 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
FlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation
Aug 26, 2025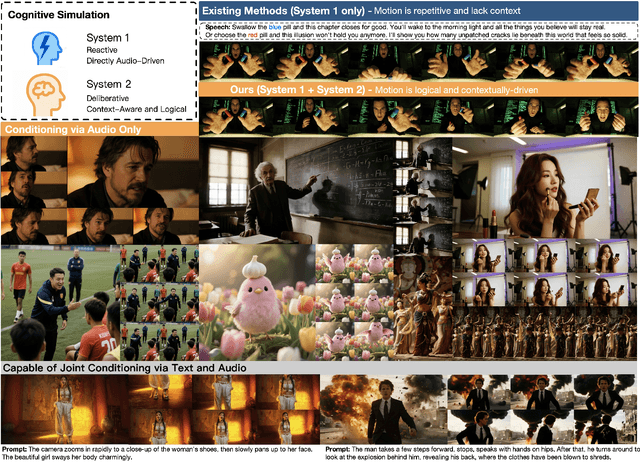
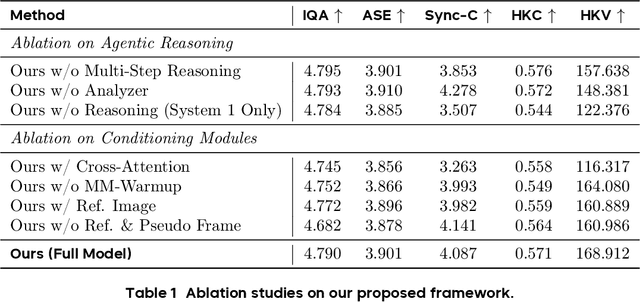
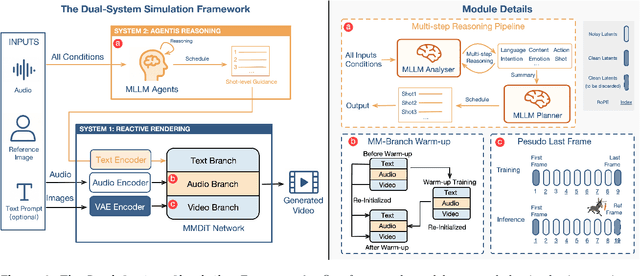

Existing video avatar models can produce fluid human animations, yet they struggle to move beyond mere physical likeness to capture a character's authentic essence. Their motions typically synchronize with low-level cues like audio rhythm, lacking a deeper semantic understanding of emotion, intent, or context. To bridge this gap, \textbf{we propose a framework designed to generate character animations that are not only physically plausible but also semantically coherent and expressive.} Our model, \textbf{OmniHuman-1.5}, is built upon two key technical contributions. First, we leverage Multimodal Large Language Models to synthesize a structured textual representation of conditions that provides high-level semantic guidance. This guidance steers our motion generator beyond simplistic rhythmic synchronization, enabling the production of actions that are contextually and emotionally resonant. Second, to ensure the effective fusion of these multimodal inputs and mitigate inter-modality conflicts, we introduce a specialized Multimodal DiT architecture with a novel Pseudo Last Frame design. The synergy of these components allows our model to accurately interpret the joint semantics of audio, images, and text, thereby generating motions that are deeply coherent with the character, scene, and linguistic content. Extensive experiments demonstrate that our model achieves leading performance across a comprehensive set of metrics, including lip-sync accuracy, video quality, motion naturalness and semantic consistency with textual prompts. Furthermore, our approach shows remarkable extensibility to complex scenarios, such as those involving multi-person and non-human subjects. Homepage: \href{https://omnihuman-lab.github.io/v1_5/}
DreamActor-H1: High-Fidelity Human-Product Demonstration Video Generation via Motion-designed Diffusion Transformers
Jun 12, 2025In e-commerce and digital marketing, generating high-fidelity human-product demonstration videos is important for effective product presentation. However, most existing frameworks either fail to preserve the identities of both humans and products or lack an understanding of human-product spatial relationships, leading to unrealistic representations and unnatural interactions. To address these challenges, we propose a Diffusion Transformer (DiT)-based framework. Our method simultaneously preserves human identities and product-specific details, such as logos and textures, by injecting paired human-product reference information and utilizing an additional masked cross-attention mechanism. We employ a 3D body mesh template and product bounding boxes to provide precise motion guidance, enabling intuitive alignment of hand gestures with product placements. Additionally, structured text encoding is used to incorporate category-level semantics, enhancing 3D consistency during small rotational changes across frames. Trained on a hybrid dataset with extensive data augmentation strategies, our approach outperforms state-of-the-art techniques in maintaining the identity integrity of both humans and products and generating realistic demonstration motions. Project page: https://submit2025-dream.github.io/DreamActor-H1/.
InterActHuman: Multi-Concept Human Animation with Layout-Aligned Audio Conditions
Jun 11, 2025



End-to-end human animation with rich multi-modal conditions, e.g., text, image and audio has achieved remarkable advancements in recent years. However, most existing methods could only animate a single subject and inject conditions in a global manner, ignoring scenarios that multiple concepts could appears in the same video with rich human-human interactions and human-object interactions. Such global assumption prevents precise and per-identity control of multiple concepts including humans and objects, therefore hinders applications. In this work, we discard the single-entity assumption and introduce a novel framework that enforces strong, region-specific binding of conditions from modalities to each identity's spatiotemporal footprint. Given reference images of multiple concepts, our method could automatically infer layout information by leveraging a mask predictor to match appearance cues between the denoised video and each reference appearance. Furthermore, we inject local audio condition into its corresponding region to ensure layout-aligned modality matching in a iterative manner. This design enables the high-quality generation of controllable multi-concept human-centric videos. Empirical results and ablation studies validate the effectiveness of our explicit layout control for multi-modal conditions compared to implicit counterparts and other existing methods.
OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
Feb 03, 2025End-to-end human animation, such as audio-driven talking human generation, has undergone notable advancements in the recent few years. However, existing methods still struggle to scale up as large general video generation models, limiting their potential in real applications. In this paper, we propose OmniHuman, a Diffusion Transformer-based framework that scales up data by mixing motion-related conditions into the training phase. To this end, we introduce two training principles for these mixed conditions, along with the corresponding model architecture and inference strategy. These designs enable OmniHuman to fully leverage data-driven motion generation, ultimately achieving highly realistic human video generation. More importantly, OmniHuman supports various portrait contents (face close-up, portrait, half-body, full-body), supports both talking and singing, handles human-object interactions and challenging body poses, and accommodates different image styles. Compared to existing end-to-end audio-driven methods, OmniHuman not only produces more realistic videos, but also offers greater flexibility in inputs. It also supports multiple driving modalities (audio-driven, video-driven and combined driving signals). Video samples are provided on the ttfamily project page (https://omnihuman-lab.github.io)
3D Gaussian Parametric Head Model
Jul 21, 2024



Creating high-fidelity 3D human head avatars is crucial for applications in VR/AR, telepresence, digital human interfaces, and film production. Recent advances have leveraged morphable face models to generate animated head avatars from easily accessible data, representing varying identities and expressions within a low-dimensional parametric space. However, existing methods often struggle with modeling complex appearance details, e.g., hairstyles and accessories, and suffer from low rendering quality and efficiency. This paper introduces a novel approach, 3D Gaussian Parametric Head Model, which employs 3D Gaussians to accurately represent the complexities of the human head, allowing precise control over both identity and expression. Additionally, it enables seamless face portrait interpolation and the reconstruction of detailed head avatars from a single image. Unlike previous methods, the Gaussian model can handle intricate details, enabling realistic representations of varying appearances and complex expressions. Furthermore, this paper presents a well-designed training framework to ensure smooth convergence, providing a guarantee for learning the rich content. Our method achieves high-quality, photo-realistic rendering with real-time efficiency, making it a valuable contribution to the field of parametric head models.
MeshAvatar: Learning High-quality Triangular Human Avatars from Multi-view Videos
Jul 11, 2024



We present a novel pipeline for learning high-quality triangular human avatars from multi-view videos. Recent methods for avatar learning are typically based on neural radiance fields (NeRF), which is not compatible with traditional graphics pipeline and poses great challenges for operations like editing or synthesizing under different environments. To overcome these limitations, our method represents the avatar with an explicit triangular mesh extracted from an implicit SDF field, complemented by an implicit material field conditioned on given poses. Leveraging this triangular avatar representation, we incorporate physics-based rendering to accurately decompose geometry and texture. To enhance both the geometric and appearance details, we further employ a 2D UNet as the network backbone and introduce pseudo normal ground-truth as additional supervision. Experiments show that our method can learn triangular avatars with high-quality geometry reconstruction and plausible material decomposition, inherently supporting editing, manipulation or relighting operations.
Human4DiT: Free-view Human Video Generation with 4D Diffusion Transformer
May 27, 2024



We present a novel approach for generating high-quality, spatio-temporally coherent human videos from a single image under arbitrary viewpoints. Our framework combines the strengths of U-Nets for accurate condition injection and diffusion transformers for capturing global correlations across viewpoints and time. The core is a cascaded 4D transformer architecture that factorizes attention across views, time, and spatial dimensions, enabling efficient modeling of the 4D space. Precise conditioning is achieved by injecting human identity, camera parameters, and temporal signals into the respective transformers. To train this model, we curate a multi-dimensional dataset spanning images, videos, multi-view data and 3D/4D scans, along with a multi-dimensional training strategy. Our approach overcomes the limitations of previous methods based on GAN or UNet-based diffusion models, which struggle with complex motions and viewpoint changes. Through extensive experiments, we demonstrate our method's ability to synthesize realistic, coherent and free-view human videos, paving the way for advanced multimedia applications in areas such as virtual reality and animation. Our project website is https://human4dit.github.io.
LayGA: Layered Gaussian Avatars for Animatable Clothing Transfer
May 12, 2024



Animatable clothing transfer, aiming at dressing and animating garments across characters, is a challenging problem. Most human avatar works entangle the representations of the human body and clothing together, which leads to difficulties for virtual try-on across identities. What's worse, the entangled representations usually fail to exactly track the sliding motion of garments. To overcome these limitations, we present Layered Gaussian Avatars (LayGA), a new representation that formulates body and clothing as two separate layers for photorealistic animatable clothing transfer from multi-view videos. Our representation is built upon the Gaussian map-based avatar for its excellent representation power of garment details. However, the Gaussian map produces unstructured 3D Gaussians distributed around the actual surface. The absence of a smooth explicit surface raises challenges in accurate garment tracking and collision handling between body and garments. Therefore, we propose two-stage training involving single-layer reconstruction and multi-layer fitting. In the single-layer reconstruction stage, we propose a series of geometric constraints to reconstruct smooth surfaces and simultaneously obtain the segmentation between body and clothing. Next, in the multi-layer fitting stage, we train two separate models to represent body and clothing and utilize the reconstructed clothing geometries as 3D supervision for more accurate garment tracking. Furthermore, we propose geometry and rendering layers for both high-quality geometric reconstruction and high-fidelity rendering. Overall, the proposed LayGA realizes photorealistic animations and virtual try-on, and outperforms other baseline methods. Our project page is https://jsnln.github.io/layga/index.html.