observe that the alignment behavior in weaker models can be effectively transferred to stronger models and even exhibit an amplification effect. Based on this insight, we propose a method called Weak-to-Strong Preference Optimization (WSPO), which achieves strong model alignment by learning the distribution differences before and after the alignment of the weak model. Experiments demonstrate that WSPO delivers outstanding performance, improving the win rate of Qwen2-7B-Instruct on Arena-Hard from 39.70 to 49.60, achieving a remarkable 47.04 length-controlled win rate on AlpacaEval 2, and scoring 7.33 on MT-bench. Our results suggest that using the weak model to elicit a strong model with a high alignment ability is feasible.
Improving Open-Ended Text Generation via Adaptive Decoding
Feb 28, 2024



Current language models decode text token by token according to probabilistic distribution, and determining the appropriate candidates for the next token is crucial to ensure generation quality. This study introduces adaptive decoding, a mechanism that empowers the language models to ascertain a sensible candidate set during the generation process dynamically. Specifically, we introduce an entropy-based metric called confidence and conceptualize determining the optimal candidate set as a confidence-increasing process. The rationality of including a token in the candidate set is assessed by leveraging the increment of confidence, enabling the model to determine the most suitable candidate set adaptively. The experimental results reveal that our method achieves higher MAUVE and diversity in story generation tasks and maintains certain coherence, underscoring its superiority over existing algorithms. The code is available at https://github.com/zwhong714/adaptive_decoding.
Is Cognition and Action Consistent or Not: Investigating Large Language Model's Personality
Feb 22, 2024In this study, we investigate the reliability of Large Language Models (LLMs) in professing human-like personality traits through responses to personality questionnaires. Our goal is to evaluate the consistency between LLMs' professed personality inclinations and their actual "behavior", examining the extent to which these models can emulate human-like personality patterns. Through a comprehensive analysis of LLM outputs against established human benchmarks, we seek to understand the cognition-action divergence in LLMs and propose hypotheses for the observed results based on psychological theories and metrics.