 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Skill Lifecycle Management for Agentic Reinforcement Learning
May 11, 2026Large language model agents increasingly rely on external skills to solve complex tasks, where skills act as modular units that extend their capabilities beyond what parametric memory alone supports. Existing methods assume external skills either accumulate as persistent guidance or internalized into the policy, eventually leading to zero-skill inference. We argue this assumption is overly restrictive, since with limited parametric capacity and uneven marginal contribution across skills, the optimal active skill set is non-monotonic, task- and stage-dependent. In this work, we propose SLIM, a framework of dynamic Skill LIfecycle Management for agentic reinforcement learning (RL), which treats the active external skill set as a dynamic optimization variable jointly updated with policy learning. Specifically, SLIM estimates each active skill's marginal external contribution through leave-one-skill-out validation, then applies three lifecycle operations: retaining high-value skills, retiring skills whose contribution becomes negligible after sufficient exposure, and expanding the skill bank when persistent failures reveal missing capability coverage. Experiments show that SLIM outperforms the best baselines by an average of 7.1% points across ALFWorld and SearchQA. Results further indicate that policy learning and external skill retention are not mutually exclusive: some skills are absorbed into the policy, while others continue to provide external value, supporting SLIM as a more general paradigm for skill-based agentic RL.
Long-horizon Reasoning Agent for Olympiad-Level Mathematical Problem Solving
Dec 12, 2025Large Reasoning Models (LRMs) have expanded the mathematical reasoning frontier through Chain-of-Thought (CoT) techniques and Reinforcement Learning with Verifiable Rewards (RLVR), capable of solving AIME-level problems. However, the performance of LRMs is heavily dependent on the extended reasoning context length. For solving ultra-hard problems like those in the International Mathematical Olympiad (IMO), the required reasoning complexity surpasses the space that an LRM can explore in a single round. Previous works attempt to extend the reasoning context of LRMs but remain prompt-based and built upon proprietary models, lacking systematic structures and training pipelines. Therefore, this paper introduces Intern-S1-MO, a long-horizon math agent that conducts multi-round hierarchical reasoning, composed of an LRM-based multi-agent system including reasoning, summary, and verification. By maintaining a compact memory in the form of lemmas, Intern-S1-MO can more freely explore the lemma-rich reasoning spaces in multiple reasoning stages, thereby breaking through the context constraints for IMO-level math problems. Furthermore, we propose OREAL-H, an RL framework for training the LRM using the online explored trajectories to simultaneously bootstrap the reasoning ability of LRM and elevate the overall performance of Intern-S1-MO. Experiments show that Intern-S1-MO can obtain 26 out of 35 points on the non-geometry problems of IMO2025, matching the performance of silver medalists. It also surpasses the current advanced LRMs on inference benchmarks such as HMMT2025, AIME2025, and CNMO2025. In addition, our agent officially participates in CMO2025 and achieves a score of 102/126 under the judgment of human experts, reaching the gold medal level.
Achieving Olympia-Level Geometry Large Language Model Agent via Complexity Boosting Reinforcement Learning
Dec 12, 2025Large language model (LLM) agents exhibit strong mathematical problem-solving abilities and can even solve International Mathematical Olympiad (IMO) level problems with the assistance of formal proof systems. However, due to weak heuristics for auxiliary constructions, AI for geometry problem solving remains dominated by expert models such as AlphaGeometry 2, which rely heavily on large-scale data synthesis and search for both training and evaluation. In this work, we make the first attempt to build a medalist-level LLM agent for geometry and present InternGeometry. InternGeometry overcomes the heuristic limitations in geometry by iteratively proposing propositions and auxiliary constructions, verifying them with a symbolic engine, and reflecting on the engine's feedback to guide subsequent proposals. A dynamic memory mechanism enables InternGeometry to conduct more than two hundred interactions with the symbolic engine per problem. To further accelerate learning, we introduce Complexity-Boosting Reinforcement Learning (CBRL), which gradually increases the complexity of synthesized problems across training stages. Built on InternThinker-32B, InternGeometry solves 44 of 50 IMO geometry problems (2000-2024), exceeding the average gold medalist score (40.9), using only 13K training examples, just 0.004% of the data used by AlphaGeometry 2, demonstrating the potential of LLM agents on expert-level geometry tasks. InternGeometry can also propose novel auxiliary constructions for IMO problems that do not appear in human solutions. We will release the model, data, and symbolic engine to support future research.
Semi-off-Policy Reinforcement Learning for Vision-Language Slow-thinking Reasoning
Jul 22, 2025



Enhancing large vision-language models (LVLMs) with visual slow-thinking reasoning is crucial for solving complex multimodal tasks. However, since LVLMs are mainly trained with vision-language alignment, it is difficult to adopt on-policy reinforcement learning (RL) to develop the slow thinking ability because the rollout space is restricted by its initial abilities. Off-policy RL offers a way to go beyond the current policy, but directly distilling trajectories from external models may cause visual hallucinations due to mismatched visual perception abilities across models. To address these issues, this paper proposes SOPHIA, a simple and scalable Semi-Off-Policy RL for vision-language slow-tHInking reAsoning. SOPHIA builds a semi-off-policy behavior model by combining on-policy visual understanding from a trainable LVLM with off-policy slow-thinking reasoning from a language model, assigns outcome-based rewards to reasoning, and propagates visual rewards backward. Then LVLM learns slow-thinking reasoning ability from the obtained reasoning trajectories using propagated rewards via off-policy RL algorithms. Extensive experiments with InternVL2.5 and InternVL3.0 with 8B and 38B sizes show the effectiveness of SOPHIA. Notably, SOPHIA improves InternVL3.0-38B by 8.50% in average, reaching state-of-the-art performance among open-source LVLMs on multiple multimodal reasoning benchmarks, and even outperforms some closed-source models (e.g., GPT-4.1) on the challenging MathVision and OlympiadBench, achieving 49.08% and 49.95% pass@1 accuracy, respectively. Analysis shows SOPHIA outperforms supervised fine-tuning and direct on-policy RL methods, offering a better policy initialization for further on-policy training.
Latent Relationship Mining of Glaucoma Biomarkers: a TRI-LSTM based Deep Learning
Aug 28, 2024



In recently years, a significant amount of research has been conducted on applying deep learning methods for glaucoma classification and detection. However, the explainability of those established machine learning models remains a big concern. In this research, in contrast, we learn from cognitive science concept and study how ophthalmologists judge glaucoma detection. Simulating experts' efforts, we propose a hierarchical decision making system, centered around a holistic set of carefully designed biomarker-oriented machine learning models. While biomarkers represent the key indicators of how ophthalmologists identify glaucoma, they usually exhibit latent inter-relations. We thus construct a time series model, named TRI-LSTM, capable of calculating and uncovering potential and latent relationships among various biomarkers of glaucoma. Our model is among the first efforts to explore the intrinsic connections among glaucoma biomarkers. We monitor temporal relationships in patients' disease states over time and to capture and retain the progression of disease-relevant clinical information from prior visits, thereby enriching biomarker's potential relationships. Extensive experiments over real-world dataset have demonstrated the effectiveness of the proposed model.
Temporal Graph Neural Network-Powered Paper Recommendation on Dynamic Citation Networks
Aug 27, 2024



Due to the rapid growth of scientific publications, identifying all related reference articles in the literature has become increasingly challenging yet highly demanding. Existing methods primarily assess candidate publications from a static perspective, focusing on the content of articles and their structural information, such as citation relationships. There is a lack of research regarding how to account for the evolving impact among papers on their embeddings. Toward this goal, this paper introduces a temporal dimension to paper recommendation strategies. The core idea is to continuously update a paper's embedding when new citation relationships appear, enhancing its relevance for future recommendations. Whenever a citation relationship is added to the literature upon the publication of a paper, the embeddings of the two related papers are updated through a Temporal Graph Neural Network (TGN). A learnable memory update module based on a Recurrent Neural Network (RNN) is utilized to study the evolution of the embedding of a paper in order to predict its reference impact in a future timestamp. Such a TGN-based model learns a pattern of how people's views of the paper may evolve, aiming to guide paper recommendations more precisely. Extensive experiments on an open citation network dataset, including 313,278 articles from https://paperswithcode.com/about PaperWithCode, have demonstrated the effectiveness of the proposed approach.
Inductive Cognitive Diagnosis for Fast Student Learning in Web-Based Online Intelligent Education Systems
Apr 17, 2024



Cognitive diagnosis aims to gauge students' mastery levels based on their response logs. Serving as a pivotal module in web-based online intelligent education systems (WOIESs), it plays an upstream and fundamental role in downstream tasks like learning item recommendation and computerized adaptive testing. WOIESs are open learning environment where numerous new students constantly register and complete exercises. In WOIESs, efficient cognitive diagnosis is crucial to fast feedback and accelerating student learning. However, the existing cognitive diagnosis methods always employ intrinsically transductive student-specific embeddings, which become slow and costly due to retraining when dealing with new students who are unseen during training. To this end, this paper proposes an inductive cognitive diagnosis model (ICDM) for fast new students' mastery levels inference in WOIESs. Specifically, in ICDM, we propose a novel student-centered graph (SCG). Rather than inferring mastery levels through updating student-specific embedding, we derive the inductive mastery levels as the aggregated outcomes of students' neighbors in SCG. Namely, SCG enables to shift the task from finding the most suitable student-specific embedding that fits the response logs to finding the most suitable representations for different node types in SCG, and the latter is more efficient since it no longer requires retraining. To obtain this representation, ICDM consists of a construction-aggregation-generation-transformation process to learn the final representation of students, exercises and concepts. Extensive experiments across real-world datasets show that, compared with the existing cognitive diagnosis methods that are always transductive, ICDM is much more faster while maintains the competitive inference performance for new students.
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems
Feb 21, 2024



Recent advancements have seen Large Language Models (LLMs) and Large Multimodal Models (LMMs) surpassing general human capabilities in various tasks, approaching the proficiency level of human experts across multiple domains. With traditional benchmarks becoming less challenging for these models, new rigorous challenges are essential to gauge their advanced abilities. In this work, we present OlympiadBench, an Olympiad-level bilingual multimodal scientific benchmark, featuring 8,952 problems from Olympiad-level mathematics and physics competitions, including the Chinese college entrance exam. Each problem is detailed with expert-level annotations for step-by-step reasoning. Evaluating top-tier models on OlympiadBench, we implement a comprehensive assessment methodology to accurately evaluate model responses. Notably, the best-performing model, GPT-4V, attains an average score of 17.23% on OlympiadBench, with a mere 11.28% in physics, highlighting the benchmark rigor and the intricacy of physical reasoning. Our analysis orienting GPT-4V points out prevalent issues with hallucinations, knowledge omissions, and logical fallacies. We hope that our challenging benchmark can serve as a valuable resource for helping future AGI research endeavors.
Research on Self-adaptive Online Vehicle Velocity Prediction Strategy Considering Traffic Information Fusion
Oct 07, 2022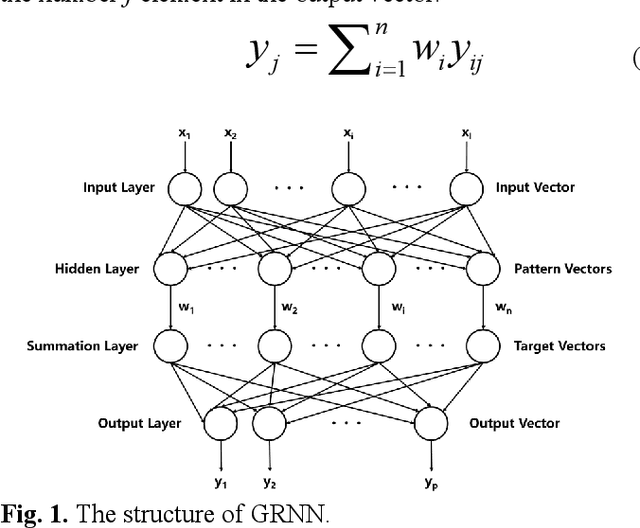
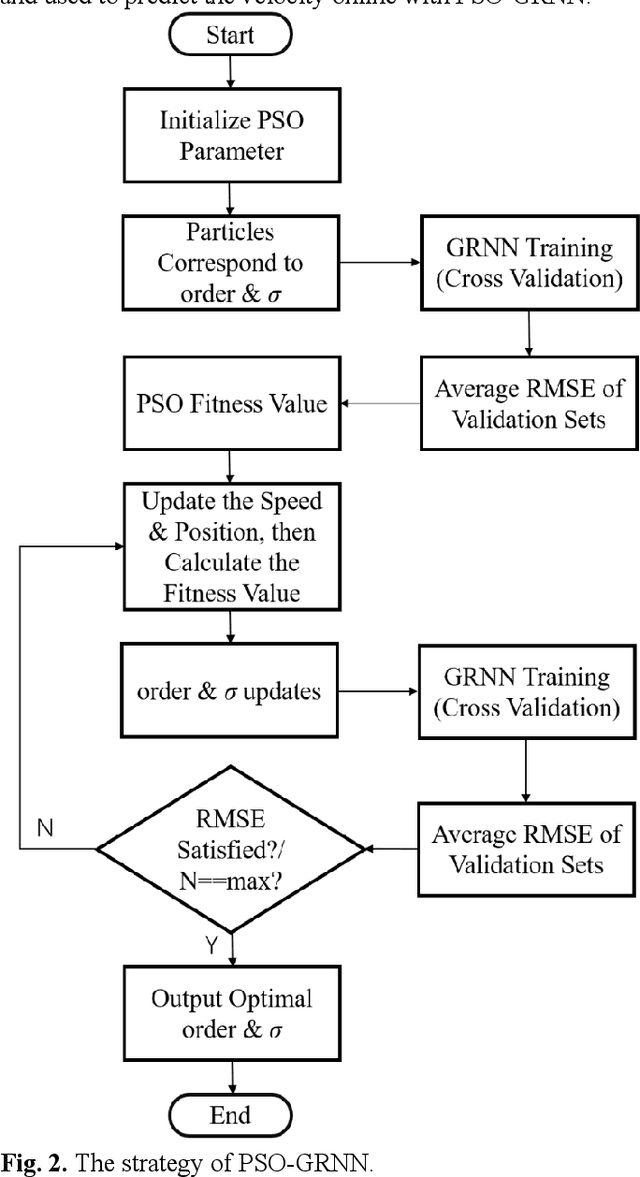
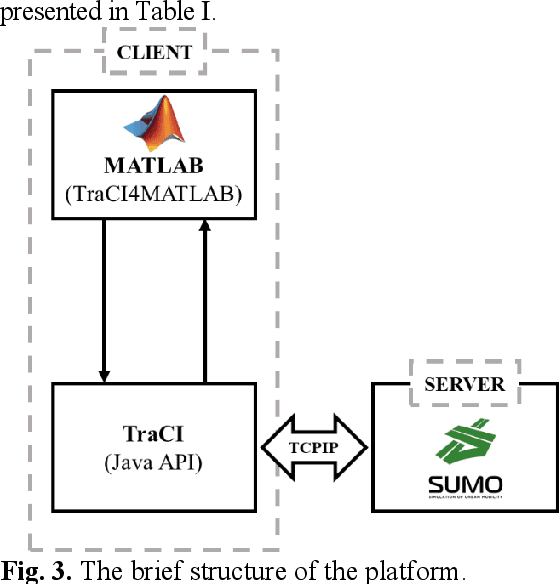
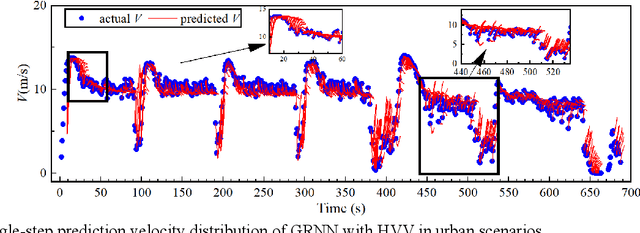
In order to increase the prediction accuracy of the online vehicle velocity prediction (VVP) strategy, a self-adaptive velocity prediction algorithm fused with traffic information was presented for the multiple scenarios. Initially, traffic scenarios were established inside the co-simulation environment. In addition, the algorithm of a general regressive neural network (GRNN) paired with datasets of the ego-vehicle, the front vehicle, and traffic lights was used in traffic scenarios, which increasingly improved the prediction accuracy. To ameliorate the robustness of the algorithm, then the strategy was optimized by particle swarm optimization (PSO) and k-fold cross-validation to find the optimal parameters of the neural network in real-time, which constructed a self-adaptive online PSO-GRNN VVP strategy with multi-information fusion to adapt with different operating situations. The self-adaptive online PSO-GRNN VVP strategy was then deployed to a variety of simulated scenarios to test its efficacy under various operating situations. Finally, the simulation results reveal that in urban and highway scenarios, the prediction accuracy is separately increased by 27.8% and 54.5% when compared to the traditional GRNN VVP strategy with fixed parameters utilizing only the historical ego-vehicle velocity dataset.