 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Universal Defect Generation: Foundation Models and Datasets
Apr 10, 2026Existing defect/anomaly generation methods often rely on few-shot learning, which overfits to specific defect categories due to the lack of large-scale paired defect editing data. This issue is aggravated by substantial variations in defect scale and morphology, resulting in limited generalization, degraded realism, and category consistency. We address these challenges by introducing UDG, a large-scale dataset of 300K normal-abnormal-mask-caption quadruplets spanning diverse domains, and by presenting UniDG, a universal defect generation foundation model that supports both reference-based defect generation and text instruction-based defect editing without per-category fine-tuning. UniDG performs Defect-Context Editing via adaptive defect cropping and structured diptych input format, and fuses reference and target conditions through MM-DiT multimodal attention. A two-stage training strategy, Diversity-SFT followed by Consistency-RFT, further improves diversity while enhancing realism and reference consistency. Extensive experiments on MVTec-AD and VisA show that UniDG outperforms prior few-shot anomaly generation and image insertion/editing baselines in synthesis quality and downstream single- and multi-class anomaly detection/localization. Code will be available at https://github.com/RetoFan233/UniDG.
ConsistentRFT: Reducing Visual Hallucinations in Flow-based Reinforcement Fine-Tuning
Feb 03, 2026Reinforcement Fine-Tuning (RFT) on flow-based models is crucial for preference alignment. However, they often introduce visual hallucinations like over-optimized details and semantic misalignment. This work preliminarily explores why visual hallucinations arise and how to reduce them. We first investigate RFT methods from a unified perspective, and reveal the core problems stemming from two aspects, exploration and exploitation: (1) limited exploration during stochastic differential equation (SDE) rollouts, leading to an over-emphasis on local details at the expense of global semantics, and (2) trajectory imitation process inherent in policy gradient methods, distorting the model's foundational vector field and its cross-step consistency. Building on this, we propose ConsistentRFT, a general framework to mitigate these hallucinations. Specifically, we design a Dynamic Granularity Rollout (DGR) mechanism to balance exploration between global semantics and local details by dynamically scheduling different noise sources. We then introduce a Consistent Policy Gradient Optimization (CPGO) that preserves the model's consistency by aligning the current policy with a more stable prior. Extensive experiments demonstrate that ConsistentRFT significantly mitigates visual hallucinations, achieving average reductions of 49\% for low-level and 38\% for high-level perceptual hallucinations. Furthermore, ConsistentRFT outperforms other RFT methods on out-of-domain metrics, showing an improvement of 5.1\% (v.s. the baseline's decrease of -0.4\%) over FLUX1.dev. This is \href{https://xiaofeng-tan.github.io/projects/ConsistentRFT}{Project Page}.
Towards Fine-Grained Vision-Language Alignment for Few-Shot Anomaly Detection
Oct 30, 2025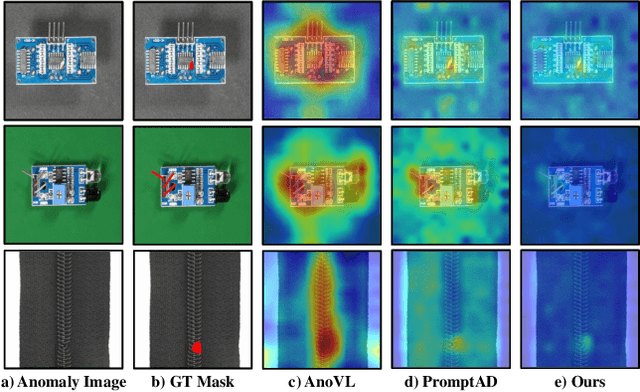
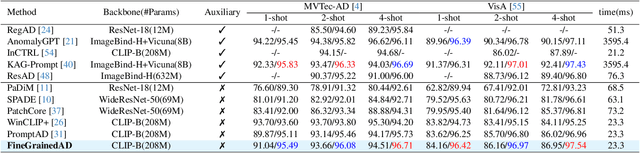
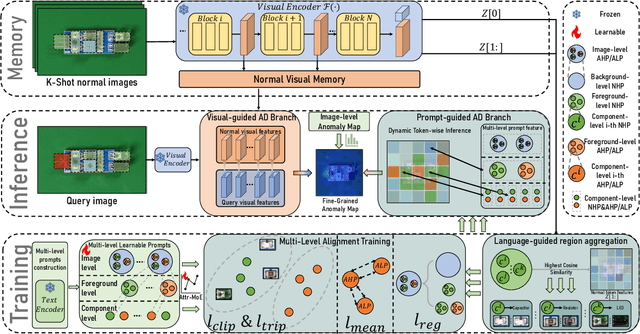
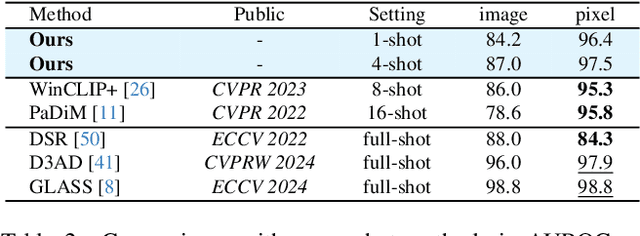
Few-shot anomaly detection (FSAD) methods identify anomalous regions with few known normal samples. Most existing methods rely on the generalization ability of pre-trained vision-language models (VLMs) to recognize potentially anomalous regions through feature similarity between text descriptions and images. However, due to the lack of detailed textual descriptions, these methods can only pre-define image-level descriptions to match each visual patch token to identify potential anomalous regions, which leads to the semantic misalignment between image descriptions and patch-level visual anomalies, achieving sub-optimal localization performance. To address the above issues, we propose the Multi-Level Fine-Grained Semantic Caption (MFSC) to provide multi-level and fine-grained textual descriptions for existing anomaly detection datasets with automatic construction pipeline. Based on the MFSC, we propose a novel framework named FineGrainedAD to improve anomaly localization performance, which consists of two components: Multi-Level Learnable Prompt (MLLP) and Multi-Level Semantic Alignment (MLSA). MLLP introduces fine-grained semantics into multi-level learnable prompts through automatic replacement and concatenation mechanism, while MLSA designs region aggregation strategy and multi-level alignment training to facilitate learnable prompts better align with corresponding visual regions. Experiments demonstrate that the proposed FineGrainedAD achieves superior overall performance in few-shot settings on MVTec-AD and VisA datasets.
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
May 29, 2025Spatial intelligence is essential for multimodal large language models (MLLMs) operating in the complex physical world. Existing benchmarks, however, probe only single-image relations and thus fail to assess the multi-image spatial reasoning that real-world deployments demand. We introduce MMSI-Bench, a VQA benchmark dedicated to multi-image spatial intelligence. Six 3D-vision researchers spent more than 300 hours meticulously crafting 1,000 challenging, unambiguous multiple-choice questions from over 120,000 images, each paired with carefully designed distractors and a step-by-step reasoning process. We conduct extensive experiments and thoroughly evaluate 34 open-source and proprietary MLLMs, observing a wide gap: the strongest open-source model attains roughly 30% accuracy and OpenAI's o3 reasoning model reaches 40%, while humans score 97%. These results underscore the challenging nature of MMSI-Bench and the substantial headroom for future research. Leveraging the annotated reasoning processes, we also provide an automated error analysis pipeline that diagnoses four dominant failure modes, including (1) grounding errors, (2) overlap-matching and scene-reconstruction errors, (3) situation-transformation reasoning errors, and (4) spatial-logic errors, offering valuable insights for advancing multi-image spatial intelligence. Project page: https://runsenxu.com/projects/MMSI_Bench .
Decoupling Classifier for Boosting Few-shot Object Detection and Instance Segmentation
May 20, 2025This paper focus on few-shot object detection~(FSOD) and instance segmentation~(FSIS), which requires a model to quickly adapt to novel classes with a few labeled instances. The existing methods severely suffer from bias classification because of the missing label issue which naturally exists in an instance-level few-shot scenario and is first formally proposed by us. Our analysis suggests that the standard classification head of most FSOD or FSIS models needs to be decoupled to mitigate the bias classification. Therefore, we propose an embarrassingly simple but effective method that decouples the standard classifier into two heads. Then, these two individual heads are capable of independently addressing clear positive samples and noisy negative samples which are caused by the missing label. In this way, the model can effectively learn novel classes while mitigating the effects of noisy negative samples. Without bells and whistles, our model without any additional computation cost and parameters consistently outperforms its baseline and state-of-the-art by a large margin on PASCAL VOC and MS-COCO benchmarks for FSOD and FSIS tasks. The Code is available at https://csgaobb.github.io/Projects/DCFS.
Enhancing Multi-Class Anomaly Detection via Diffusion Refinement with Dual Conditioning
Jul 02, 2024Anomaly detection, the technique of identifying abnormal samples using only normal samples, has attracted widespread interest in industry. Existing one-model-per-category methods often struggle with limited generalization capabilities due to their focus on a single category, and can fail when encountering variations in product. Recent feature reconstruction methods, as representatives in one-model-all-categories schemes, face challenges including reconstructing anomalous samples and blurry reconstructions. In this paper, we creatively combine a diffusion model and a transformer for multi-class anomaly detection. This approach leverages diffusion to obtain high-frequency information for refinement, greatly alleviating the blurry reconstruction problem while maintaining the sampling efficiency of the reverse diffusion process. The task is transformed into image inpainting to disconnect the input-output correlation, thereby mitigating the "identical shortcuts" problem and avoiding the model from reconstructing anomalous samples. Besides, we introduce category-awareness using dual conditioning to ensure the accuracy of prediction and reconstruction in the reverse diffusion process, preventing excessive deviation from the target category, thus effectively enabling multi-class anomaly detection. Futhermore, Spatio-temporal fusion is also employed to fuse heatmaps predicted at different timesteps and scales, enhancing the performance of multi-class anomaly detection. Extensive experiments on benchmark datasets demonstrate the superior performance and exceptional multi-class anomaly detection capabilities of our proposed method compared to others.
Clustered-patch Element Connection for Few-shot Learning
Apr 20, 2023



Weak feature representation problem has influenced the performance of few-shot classification task for a long time. To alleviate this problem, recent researchers build connections between support and query instances through embedding patch features to generate discriminative representations. However, we observe that there exists semantic mismatches (foreground/ background) among these local patches, because the location and size of the target object are not fixed. What is worse, these mismatches result in unreliable similarity confidences, and complex dense connection exacerbates the problem. According to this, we propose a novel Clustered-patch Element Connection (CEC) layer to correct the mismatch problem. The CEC layer leverages Patch Cluster and Element Connection operations to collect and establish reliable connections with high similarity patch features, respectively. Moreover, we propose a CECNet, including CEC layer based attention module and distance metric. The former is utilized to generate a more discriminative representation benefiting from the global clustered-patch features, and the latter is introduced to reliably measure the similarity between pair-features. Extensive experiments demonstrate that our CECNet outperforms the state-of-the-art methods on classification benchmark. Furthermore, our CEC approach can be extended into few-shot segmentation and detection tasks, which achieves competitive performances.
Rethinking the Metric in Few-shot Learning: From an Adaptive Multi-Distance Perspective
Nov 02, 2022



Few-shot learning problem focuses on recognizing unseen classes given a few labeled images. In recent effort, more attention is paid to fine-grained feature embedding, ignoring the relationship among different distance metrics. In this paper, for the first time, we investigate the contributions of different distance metrics, and propose an adaptive fusion scheme, bringing significant improvements in few-shot classification. We start from a naive baseline of confidence summation and demonstrate the necessity of exploiting the complementary property of different distance metrics. By finding the competition problem among them, built upon the baseline, we propose an Adaptive Metrics Module (AMM) to decouple metrics fusion into metric-prediction fusion and metric-losses fusion. The former encourages mutual complementary, while the latter alleviates metric competition via multi-task collaborative learning. Based on AMM, we design a few-shot classification framework AMTNet, including the AMM and the Global Adaptive Loss (GAL), to jointly optimize the few-shot task and auxiliary self-supervised task, making the embedding features more robust. In the experiment, the proposed AMM achieves 2% higher performance than the naive metrics fusion module, and our AMTNet outperforms the state-of-the-arts on multiple benchmark datasets.
House Price Prediction Using LSTM
Sep 25, 2017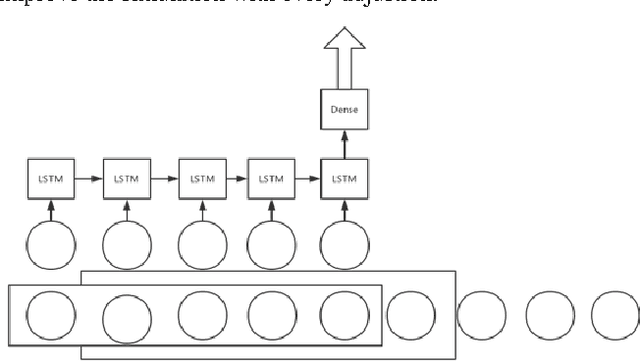
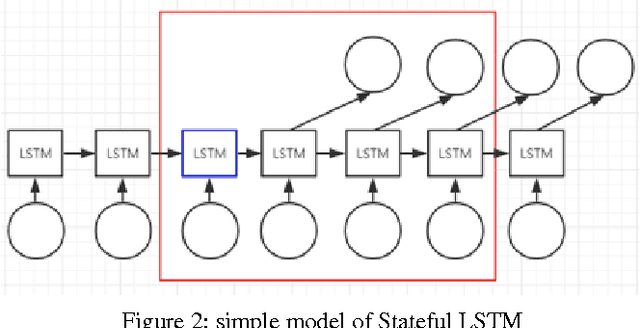
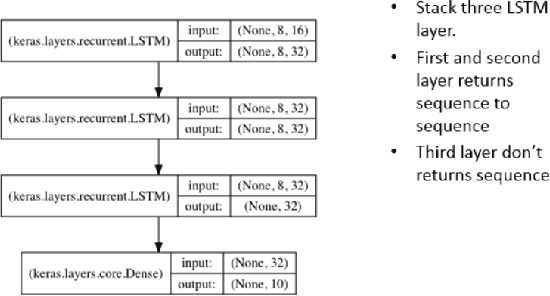
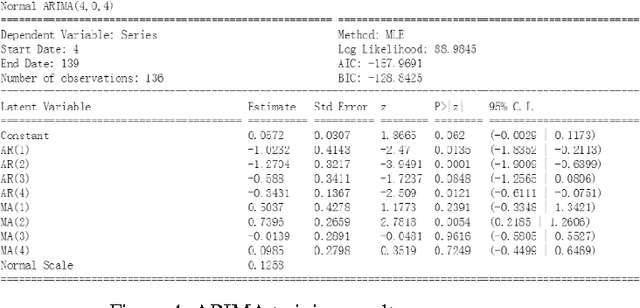
In this paper, we use the house price data ranging from January 2004 to October 2016 to predict the average house price of November and December in 2016 for each district in Beijing, Shanghai, Guangzhou and Shenzhen. We apply Autoregressive Integrated Moving Average model to generate the baseline while LSTM networks to build prediction model. These algorithms are compared in terms of Mean Squared Error. The result shows that the LSTM model has excellent properties with respect to predict time series. Also, stateful LSTM networks and stack LSTM networks are employed to further study the improvement of accuracy of the house prediction model.