 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSapientML: Synthesizing Machine Learning Pipelines by Learning from Human-Written Solutions
Feb 18, 2022
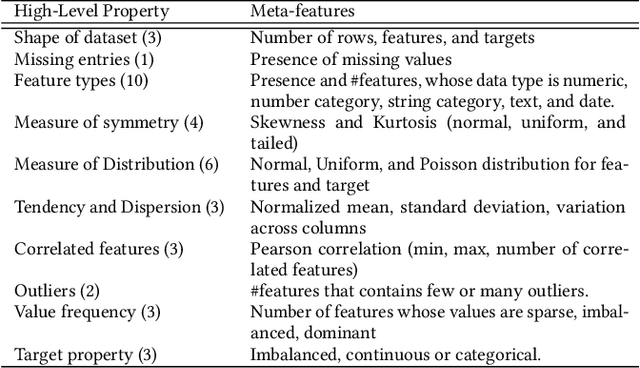

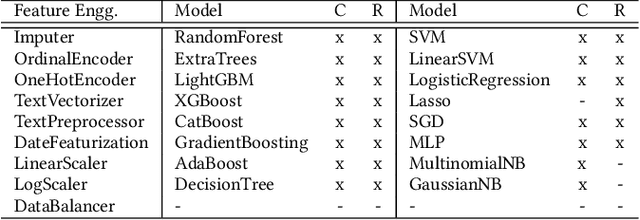
Automatic machine learning, or AutoML, holds the promise of truly democratizing the use of machine learning (ML), by substantially automating the work of data scientists. However, the huge combinatorial search space of candidate pipelines means that current AutoML techniques, generate sub-optimal pipelines, or none at all, especially on large, complex datasets. In this work we propose an AutoML technique SapientML, that can learn from a corpus of existing datasets and their human-written pipelines, and efficiently generate a high-quality pipeline for a predictive task on a new dataset. To combat the search space explosion of AutoML, SapientML employs a novel divide-and-conquer strategy realized as a three-stage program synthesis approach, that reasons on successively smaller search spaces. The first stage uses a machine-learned model to predict a set of plausible ML components to constitute a pipeline. In the second stage, this is then refined into a small pool of viable concrete pipelines using syntactic constraints derived from the corpus and the machine-learned model. Dynamically evaluating these few pipelines, in the third stage, provides the best solution. We instantiate SapientML as part of a fully automated tool-chain that creates a cleaned, labeled learning corpus by mining Kaggle, learns from it, and uses the learned models to then synthesize pipelines for new predictive tasks. We have created a training corpus of 1094 pipelines spanning 170 datasets, and evaluated SapientML on a set of 41 benchmark datasets, including 10 new, large, real-world datasets from Kaggle, and against 3 state-of-the-art AutoML tools and 2 baselines. Our evaluation shows that SapientML produces the best or comparable accuracy on 27 of the benchmarks while the second best tool fails to even produce a pipeline on 9 of the instances.
AdaPrompt: Adaptive Model Training for Prompt-based NLP
Feb 10, 2022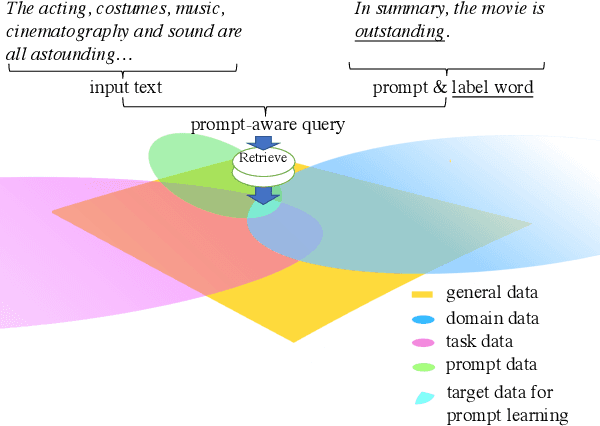

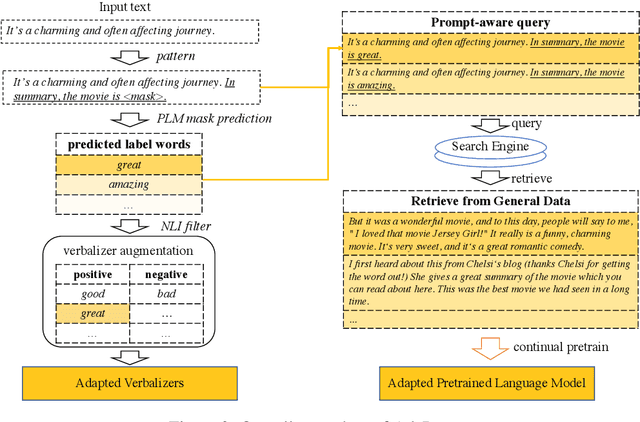
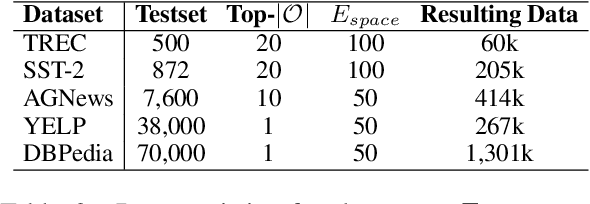
Prompt-based learning, with its capability to tackle zero-shot and few-shot NLP tasks, has gained much attention in community. The main idea is to bridge the gap between NLP downstream tasks and language modeling (LM), by mapping these tasks into natural language prompts, which are then filled by pre-trained language models (PLMs). However, for prompt learning, there are still two salient gaps between NLP tasks and pretraining. First, prompt information is not necessarily sufficiently present during LM pretraining. Second, task-specific data are not necessarily well represented during pretraining. We address these two issues by proposing AdaPrompt, adaptively retrieving external data for continual pretraining of PLMs by making use of both task and prompt characteristics. In addition, we make use of knowledge in Natural Language Inference models for deriving adaptive verbalizers. Experimental results on five NLP benchmarks show that AdaPrompt can improve over standard PLMs in few-shot settings. In addition, in zero-shot settings, our method outperforms standard prompt-based methods by up to 26.35\% relative error reduction.
Unsupervised Summarization with Customized Granularities
Jan 29, 2022
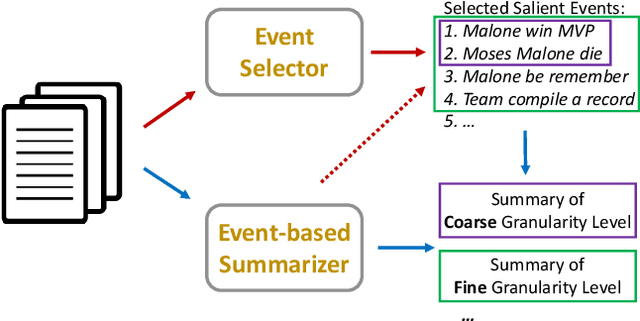


Text summarization is a personalized and customized task, i.e., for one document, users often have different preferences for the summary. As a key aspect of customization in summarization, granularity is used to measure the semantic coverage between summary and source document. Coarse-grained summaries can only contain the most central event in the original text, while fine-grained summaries cover more sub-events and corresponding details. However, previous studies mostly develop systems in the single-granularity scenario. And models that can generate summaries with customizable semantic coverage still remain an under-explored topic. In this paper, we propose the first unsupervised multi-granularity summarization framework, GranuSum. We take events as the basic semantic units of the source documents and propose to rank these events by their salience. We also develop a model to summarize input documents with given events as anchors and hints. By inputting different numbers of events, GranuSum is capable of producing multi-granular summaries in an unsupervised manner. Meanwhile, to evaluate multi-granularity summarization models, we annotate a new benchmark GranuDUC, in which we write multiple summaries of different granularities for each document cluster. Experimental results confirm the substantial superiority of GranuSum on multi-granularity summarization over several baseline systems. Furthermore, by experimenting on conventional unsupervised abstractive summarization tasks, we find that GranuSum, by exploiting the event information, can also achieve new state-of-the-art results under this scenario, outperforming strong baselines.
CLIP-Event: Connecting Text and Images with Event Structures
Jan 13, 2022
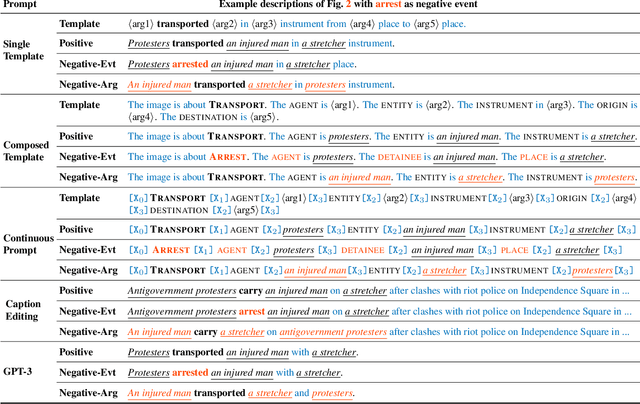
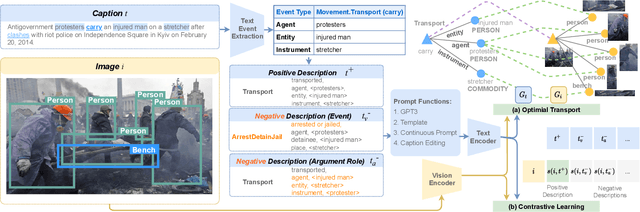

Vision-language (V+L) pretraining models have achieved great success in supporting multimedia applications by understanding the alignments between images and text. While existing vision-language pretraining models primarily focus on understanding objects in images or entities in text, they often ignore the alignment at the level of events and their argument structures. % In this work, we propose a contrastive learning framework to enforce vision-language pretraining models to comprehend events and associated argument (participant) roles. To achieve this, we take advantage of text information extraction technologies to obtain event structural knowledge, and utilize multiple prompt functions to contrast difficult negative descriptions by manipulating event structures. We also design an event graph alignment loss based on optimal transport to capture event argument structures. In addition, we collect a large event-rich dataset (106,875 images) for pretraining, which provides a more challenging image retrieval benchmark to assess the understanding of complicated lengthy sentences. Experiments show that our zero-shot CLIP-Event outperforms the state-of-the-art supervised model in argument extraction on Multimedia Event Extraction, achieving more than 5\% absolute F-score gain in event extraction, as well as significant improvements on a variety of downstream tasks under zero-shot settings.
Human Parity on CommonsenseQA: Augmenting Self-Attention with External Attention
Dec 14, 2021
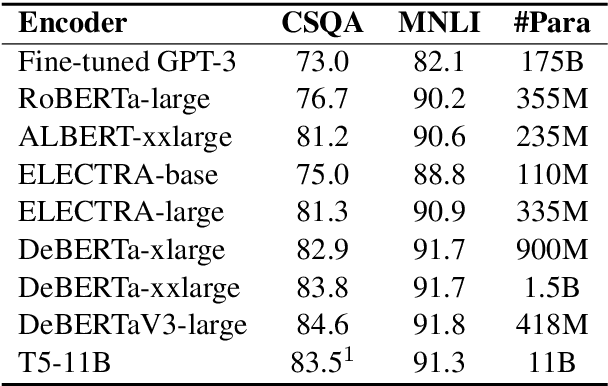
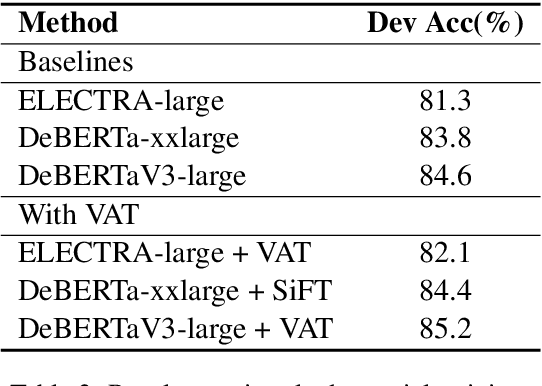

Most of today's AI systems focus on using self-attention mechanisms and transformer architectures on large amounts of diverse data to achieve impressive performance gains. In this paper, we propose to augment the transformer architecture with an external attention mechanism to bring external knowledge and context to bear. By integrating external information into the prediction process, we hope to reduce the need for ever-larger models and increase the democratization of AI systems. We find that the proposed external attention mechanism can significantly improve the performance of existing AI systems, allowing practitioners to easily customize foundation AI models to many diverse downstream applications. In particular, we focus on the task of Commonsense Reasoning, demonstrating that the proposed external attention mechanism can augment existing transformer models and significantly improve the model's reasoning capabilities. The proposed system, Knowledgeable External Attention for commonsense Reasoning (KEAR), reaches human parity on the open CommonsenseQA research benchmark with an accuracy of 89.4\% in comparison to the human accuracy of 88.9\%.
MLP Architectures for Vision-and-Language Modeling: An Empirical Study
Dec 08, 2021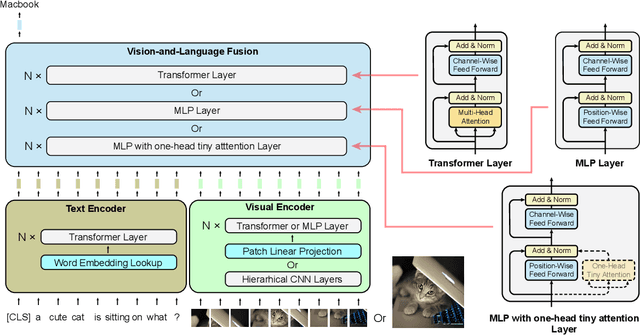
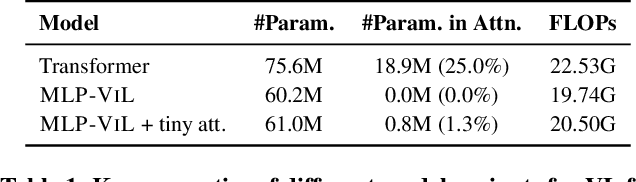
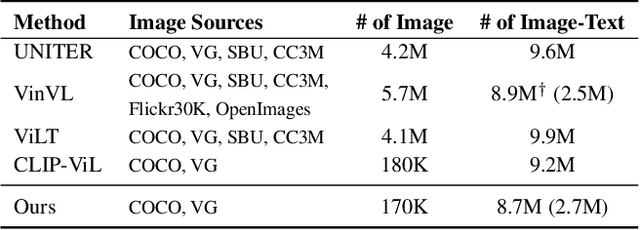
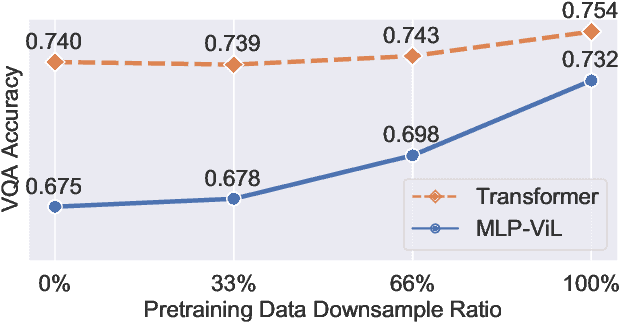
We initiate the first empirical study on the use of MLP architectures for vision-and-language (VL) fusion. Through extensive experiments on 5 VL tasks and 5 robust VQA benchmarks, we find that: (i) Without pre-training, using MLPs for multimodal fusion has a noticeable performance gap compared to transformers; (ii) However, VL pre-training can help close the performance gap; (iii) Instead of heavy multi-head attention, adding tiny one-head attention to MLPs is sufficient to achieve comparable performance to transformers. Moreover, we also find that the performance gap between MLPs and transformers is not widened when being evaluated on the harder robust VQA benchmarks, suggesting using MLPs for VL fusion can generalize roughly to a similar degree as using transformers. These results hint that MLPs can effectively learn to align vision and text features extracted from lower-level encoders without heavy reliance on self-attention. Based on this, we ask an even bolder question: can we have an all-MLP architecture for VL modeling, where both VL fusion and the vision encoder are replaced with MLPs? Our result shows that an all-MLP VL model is sub-optimal compared to state-of-the-art full-featured VL models when both of them get pre-trained. However, pre-training an all-MLP can surprisingly achieve a better average score than full-featured transformer models without pre-training. This indicates the potential of large-scale pre-training of MLP-like architectures for VL modeling and inspires the future research direction on simplifying well-established VL modeling with less inductive design bias. Our code is publicly available at: https://github.com/easonnie/mlp-vil
An Empirical Study of Training End-to-End Vision-and-Language Transformers
Nov 25, 2021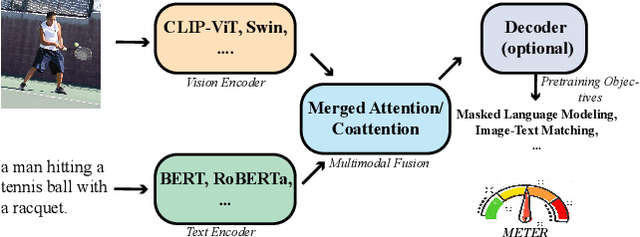

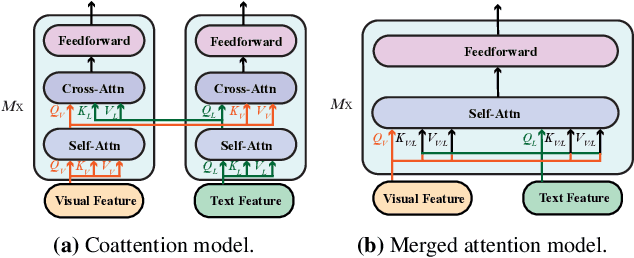

Vision-and-language (VL) pre-training has proven to be highly effective on various VL downstream tasks. While recent work has shown that fully transformer-based VL models can be more efficient than previous region-feature-based methods, their performance on downstream tasks often degrades significantly. In this paper, we present METER, a Multimodal End-to-end TransformER framework, through which we investigate how to design and pre-train a fully transformer-based VL model in an end-to-end manner. Specifically, we dissect the model designs along multiple dimensions: vision encoders (e.g., CLIPViT, Swin transformer), text encoders (e.g., RoBERTa, DeBERTa), multimodal fusion module (e.g., merged attention vs. co-attention), architectural design (e.g., encoder-only vs. encoder-decoder), and pre-training objectives (e.g., masked image modeling). We conduct comprehensive experiments and provide insights on how to train a performant VL transformer while maintaining fast inference speed. Notably, our best model achieves an accuracy of 77.64% on the VQAv2 test-std set using only 4M images for pre-training, surpassing the state-of-the-art region-feature-based model by 1.04%, and outperforming the previous best fully transformer-based model by 1.6%. Code and models are released at https://github.com/zdou0830/METER.
SYNERGY: Building Task Bots at Scale Using Symbolic Knowledge and Machine Teaching
Oct 21, 2021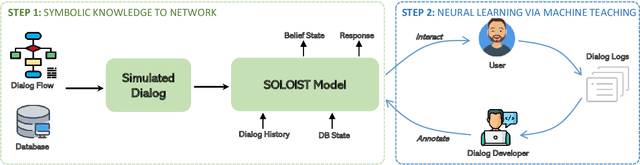

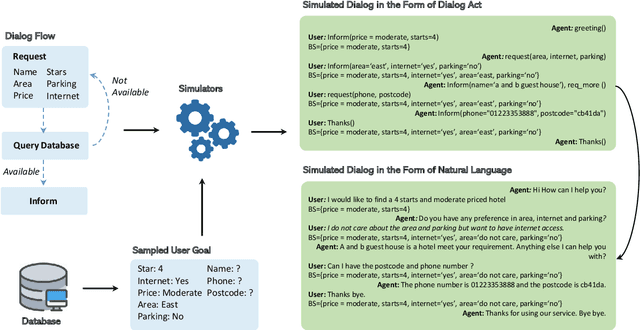
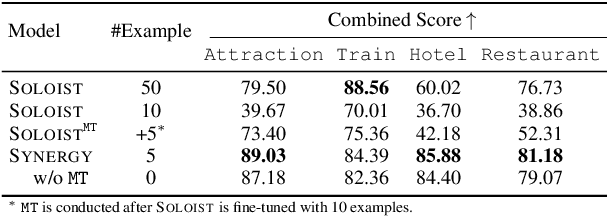
In this paper we explore the use of symbolic knowledge and machine teaching to reduce human data labeling efforts in building neural task bots. We propose SYNERGY, a hybrid learning framework where a task bot is developed in two steps: (i) Symbolic knowledge to neural networks: Large amounts of simulated dialog sessions are generated based on task-specific symbolic knowledge which is represented as a task schema consisting of dialog flows and task-oriented databases. Then a pre-trained neural dialog model, SOLOIST, is fine-tuned on the simulated dialogs to build a bot for the task. (ii) Neural learning: The fine-tuned neural dialog model is continually refined with a handful of real task-specific dialogs via machine teaching, where training samples are generated by human teachers interacting with the task bot. We validate SYNERGY on four dialog tasks. Experimental results show that SYNERGY maps task-specific knowledge into neural dialog models achieving greater diversity and coverage of dialog flows, and continually improves model performance with machine teaching, thus demonstrating strong synergistic effects of symbolic knowledge and machine teaching.
Summ^N: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents
Oct 16, 2021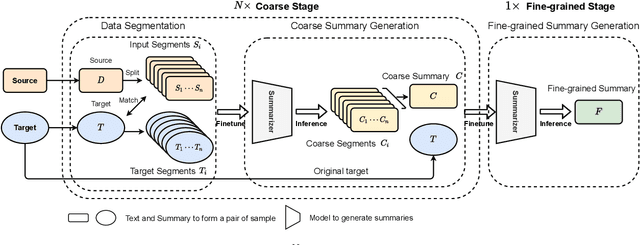
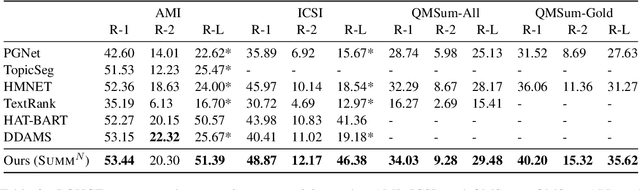
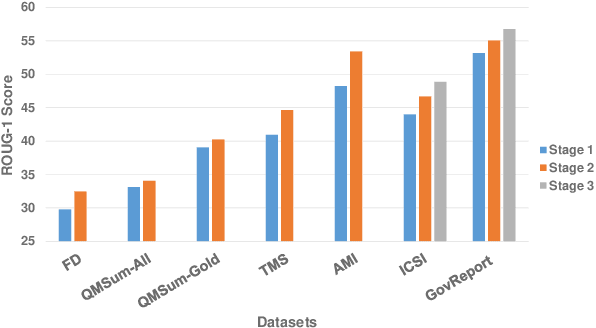
Text summarization is an essential task to help readers capture salient information from documents, news, interviews, and meetings. However, most state-of-the-art pretrained language models are unable to efficiently process long text commonly seen in the summarization problem domain. In this paper, we propose Summ^N, a simple, flexible, and effective multi-stage framework for input texts that are longer than the maximum context lengths of typical pretrained LMs. Summ^N first generates the coarse summary in multiple stages and then produces the final fine-grained summary based on them. The framework can process input text of arbitrary length by adjusting the number of stages while keeping the LM context size fixed. Moreover, it can deal with both documents and dialogues and can be used on top of any underlying backbone abstractive summarization model. Our experiments demonstrate that Summ^N significantly outperforms previous state-of-the-art methods by improving ROUGE scores on three long meeting summarization datasets AMI, ICSI, and QMSum, two long TV series datasets from SummScreen, and a newly proposed long document summarization dataset GovReport. Our data and code are available at https://github.com/chatc/Summ-N.
Leveraging Knowledge in Multilingual Commonsense Reasoning
Oct 16, 2021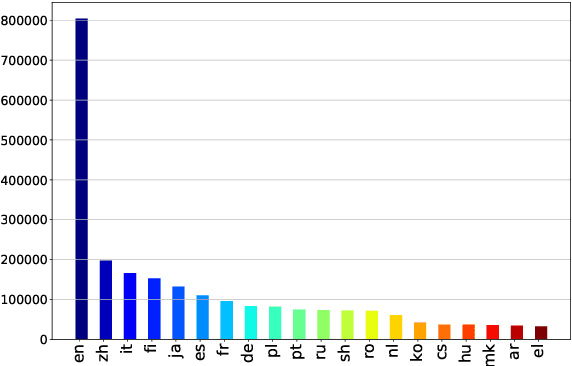

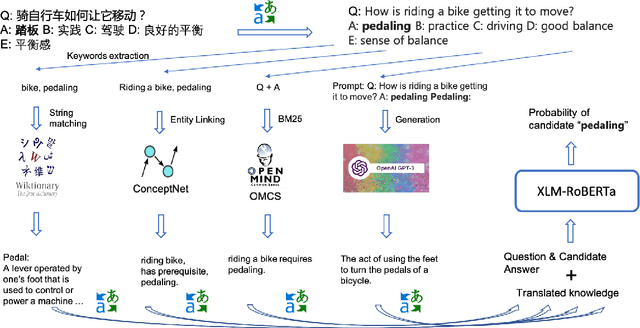
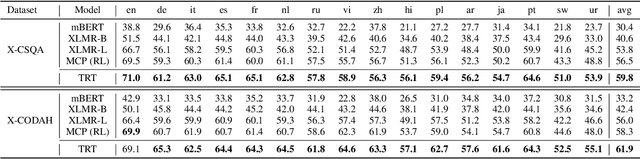
Commonsense reasoning (CSR) requires the model to be equipped with general world knowledge. While CSR is a language-agnostic process, most comprehensive knowledge sources are in few popular languages, especially English. Thus, it remains unclear how to effectively conduct multilingual commonsense reasoning (XCSR) for various languages. In this work, we propose to utilize English knowledge sources via a translate-retrieve-translate (TRT) strategy. For multilingual commonsense questions and choices, we collect related knowledge via translation and retrieval from the knowledge sources. The retrieved knowledge is then translated into the target language and integrated into a pre-trained multilingual language model via visible knowledge attention. Then we utilize a diverse of 4 English knowledge sources to provide more comprehensive coverage of knowledge in different formats. Extensive results on the XCSR benchmark demonstrate that TRT with external knowledge can significantly improve multilingual commonsense reasoning in both zero-shot and translate-train settings, outperforming 3.3 and 3.6 points over the previous state-of-the-art on XCSR benchmark datasets (X-CSQA and X-CODAH).