 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChangeQuery: Advancing Remote Sensing Change Analysis for Natural and Human-Induced Disasters from Visual Detection to Semantic Understanding
Apr 24, 2026Rapid situational awareness is critical in post-disaster response. While remote sensing damage assessment is evolving from pixel-level change detection to high-level semantic analysis, existing vision-language methodologies still struggle to provide actionable intelligence for complex strategic queries. They remain severely constrained by unimodal optical dependence, a prevailing bias towards natural disasters, and a fundamental lack of grounded interactivity. To address these limitations, we present ChangeQuery, a unified multimodal framework designed for comprehensive, all-weather disaster situation awareness. To overcome modality constraints and scenario biases, we construct the Disaster-Induced Change Query (DICQ) dataset, a large-scale benchmark coupling pre-event optical semantics with post-event SAR structural features across a balanced distribution of natural catastrophes and armed conflicts. Furthermore, to provide the high-quality supervision required for interactive reasoning, we propose a novel Automated Semantic Annotation Pipeline. Adhering to a ``statistics-first, generation-later'' paradigm, this engine automatically transforms raw segmentation masks into grounded, hierarchical instruction sets, effectively equipping the model with fine-grained spatial and quantitative awareness. Trained on this structured data, the ChangeQuery architecture operates as an interactive disaster analyst. It supports multi-task reasoning driven by diverse user queries, delivering precise damage quantification, region-specific descriptions, and holistic post-disaster summaries. Extensive experiments demonstrate that ChangeQuery establishes a new state-of-the-art, providing a robust and interpretable solution for complex disaster monitoring. The code is available at \href{https://sundongwei.github.io/changequery/}{https://sundongwei.github.io/changequery/}.
Bridging Supervision Gaps: A Unified Framework for Remote Sensing Change Detection
Jan 25, 2026Change detection (CD) aims to identify surface changes from multi-temporal remote sensing imagery. In real-world scenarios, Pixel-level change labels are expensive to acquire, and existing models struggle to adapt to scenarios with diverse annotation availability. To tackle this challenge, we propose a unified change detection framework (UniCD), which collaboratively handles supervised, weakly-supervised, and unsupervised tasks through a coupled architecture. UniCD eliminates architectural barriers through a shared encoder and multi-branch collaborative learning mechanism, achieving deep coupling of heterogeneous supervision signals. Specifically, UniCD consists of three supervision-specific branches. In the supervision branch, UniCD introduces the spatial-temporal awareness module (STAM), achieving efficient synergistic fusion of bi-temporal features. In the weakly-supervised branch, we construct change representation regularization (CRR), which steers model convergence from coarse-grained activations toward coherent and separable change modeling. In the unsupervised branch, we propose semantic prior-driven change inference (SPCI), which transforms unsupervised tasks into controlled weakly-supervised path optimization. Experiments on mainstream datasets demonstrate that UniCD achieves optimal performance across three tasks. It exhibits significant accuracy improvements in weakly and unsupervised scenarios, surpassing current state-of-the-art by 12.72% and 12.37% on LEVIR-CD, respectively.
TGPO: Tree-Guided Preference Optimization for Robust Web Agent Reinforcement Learning
Sep 19, 2025With the rapid advancement of large language models and vision-language models, employing large models as Web Agents has become essential for automated web interaction. However, training Web Agents with reinforcement learning faces critical challenges including credit assignment misallocation, prohibitively high annotation costs, and reward sparsity. To address these issues, we propose Tree-Guided Preference Optimization (TGPO), an offline reinforcement learning framework that proposes a tree-structured trajectory representation merging semantically identical states across trajectories to eliminate label conflicts. Our framework incorporates a Process Reward Model that automatically generates fine-grained rewards through subgoal progress, redundancy detection, and action verification. Additionally, a dynamic weighting mechanism prioritizes high-impact decision points during training. Experiments on Online-Mind2Web and our self-constructed C-WebShop datasets demonstrate that TGPO significantly outperforms existing methods, achieving higher success rates with fewer redundant steps.
Advancing Weakly-Supervised Change Detection in Satellite Images via Adversarial Class Prompting
Aug 24, 2025



Weakly-Supervised Change Detection (WSCD) aims to distinguish specific object changes (e.g., objects appearing or disappearing) from background variations (e.g., environmental changes due to light, weather, or seasonal shifts) in paired satellite images, relying only on paired image (i.e., image-level) classification labels. This technique significantly reduces the need for dense annotations required in fully-supervised change detection. However, as image-level supervision only indicates whether objects have changed in a scene, WSCD methods often misclassify background variations as object changes, especially in complex remote-sensing scenarios. In this work, we propose an Adversarial Class Prompting (AdvCP) method to address this co-occurring noise problem, including two phases: a) Adversarial Prompt Mining: After each training iteration, we introduce adversarial prompting perturbations, using incorrect one-hot image-level labels to activate erroneous feature mappings. This process reveals co-occurring adversarial samples under weak supervision, namely background variation features that are likely to be misclassified as object changes. b) Adversarial Sample Rectification: We integrate these adversarially prompt-activated pixel samples into training by constructing an online global prototype. This prototype is built from an exponentially weighted moving average of the current batch and all historical training data. Our AdvCP can be seamlessly integrated into current WSCD methods without adding additional inference cost. Experiments on ConvNet, Transformer, and Segment Anything Model (SAM)-based baselines demonstrate significant performance enhancements. Furthermore, we demonstrate the generalizability of AdvCP to other multi-class weakly-supervised dense prediction scenarios. Code is available at https://github.com/zhenghuizhao/AdvCP
Plug-and-Play DISep: Separating Dense Instances for Scene-to-Pixel Weakly-Supervised Change Detection in High-Resolution Remote Sensing Images
Jan 10, 2025Existing Weakly-Supervised Change Detection (WSCD) methods often encounter the problem of "instance lumping" under scene-level supervision, particularly in scenarios with a dense distribution of changed instances (i.e., changed objects). In these scenarios, unchanged pixels between changed instances are also mistakenly identified as changed, causing multiple changes to be mistakenly viewed as one. In practical applications, this issue prevents the accurate quantification of the number of changes. To address this issue, we propose a Dense Instance Separation (DISep) method as a plug-and-play solution, refining pixel features from a unified instance perspective under scene-level supervision. Specifically, our DISep comprises a three-step iterative training process: 1) Instance Localization: We locate instance candidate regions for changed pixels using high-pass class activation maps. 2) Instance Retrieval: We identify and group these changed pixels into different instance IDs through connectivity searching. Then, based on the assigned instance IDs, we extract corresponding pixel-level features on a per-instance basis. 3) Instance Separation: We introduce a separation loss to enforce intra-instance pixel consistency in the embedding space, thereby ensuring separable instance feature representations. The proposed DISep adds only minimal training cost and no inference cost. It can be seamlessly integrated to enhance existing WSCD methods. We achieve state-of-the-art performance by enhancing {three Transformer-based and four ConvNet-based methods} on the LEVIR-CD, WHU-CD, DSIFN-CD, SYSU-CD, and CDD datasets. Additionally, our DISep can be used to improve fully-supervised change detection methods. Code is available at https://github.com/zhenghuizhao/Plug-and-Play-DISep-for-Change-Detection.
Exploring Effective Priors and Efficient Models for Weakly-Supervised Change Detection
Jul 27, 2023



Weakly-supervised change detection (WSCD) aims to detect pixel-level changes with only image-level annotations. Owing to its label efficiency, WSCD is drawing increasing attention recently. However, current WSCD methods often encounter the challenge of change missing and fabricating, i.e., the inconsistency between image-level annotations and pixel-level predictions. Specifically, change missing refer to the situation that the WSCD model fails to predict any changed pixels, even though the image-level label indicates changed, and vice versa for change fabricating. To address this challenge, in this work, we leverage global-scale and local-scale priors in WSCD and propose two components: a Dilated Prior (DP) decoder and a Label Gated (LG) constraint. The DP decoder decodes samples with the changed image-level label, skips samples with the unchanged label, and replaces them with an all-unchanged pixel-level label. The LG constraint is derived from the correspondence between changed representations and image-level labels, penalizing the model when it mispredicts the change status. Additionally, we develop TransWCD, a simple yet powerful transformer-based model, showcasing the potential of weakly-supervised learning in change detection. By integrating the DP decoder and LG constraint into TransWCD, we form TransWCD-DL. Our proposed TransWCD and TransWCD-DL achieve significant +6.33% and +9.55% F1 score improvements over the state-of-the-art methods on the WHU-CD dataset, respectively. Some performance metrics even exceed several fully-supervised change detection (FSCD) competitors. Code will be available at https://github.com/zhenghuizhao/TransWCD.
Fast QTMT Partition for VVC Intra Coding Using U-Net Framework
Apr 06, 2023



Versatile Video Coding (VVC) has significantly increased encoding efficiency at the expense of numerous complex coding tools, particularly the flexible Quad-Tree plus Multi-type Tree (QTMT) block partition. This paper proposes a deep learning-based algorithm applied in fast QTMT partition for VVC intra coding. Our solution greatly reduces encoding time by early termination of less-likely intra prediction and partitions with negligible BD-BR increase. Firstly, a redesigned U-Net is recommended as the network's fundamental framework. Next, we design a Quality Parameter (QP) fusion network to regulate the effect of QPs on the partition results. Finally, we adopt a refined post-processing strategy to better balance encoding performance and complexity. Experimental results demonstrate that our solution outperforms the state-of-the-art works with a complexity reduction of 44.74% to 68.76% and a BD-BR increase of 0.60% to 2.33%.
Thousand to One: Semantic Prior Modeling for Conceptual Coding
Mar 16, 2021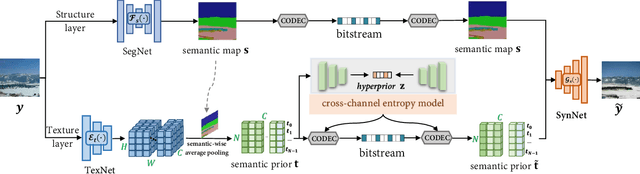
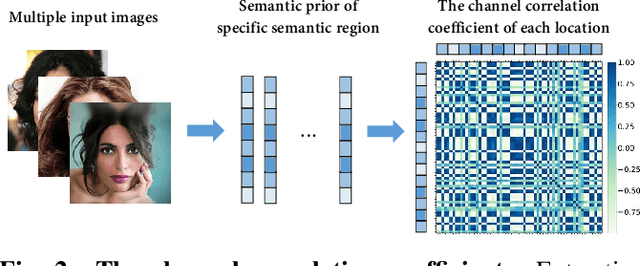

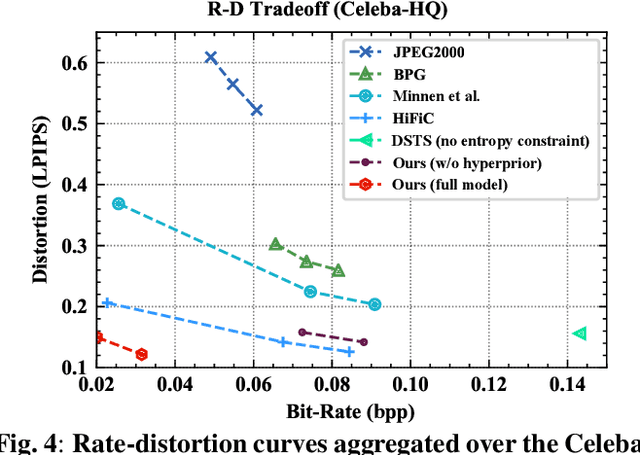
Conceptual coding has been an emerging research topic recently, which encodes natural images into disentangled conceptual representations for compression. However, the compression performance of the existing methods is still sub-optimal due to the lack of comprehensive consideration of rate constraint and reconstruction quality. To this end, we propose a novel end-to-end semantic prior modeling-based conceptual coding scheme towards extremely low bitrate image compression, which leverages semantic-wise deep representations as a unified prior for entropy estimation and texture synthesis. Specifically, we employ semantic segmentation maps as structural guidance for extracting deep semantic prior, which provides fine-grained texture distribution modeling for better detail construction and higher flexibility in subsequent high-level vision tasks. Moreover, a cross-channel entropy model is proposed to further exploit the inter-channel correlation of the spatially independent semantic prior, leading to more accurate entropy estimation for rate-constrained training. The proposed scheme achieves an ultra-high 1000x compression ratio, while still enjoying high visual reconstruction quality and versatility towards visual processing and analysis tasks.
Conceptual Compression via Deep Structure and Texture Synthesis
Nov 10, 2020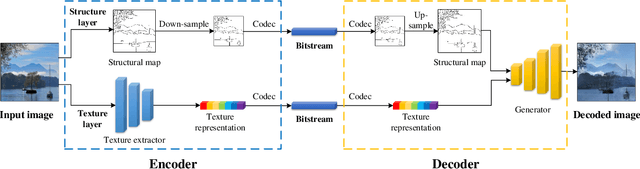
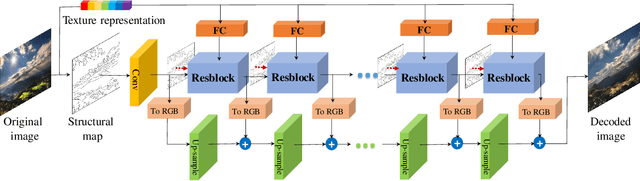
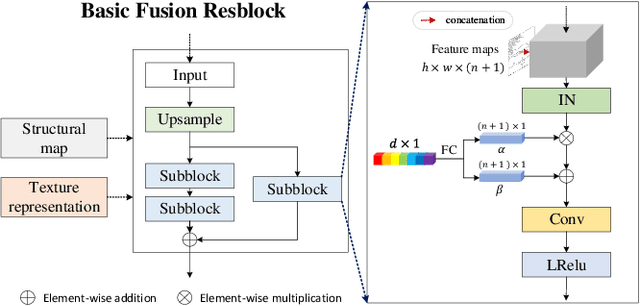
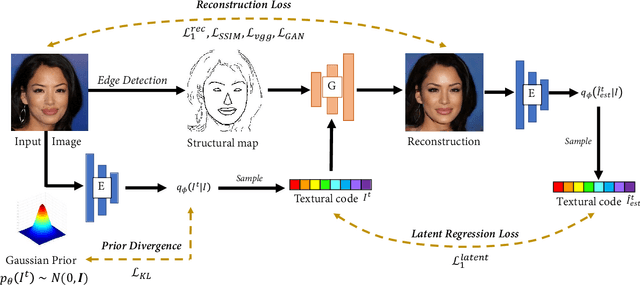
Existing compression methods typically focus on the removal of signal-level redundancies, while the potential and versatility of decomposing visual data into compact conceptual components still lack further study. To this end, we propose a novel conceptual compression framework that encodes visual data into compact structure and texture representations, then decodes in a deep synthesis fashion, aiming to achieve better visual reconstruction quality, flexible content manipulation, and potential support for various vision tasks. In particular, we propose to compress images by a dual-layered model consisting of two complementary visual features: 1) structure layer represented by structural maps and 2) texture layer characterized by low-dimensional deep representations. At the encoder side, the structural maps and texture representations are individually extracted and compressed, generating the compact, interpretable, inter-operable bitstreams. During the decoding stage, a hierarchical fusion GAN (HF-GAN) is proposed to learn the synthesis paradigm where the textures are rendered into the decoded structural maps, leading to high-quality reconstruction with remarkable visual realism. Extensive experiments on diverse images have demonstrated the superiority of our framework with lower bitrates, higher reconstruction quality, and increased versatility towards visual analysis and content manipulation tasks.
Image and Video Compression with Neural Networks: A Review
Apr 10, 2019
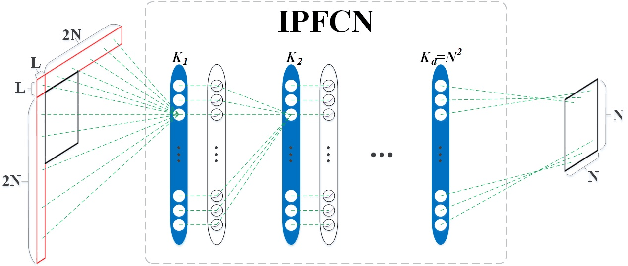
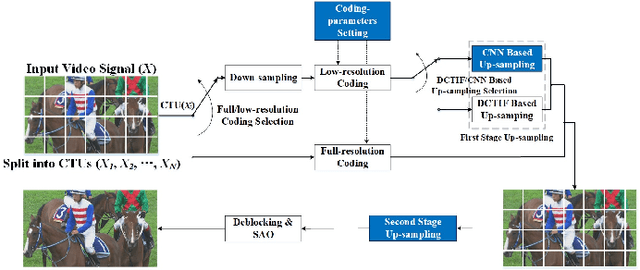
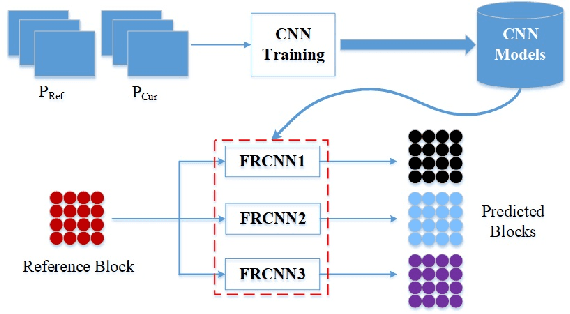
In recent years, the image and video coding technologies have advanced by leaps and bounds. However, due to the popularization of image and video acquisition devices, the growth rate of image and video data is far beyond the improvement of the compression ratio. In particular, it has been widely recognized that there are increasing challenges of pursuing further coding performance improvement within the traditional hybrid coding framework. Deep convolution neural network (CNN) which makes the neural network resurge in recent years and has achieved great success in both artificial intelligent and signal processing fields, also provides a novel and promising solution for image and video compression. In this paper, we provide a systematic, comprehensive and up-to-date review of neural network based image and video compression techniques. The evolution and development of neural network based compression methodologies are introduced for images and video respectively. More specifically, the cutting-edge video coding techniques by leveraging deep learning and HEVC framework are presented and discussed, which promote the state-of-the-art video coding performance substantially. Moreover, the end-to-end image and video coding frameworks based on neural networks are also reviewed, revealing interesting explorations on next generation image and video coding frameworks/standards. The most significant research works on the image and video coding related topics using neural networks are highlighted, and future trends are also envisioned. In particular, the joint compression on semantic and visual information is tentatively explored to formulate high efficiency signal representation structure for both human vision and machine vision, which are the two dominant signal receptor in the age of artificial intelligence.