 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience
Aug 06, 2025Repurposing large vision-language models (LVLMs) as computer use agents (CUAs) has led to substantial breakthroughs, primarily driven by human-labeled data. However, these models often struggle with novel and specialized software, particularly in scenarios lacking human annotations. To address this challenge, we propose SEAgent, an agentic self-evolving framework enabling CUAs to autonomously evolve through interactions with unfamiliar software. Specifically, SEAgent empowers computer-use agents to autonomously master novel software environments via experiential learning, where agents explore new software, learn through iterative trial-and-error, and progressively tackle auto-generated tasks organized from simple to complex. To achieve this goal, we design a World State Model for step-wise trajectory assessment, along with a Curriculum Generator that generates increasingly diverse and challenging tasks. The agent's policy is updated through experiential learning, comprised of adversarial imitation of failure actions and Group Relative Policy Optimization (GRPO) on successful ones. Furthermore, we introduce a specialist-to-generalist training strategy that integrates individual experiential insights from specialist agents, facilitating the development of a stronger generalist CUA capable of continuous autonomous evolution. This unified agent ultimately achieves performance surpassing ensembles of individual specialist agents on their specialized software. We validate the effectiveness of SEAgent across five novel software environments within OS-World. Our approach achieves a significant improvement of 23.2% in success rate, from 11.3% to 34.5%, over a competitive open-source CUA, i.e., UI-TARS.
Beyond Fixed: Variable-Length Denoising for Diffusion Large Language Models
Aug 01, 2025



Diffusion Large Language Models (DLLMs) are emerging as a powerful alternative to the dominant Autoregressive Large Language Models, offering efficient parallel generation and capable global context modeling. However, the practical application of DLLMs is hindered by a critical architectural constraint: the need for a statically predefined generation length. This static length allocation leads to a problematic trade-off: insufficient lengths cripple performance on complex tasks, while excessive lengths incur significant computational overhead and sometimes result in performance degradation. While the inference framework is rigid, we observe that the model itself possesses internal signals that correlate with the optimal response length for a given task. To bridge this gap, we leverage these latent signals and introduce DAEDAL, a novel training-free denoising strategy that enables Dynamic Adaptive Length Expansion for Diffusion Large Language Models. DAEDAL operates in two phases: 1) Before the denoising process, DAEDAL starts from a short initial length and iteratively expands it to a coarse task-appropriate length, guided by a sequence completion metric. 2) During the denoising process, DAEDAL dynamically intervenes by pinpointing and expanding insufficient generation regions through mask token insertion, ensuring the final output is fully developed. Extensive experiments on DLLMs demonstrate that DAEDAL achieves performance comparable, and in some cases superior, to meticulously tuned fixed-length baselines, while simultaneously enhancing computational efficiency by achieving a higher effective token ratio. By resolving the static length constraint, DAEDAL unlocks new potential for DLLMs, bridging a critical gap with their Autoregressive counterparts and paving the way for more efficient and capable generation.
Semi-off-Policy Reinforcement Learning for Vision-Language Slow-thinking Reasoning
Jul 22, 2025



Enhancing large vision-language models (LVLMs) with visual slow-thinking reasoning is crucial for solving complex multimodal tasks. However, since LVLMs are mainly trained with vision-language alignment, it is difficult to adopt on-policy reinforcement learning (RL) to develop the slow thinking ability because the rollout space is restricted by its initial abilities. Off-policy RL offers a way to go beyond the current policy, but directly distilling trajectories from external models may cause visual hallucinations due to mismatched visual perception abilities across models. To address these issues, this paper proposes SOPHIA, a simple and scalable Semi-Off-Policy RL for vision-language slow-tHInking reAsoning. SOPHIA builds a semi-off-policy behavior model by combining on-policy visual understanding from a trainable LVLM with off-policy slow-thinking reasoning from a language model, assigns outcome-based rewards to reasoning, and propagates visual rewards backward. Then LVLM learns slow-thinking reasoning ability from the obtained reasoning trajectories using propagated rewards via off-policy RL algorithms. Extensive experiments with InternVL2.5 and InternVL3.0 with 8B and 38B sizes show the effectiveness of SOPHIA. Notably, SOPHIA improves InternVL3.0-38B by 8.50% in average, reaching state-of-the-art performance among open-source LVLMs on multiple multimodal reasoning benchmarks, and even outperforms some closed-source models (e.g., GPT-4.1) on the challenging MathVision and OlympiadBench, achieving 49.08% and 49.95% pass@1 accuracy, respectively. Analysis shows SOPHIA outperforms supervised fine-tuning and direct on-policy RL methods, offering a better policy initialization for further on-policy training.
CronusVLA: Transferring Latent Motion Across Time for Multi-Frame Prediction in Manipulation
Jun 24, 2025



Recent vision-language-action (VLA) models built on pretrained vision-language models (VLMs) have demonstrated strong generalization across manipulation tasks. However, they remain constrained by a single-frame observation paradigm and cannot fully benefit from the motion information offered by aggregated multi-frame historical observations, as the large vision-language backbone introduces substantial computational cost and inference latency. We propose CronusVLA, a unified framework that extends single-frame VLA models to the multi-frame paradigm through an efficient post-training stage. CronusVLA comprises three key components: (1) single-frame pretraining on large-scale embodied datasets with autoregressive action tokens prediction, which establishes an embodied vision-language foundation; (2) multi-frame encoding, adapting the prediction of vision-language backbones from discrete action tokens to motion features during post-training, and aggregating motion features from historical frames into a feature chunking; (3) cross-frame decoding, which maps the feature chunking to accurate actions via a shared decoder with cross-attention. By reducing redundant token computation and caching past motion features, CronusVLA achieves efficient inference. As an application of motion features, we further propose an action adaptation mechanism based on feature-action retrieval to improve model performance during finetuning. CronusVLA achieves state-of-the-art performance on SimplerEnv with 70.9% success rate, and 12.7% improvement over OpenVLA on LIBERO. Real-world Franka experiments also show the strong performance and robustness.
ScaleCap: Inference-Time Scalable Image Captioning via Dual-Modality Debiasing
Jun 24, 2025
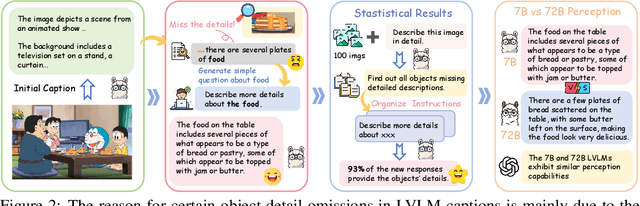

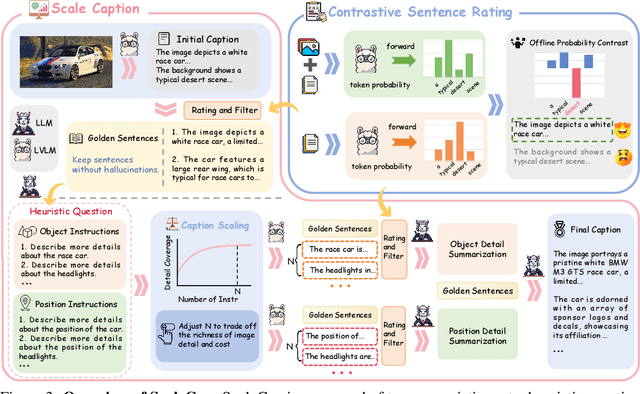
This paper presents ScaleCap, an inference-time scalable image captioning strategy that generates comprehensive and detailed image captions. The key challenges of high-quality image captioning lie in the inherent biases of LVLMs: multimodal bias resulting in imbalanced descriptive granularity, offering detailed accounts of some elements while merely skimming over others; linguistic bias leading to hallucinated descriptions of non-existent objects. To address these issues, we propose a scalable debiased captioning strategy, which continuously enriches and calibrates the caption with increased inference budget. Specifically, we propose two novel components: heuristic question answering and contrastive sentence rating. The former generates content-specific questions based on the image and answers them to progressively inject relevant information into the caption. The latter employs sentence-level offline contrastive decoding to effectively identify and eliminate hallucinations caused by linguistic biases. With increased inference cost, more heuristic questions are raised by ScaleCap to progressively capture additional visual details, generating captions that are more accurate, balanced, and informative. Extensive modality alignment experiments demonstrate the effectiveness of ScaleCap. Annotating 450K images with ScaleCap and using them for LVLM pretraining leads to consistent performance gains across 11 widely used benchmarks. Furthermore, ScaleCap showcases superb richness and fidelity of generated captions with two additional tasks: replacing images with captions in VQA task, and reconstructing images from captions to assess semantic coverage. Code is available at https://github.com/Cooperx521/ScaleCap.
InterActHuman: Multi-Concept Human Animation with Layout-Aligned Audio Conditions
Jun 11, 2025



End-to-end human animation with rich multi-modal conditions, e.g., text, image and audio has achieved remarkable advancements in recent years. However, most existing methods could only animate a single subject and inject conditions in a global manner, ignoring scenarios that multiple concepts could appears in the same video with rich human-human interactions and human-object interactions. Such global assumption prevents precise and per-identity control of multiple concepts including humans and objects, therefore hinders applications. In this work, we discard the single-entity assumption and introduce a novel framework that enforces strong, region-specific binding of conditions from modalities to each identity's spatiotemporal footprint. Given reference images of multiple concepts, our method could automatically infer layout information by leveraging a mask predictor to match appearance cues between the denoised video and each reference appearance. Furthermore, we inject local audio condition into its corresponding region to ensure layout-aligned modality matching in a iterative manner. This design enables the high-quality generation of controllable multi-concept human-centric videos. Empirical results and ablation studies validate the effectiveness of our explicit layout control for multi-modal conditions compared to implicit counterparts and other existing methods.
GTR-CoT: Graph Traversal as Visual Chain of Thought for Molecular Structure Recognition
Jun 09, 2025



Optical Chemical Structure Recognition (OCSR) is crucial for digitizing chemical knowledge by converting molecular images into machine-readable formats. While recent vision-language models (VLMs) have shown potential in this task, their image-captioning approach often struggles with complex molecular structures and inconsistent annotations. To overcome these challenges, we introduce GTR-Mol-VLM, a novel framework featuring two key innovations: (1) the \textit{Graph Traversal as Visual Chain of Thought} mechanism that emulates human reasoning by incrementally parsing molecular graphs through sequential atom-bond predictions, and (2) the data-centric principle of \textit{Faithfully Recognize What You've Seen}, which addresses the mismatch between abbreviated structures in images and their expanded annotations. To support model development, we constructed GTR-CoT-1.3M, a large-scale instruction-tuning dataset with meticulously corrected annotations, and introduced MolRec-Bench, the first benchmark designed for a fine-grained evaluation of graph-parsing accuracy in OCSR. Comprehensive experiments demonstrate that GTR-Mol-VLM achieves superior results compared to specialist models, chemistry-domain VLMs, and commercial general-purpose VLMs. Notably, in scenarios involving molecular images with functional group abbreviations, GTR-Mol-VLM outperforms the second-best baseline by approximately 14 percentage points, both in SMILES-based and graph-based metrics. We hope that this work will drive OCSR technology to more effectively meet real-world needs, thereby advancing the fields of cheminformatics and AI for Science. We will release GTR-CoT at https://github.com/opendatalab/GTR-CoT.
Video World Models with Long-term Spatial Memory
Jun 05, 2025



Emerging world models autoregressively generate video frames in response to actions, such as camera movements and text prompts, among other control signals. Due to limited temporal context window sizes, these models often struggle to maintain scene consistency during revisits, leading to severe forgetting of previously generated environments. Inspired by the mechanisms of human memory, we introduce a novel framework to enhancing long-term consistency of video world models through a geometry-grounded long-term spatial memory. Our framework includes mechanisms to store and retrieve information from the long-term spatial memory and we curate custom datasets to train and evaluate world models with explicitly stored 3D memory mechanisms. Our evaluations show improved quality, consistency, and context length compared to relevant baselines, paving the way towards long-term consistent world generation.
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
May 29, 2025Spatial intelligence is essential for multimodal large language models (MLLMs) operating in the complex physical world. Existing benchmarks, however, probe only single-image relations and thus fail to assess the multi-image spatial reasoning that real-world deployments demand. We introduce MMSI-Bench, a VQA benchmark dedicated to multi-image spatial intelligence. Six 3D-vision researchers spent more than 300 hours meticulously crafting 1,000 challenging, unambiguous multiple-choice questions from over 120,000 images, each paired with carefully designed distractors and a step-by-step reasoning process. We conduct extensive experiments and thoroughly evaluate 34 open-source and proprietary MLLMs, observing a wide gap: the strongest open-source model attains roughly 30% accuracy and OpenAI's o3 reasoning model reaches 40%, while humans score 97%. These results underscore the challenging nature of MMSI-Bench and the substantial headroom for future research. Leveraging the annotated reasoning processes, we also provide an automated error analysis pipeline that diagnoses four dominant failure modes, including (1) grounding errors, (2) overlap-matching and scene-reconstruction errors, (3) situation-transformation reasoning errors, and (4) spatial-logic errors, offering valuable insights for advancing multi-image spatial intelligence. Project page: https://runsenxu.com/projects/MMSI_Bench .
AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views
May 29, 2025We introduce AnySplat, a feed forward network for novel view synthesis from uncalibrated image collections. In contrast to traditional neural rendering pipelines that demand known camera poses and per scene optimization, or recent feed forward methods that buckle under the computational weight of dense views, our model predicts everything in one shot. A single forward pass yields a set of 3D Gaussian primitives encoding both scene geometry and appearance, and the corresponding camera intrinsics and extrinsics for each input image. This unified design scales effortlessly to casually captured, multi view datasets without any pose annotations. In extensive zero shot evaluations, AnySplat matches the quality of pose aware baselines in both sparse and dense view scenarios while surpassing existing pose free approaches. Moreover, it greatly reduce rendering latency compared to optimization based neural fields, bringing real time novel view synthesis within reach for unconstrained capture settings.Project page: https://city-super.github.io/anysplat/