 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structured Reasoning via Tractable Trajectory Control
Mar 02, 2026Large language models can exhibit emergent reasoning behaviors, often manifested as recurring lexical patterns (e.g., "wait," indicating verification). However, complex reasoning trajectories remain sparse in unconstrained sampling, and standard RL often fails to guarantee the acquisition of diverse reasoning behaviors. We propose a systematic discovery and reinforcement of diverse reasoning patterns through structured reasoning, a paradigm that requires targeted exploration of specific reasoning patterns during the RL process. To this end, we propose Ctrl-R, a framework for learning structured reasoning via tractable trajectory control that actively guides the rollout process, incentivizing the exploration of diverse reasoning patterns that are critical for complex problem-solving. The resulting behavior policy enables accurate importance-sampling estimation, supporting unbiased on-policy optimization. We further introduce a power-scaling factor on the importance-sampling weights, allowing the policy to selectively learn from exploratory, out-of-distribution trajectories while maintaining stable optimization. Experiments demonstrate that Ctrl-R enables effective exploration and internalization of previously unattainable reasoning patterns, yielding consistent improvements across language and vision-language models on mathematical reasoning tasks.
VaPR -- Vision-language Preference alignment for Reasoning
Oct 02, 2025Preference finetuning methods like Direct Preference Optimization (DPO) with AI-generated feedback have shown promise in aligning Large Vision-Language Models (LVLMs) with human preferences. However, existing techniques overlook the prevalence of noise in synthetic preference annotations in the form of stylistic and length biases. To this end, we introduce a hard-negative response generation framework based on LLM-guided response editing, that produces rejected responses with targeted errors, maintaining stylistic and length similarity to the accepted ones. Using this framework, we develop the VaPR dataset, comprising 30K high-quality samples, to finetune three LVLM families: LLaVA-V1.5, Qwen2VL & Qwen2.5VL (2B-13B sizes). Our VaPR models deliver significant performance improvements across ten benchmarks, achieving average gains of 6.5% (LLaVA), 4.0% (Qwen2VL), and 1.5% (Qwen2.5VL), with notable improvements on reasoning tasks. A scaling analysis shows that performance consistently improves with data size, with LLaVA models benefiting even at smaller scales. Moreover, VaPR reduces the tendency to answer "Yes" in binary questions - addressing a common failure mode in LVLMs like LLaVA. Lastly, we show that the framework generalizes to open-source LLMs as editors, with models trained on VaPR-OS achieving ~99% of the performance of models trained on \name, which is synthesized using GPT-4o. Our data, models, and code can be found on the project page https://vap-r.github.io
Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025



Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
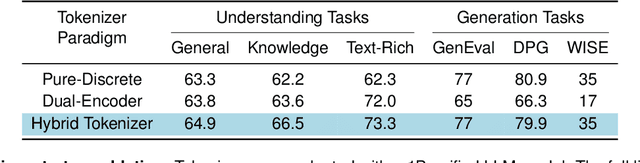
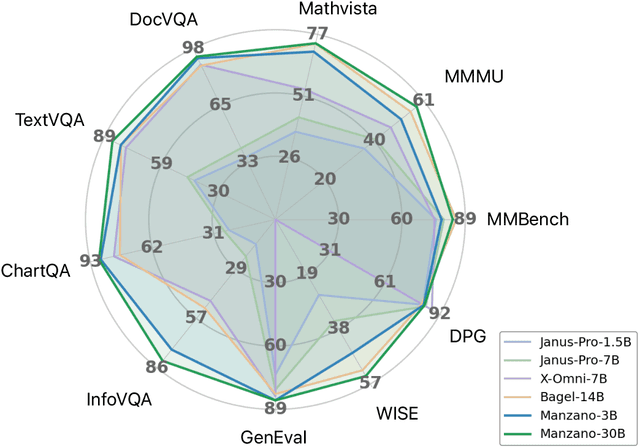
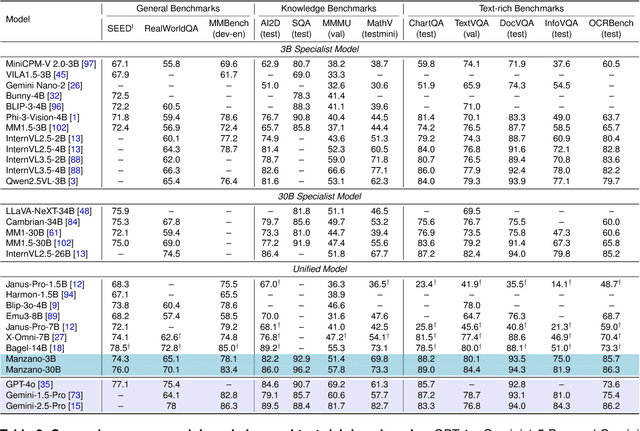
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
MRAG-Bench: Vision-Centric Evaluation for Retrieval-Augmented Multimodal Models
Oct 10, 2024Existing multimodal retrieval benchmarks primarily focus on evaluating whether models can retrieve and utilize external textual knowledge for question answering. However, there are scenarios where retrieving visual information is either more beneficial or easier to access than textual data. In this paper, we introduce a multimodal retrieval-augmented generation benchmark, MRAG-Bench, in which we systematically identify and categorize scenarios where visually augmented knowledge is better than textual knowledge, for instance, more images from varying viewpoints. MRAG-Bench consists of 16,130 images and 1,353 human-annotated multiple-choice questions across 9 distinct scenarios. With MRAG-Bench, we conduct an evaluation of 10 open-source and 4 proprietary large vision-language models (LVLMs). Our results show that all LVLMs exhibit greater improvements when augmented with images compared to textual knowledge, confirming that MRAG-Bench is vision-centric. Additionally, we conduct extensive analysis with MRAG-Bench, which offers valuable insights into retrieval-augmented LVLMs. Notably, the top-performing model, GPT-4o, faces challenges in effectively leveraging retrieved knowledge, achieving only a 5.82% improvement with ground-truth information, in contrast to a 33.16% improvement observed in human participants. These findings highlight the importance of MRAG-Bench in encouraging the community to enhance LVLMs' ability to utilize retrieved visual knowledge more effectively.
Unlocking Exocentric Video-Language Data for Egocentric Video Representation Learning
Aug 07, 2024We present EMBED (Egocentric Models Built with Exocentric Data), a method designed to transform exocentric video-language data for egocentric video representation learning. Large-scale exocentric data covers diverse activities with significant potential for egocentric learning, but inherent disparities between egocentric and exocentric data pose challenges in utilizing one view for the other seamlessly. Egocentric videos predominantly feature close-up hand-object interactions, whereas exocentric videos offer a broader perspective on human activities. Additionally, narratives in egocentric datasets are typically more action-centric and closely linked with the visual content, in contrast to the narrative styles found in exocentric datasets. To address these challenges, we employ a data transformation framework to adapt exocentric data for egocentric training, focusing on identifying specific video clips that emphasize hand-object interactions and transforming narration styles to align with egocentric perspectives. By applying both vision and language style transfer, our framework creates a new egocentric dataset derived from exocentric video-language data. Through extensive evaluations, we demonstrate the effectiveness of EMBED, achieving state-of-the-art results across various egocentric downstream tasks, including an absolute improvement of 4.7% on the Epic-Kitchens-100 multi-instance retrieval and 6.2% on the EGTEA classification benchmarks in zero-shot settings. Furthermore, EMBED enables egocentric video-language models to perform competitively in exocentric tasks. Finally, we showcase EMBED's application across various exocentric datasets, exhibiting strong generalization capabilities when applied to different exocentric datasets.
Reflection-Reinforced Self-Training for Language Agents
Jun 03, 2024



Self-training can potentially improve the performance of language agents without relying on demonstrations from humans or stronger models. The general process involves generating samples from a model, evaluating their quality, and updating the model by training on high-quality samples. However, self-training can face limitations because achieving good performance requires a good amount of high-quality samples, yet relying solely on model sampling for obtaining such samples can be inefficient. In addition, these methods often disregard low-quality samples, failing to leverage them effectively. To address these limitations, we present Reflection-Reinforced Self-Training (Re-ReST), which leverages a reflection model to refine low-quality samples and subsequently uses these improved samples to augment self-training. The reflection model takes both the model output and feedback from an external environment (e.g., unit test results in code generation) as inputs and produces improved samples as outputs. By employing this technique, we effectively enhance the quality of inferior samples, and enrich the self-training dataset with higher-quality samples efficiently. We perform extensive experiments on open-source language agents across tasks, including multi-hop question answering, sequential decision-making, code generation, visual question answering, and text-to-image generation. Results demonstrate improvements over self-training baselines across settings. Moreover, ablation studies confirm the reflection model's efficiency in generating quality self-training samples and its compatibility with self-consistency decoding.
Matryoshka Query Transformer for Large Vision-Language Models
May 29, 2024Large Vision-Language Models (LVLMs) typically encode an image into a fixed number of visual tokens (e.g., 576) and process these tokens with a language model. Despite their strong performance, LVLMs face challenges in adapting to varying computational constraints. This raises the question: can we achieve flexibility in the number of visual tokens to suit different tasks and computational resources? We answer this with an emphatic yes. Inspired by Matryoshka Representation Learning, we introduce the Matryoshka Query Transformer (MQT), capable of encoding an image into m visual tokens during inference, where m can be any number up to a predefined maximum. This is achieved by employing a query transformer with M latent query tokens to compress the visual embeddings. During each training step, we randomly select m <= M latent query tokens and train the model using only these first m tokens, discarding the rest. Combining MQT with LLaVA, we train a single model once, and flexibly and drastically reduce the number of inference-time visual tokens while maintaining similar or better performance compared to training independent models for each number of tokens. Our model, MQT-LLAVA, matches LLaVA-1.5 performance across 11 benchmarks using a maximum of 256 tokens instead of LLaVA's fixed 576. Reducing to 16 tokens (8x less TFLOPs) only sacrifices the performance by 2.4 points on MMBench. On certain tasks such as ScienceQA and MMMU, we can even go down to only 2 visual tokens with performance drops of just 3% and 6% each. Our exploration of the trade-off between the accuracy and computational cost brought about by the number of visual tokens facilitates future research to achieve the best of both worlds.
Medical Vision-Language Pre-Training for Brain Abnormalities
Apr 27, 2024



Vision-language models have become increasingly powerful for tasks that require an understanding of both visual and linguistic elements, bridging the gap between these modalities. In the context of multimodal clinical AI, there is a growing need for models that possess domain-specific knowledge, as existing models often lack the expertise required for medical applications. In this paper, we take brain abnormalities as an example to demonstrate how to automatically collect medical image-text aligned data for pretraining from public resources such as PubMed. In particular, we present a pipeline that streamlines the pre-training process by initially collecting a large brain image-text dataset from case reports and published journals and subsequently constructing a high-performance vision-language model tailored to specific medical tasks. We also investigate the unique challenge of mapping subfigures to subcaptions in the medical domain. We evaluated the resulting model with quantitative and qualitative intrinsic evaluations. The resulting dataset and our code can be found here https://github.com/masoud-monajati/MedVL_pretraining_pipeline
VALOR-EVAL: Holistic Coverage and Faithfulness Evaluation of Large Vision-Language Models
Apr 22, 2024Large Vision-Language Models (LVLMs) suffer from hallucination issues, wherein the models generate plausible-sounding but factually incorrect outputs, undermining their reliability. A comprehensive quantitative evaluation is necessary to identify and understand the extent of hallucinations in these models. However, existing benchmarks are often limited in scope, focusing mainly on object hallucinations. Furthermore, current evaluation methods struggle to effectively address the subtle semantic distinctions between model outputs and reference data, as well as the balance between hallucination and informativeness. To address these issues, we introduce a multi-dimensional benchmark covering objects, attributes, and relations, with challenging images selected based on associative biases. Moreover, we propose an large language model (LLM)-based two-stage evaluation framework that generalizes the popular CHAIR metric and incorporates both faithfulness and coverage into the evaluation. Experiments on 10 established LVLMs demonstrate that our evaluation metric is more comprehensive and better correlated with humans than existing work when evaluating on our challenging human annotated benchmark dataset. Our work also highlights the critical balance between faithfulness and coverage of model outputs, and encourages future works to address hallucinations in LVLMs while keeping their outputs informative.