 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Second Challenge on Real-World Face Restoration at NTIRE 2026: Methods and Results
Apr 12, 2026This paper provides a review of the NTIRE 2026 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural and realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. Performance is evaluated using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 96 registrants, with 10 teams submitting valid models; ultimately, 9 teams achieved valid scores in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
M^3: Dense Matching Meets Multi-View Foundation Models for Monocular Gaussian Splatting SLAM
Mar 17, 2026Streaming reconstruction from uncalibrated monocular video remains challenging, as it requires both high-precision pose estimation and computationally efficient online refinement in dynamic environments. While coupling 3D foundation models with SLAM frameworks is a promising paradigm, a critical bottleneck persists: most multi-view foundation models estimate poses in a feed-forward manner, yielding pixel-level correspondences that lack the requisite precision for rigorous geometric optimization. To address this, we present M^3, which augments the Multi-view foundation model with a dedicated Matching head to facilitate fine-grained dense correspondences and integrates it into a robust Monocular Gaussian Splatting SLAM. M^3 further enhances tracking stability by incorporating dynamic area suppression and cross-inference intrinsic alignment. Extensive experiments on diverse indoor and outdoor benchmarks demonstrate state-of-the-art accuracy in both pose estimation and scene reconstruction. Notably, M^3 reduces ATE RMSE by 64.3% compared to VGGT-SLAM 2.0 and outperforms ARTDECO by 2.11 dB in PSNR on the ScanNet++ dataset.
PackUV: Packed Gaussian UV Maps for 4D Volumetric Video
Feb 26, 2026Volumetric videos offer immersive 4D experiences, but remain difficult to reconstruct, store, and stream at scale. Existing Gaussian Splatting based methods achieve high-quality reconstruction but break down on long sequences, temporal inconsistency, and fail under large motions and disocclusions. Moreover, their outputs are typically incompatible with conventional video coding pipelines, preventing practical applications. We introduce PackUV, a novel 4D Gaussian representation that maps all Gaussian attributes into a sequence of structured, multi-scale UV atlas, enabling compact, image-native storage. To fit this representation from multi-view videos, we propose PackUV-GS, a temporally consistent fitting method that directly optimizes Gaussian parameters in the UV domain. A flow-guided Gaussian labeling and video keyframing module identifies dynamic Gaussians, stabilizes static regions, and preserves temporal coherence even under large motions and disocclusions. The resulting UV atlas format is the first unified volumetric video representation compatible with standard video codecs (e.g., FFV1) without losing quality, enabling efficient streaming within existing multimedia infrastructure. To evaluate long-duration volumetric capture, we present PackUV-2B, the largest multi-view video dataset to date, featuring more than 50 synchronized cameras, substantial motion, and frequent disocclusions across 100 sequences and 2B (billion) frames. Extensive experiments demonstrate that our method surpasses existing baselines in rendering fidelity while scaling to sequences up to 30 minutes with consistent quality.
* https://ivl.cs.brown.edu/packuv
TrajVG: 3D Trajectory-Coupled Visual Geometry Learning
Feb 05, 2026Feed-forward multi-frame 3D reconstruction models often degrade on videos with object motion. Global-reference becomes ambiguous under multiple motions, while the local pointmap relies heavily on estimated relative poses and can drift, causing cross-frame misalignment and duplicated structures. We propose TrajVG, a reconstruction framework that makes cross-frame 3D correspondence an explicit prediction by estimating camera-coordinate 3D trajectories. We couple sparse trajectories, per-frame local point maps, and relative camera poses with geometric consistency objectives: (i) bidirectional trajectory-pointmap consistency with controlled gradient flow, and (ii) a pose consistency objective driven by static track anchors that suppresses gradients from dynamic regions. To scale training to in-the-wild videos where 3D trajectory labels are scarce, we reformulate the same coupling constraints into self-supervised objectives using only pseudo 2D tracks, enabling unified training with mixed supervision. Extensive experiments across 3D tracking, pose estimation, pointmap reconstruction, and video depth show that TrajVG surpasses the current feedforward performance baseline.
SynthVerse: A Large-Scale Diverse Synthetic Dataset for Point Tracking
Feb 04, 2026Point tracking aims to follow visual points through complex motion, occlusion, and viewpoint changes, and has advanced rapidly with modern foundation models. Yet progress toward general point tracking remains constrained by limited high-quality data, as existing datasets often provide insufficient diversity and imperfect trajectory annotations. To this end, we introduce SynthVerse, a large-scale, diverse synthetic dataset specifically designed for point tracking. SynthVerse includes several new domains and object types missing from existing synthetic datasets, such as animated-film-style content, embodied manipulation, scene navigation, and articulated objects. SynthVerse substantially expands dataset diversity by covering a broader range of object categories and providing high-quality dynamic motions and interactions, enabling more robust training and evaluation for general point tracking. In addition, we establish a highly diverse point tracking benchmark to systematically evaluate state-of-the-art methods under broader domain shifts. Extensive experiments and analyses demonstrate that training with SynthVerse yields consistent improvements in generalization and reveal limitations of existing trackers under diverse settings.
EAG-PT: Emission-Aware Gaussians and Path Tracing for Indoor Scene Reconstruction and Editing
Jan 30, 2026Recent reconstruction methods based on radiance field such as NeRF and 3DGS reproduce indoor scenes with high visual fidelity, but break down under scene editing due to baked illumination and the lack of explicit light transport. In contrast, physically based inverse rendering relies on mesh representations and path tracing, which enforce correct light transport but place strong requirements on geometric fidelity, becoming a practical bottleneck for real indoor scenes. In this work, we propose Emission-Aware Gaussians and Path Tracing (EAG-PT), aiming for physically based light transport with a unified 2D Gaussian representation. Our design is based on three cores: (1) using 2D Gaussians as a unified scene representation and transport-friendly geometry proxy that avoids reconstructed mesh, (2) explicitly separating emissive and non-emissive components during reconstruction for further scene editing, and (3) decoupling reconstruction from final rendering by using efficient single-bounce optimization and high-quality multi-bounce path tracing after scene editing. Experiments on synthetic and real indoor scenes show that EAG-PT produces more natural and physically consistent renders after editing than radiant scene reconstructions, while preserving finer geometric detail and avoiding mesh-induced artifacts compared to mesh-based inverse path tracing. These results suggest promising directions for future use in interior design, XR content creation, and embodied AI.
PLANING: A Loosely Coupled Triangle-Gaussian Framework for Streaming 3D Reconstruction
Jan 29, 2026Streaming reconstruction from monocular image sequences remains challenging, as existing methods typically favor either high-quality rendering or accurate geometry, but rarely both. We present PLANING, an efficient on-the-fly reconstruction framework built on a hybrid representation that loosely couples explicit geometric primitives with neural Gaussians, enabling geometry and appearance to be modeled in a decoupled manner. This decoupling supports an online initialization and optimization strategy that separates geometry and appearance updates, yielding stable streaming reconstruction with substantially reduced structural redundancy. PLANING improves dense mesh Chamfer-L2 by 18.52% over PGSR, surpasses ARTDECO by 1.31 dB PSNR, and reconstructs ScanNetV2 scenes in under 100 seconds, over 5x faster than 2D Gaussian Splatting, while matching the quality of offline per-scene optimization. Beyond reconstruction quality, the structural clarity and computational efficiency of \modelname~make it well suited for a broad range of downstream applications, such as enabling large-scale scene modeling and simulation-ready environments for embodied AI. Project page: https://city-super.github.io/PLANING/ .
PEAfowl: Perception-Enhanced Multi-View Vision-Language-Action for Bimanual Manipulation
Jan 25, 2026Bimanual manipulation in cluttered scenes requires policies that remain stable under occlusions, viewpoint and scene variations. Existing vision-language-action models often fail to generalize because (i) multi-view features are fused via view-agnostic token concatenation, yielding weak 3D-consistent spatial understanding, and (ii) language is injected as global conditioning, resulting in coarse instruction grounding. In this paper, we introduce PEAfowl, a perception-enhanced multi-view VLA policy for bimanual manipulation. For spatial reasoning, PEAfowl predicts per-token depth distributions, performs differentiable 3D lifting, and aggregates local cross-view neighbors to form geometrically grounded, cross-view consistent representations. For instruction grounding, we propose to replace global conditioning with a Perceiver-style text-aware readout over frozen CLIP visual features, enabling iterative evidence accumulation. To overcome noisy and incomplete commodity depth without adding inference overhead, we apply training-only depth distillation from a pretrained depth teacher to supervise the depth-distribution head, providing perception front-end with geometry-aware priors. On RoboTwin 2.0 under domain-randomized setting, PEAfowl improves the strongest baseline by 23.0 pp in success rate, and real-robot experiments further demonstrate reliable sim-to-real transfer and consistent improvements from depth distillation. Project website: https://peafowlvla.github.io/.
Towards Trustworthy Dermatology MLLMs: A Benchmark and Multimodal Evaluator for Diagnostic Narratives
Nov 12, 2025Multimodal large language models (LLMs) are increasingly used to generate dermatology diagnostic narratives directly from images. However, reliable evaluation remains the primary bottleneck for responsible clinical deployment. We introduce a novel evaluation framework that combines DermBench, a meticulously curated benchmark, with DermEval, a robust automatic evaluator, to enable clinically meaningful, reproducible, and scalable assessment. We build DermBench, which pairs 4,000 real-world dermatology images with expert-certified diagnostic narratives and uses an LLM-based judge to score candidate narratives across clinically grounded dimensions, enabling consistent and comprehensive evaluation of multimodal models. For individual case assessment, we train DermEval, a reference-free multimodal evaluator. Given an image and a generated narrative, DermEval produces a structured critique along with an overall score and per-dimension ratings. This capability enables fine-grained, per-case analysis, which is critical for identifying model limitations and biases. Experiments on a diverse dataset of 4,500 cases demonstrate that DermBench and DermEval achieve close alignment with expert ratings, with mean deviations of 0.251 and 0.117 (out of 5), respectively, providing reliable measurement of diagnostic ability and trustworthiness across different multimodal LLMs.
GaRe: Relightable 3D Gaussian Splatting for Outdoor Scenes from Unconstrained Photo Collections
Jul 28, 2025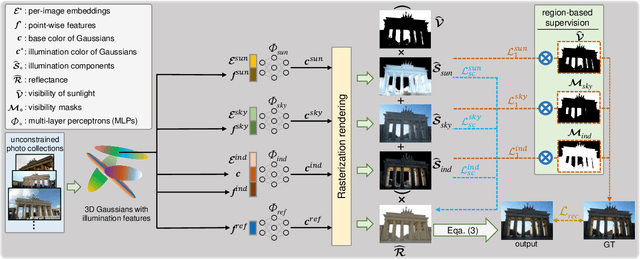

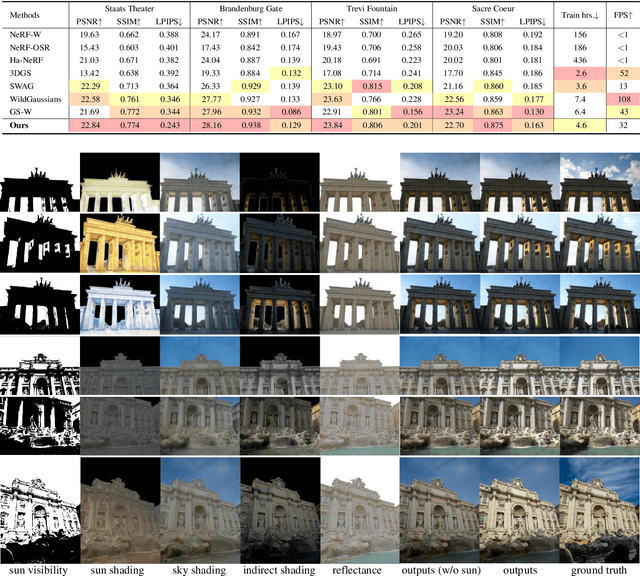

We propose a 3D Gaussian splatting-based framework for outdoor relighting that leverages intrinsic image decomposition to precisely integrate sunlight, sky radiance, and indirect lighting from unconstrained photo collections. Unlike prior methods that compress the per-image global illumination into a single latent vector, our approach enables simultaneously diverse shading manipulation and the generation of dynamic shadow effects. This is achieved through three key innovations: (1) a residual-based sun visibility extraction method to accurately separate direct sunlight effects, (2) a region-based supervision framework with a structural consistency loss for physically interpretable and coherent illumination decomposition, and (3) a ray-tracing-based technique for realistic shadow simulation. Extensive experiments demonstrate that our framework synthesizes novel views with competitive fidelity against state-of-the-art relighting solutions and produces more natural and multifaceted illumination and shadow effects.