 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
ReMoE: Boosting Expert Reuse through Router Fine-Tuning in Memory-Constrained MoE LLM Inference
May 26, 2026Fine-grained Mixture-of-Experts (MoE) models sparsely activate only a subset of experts per token, reducing activated computation while maintaining high model capacity. However, in memory-constrained inference scenarios, only a small set of experts can be cached. Experts not in the cache must be fetched from slow external storage (e.g., UFS), leading to frequent evictions and substantial I/O overhead. We propose ReMoE, a router fine-tuning framework designed to boost token-wise expert reuse. ReMoE biases the router toward recently selected experts, producing temporally stable routing that better matches cache locality constraints. By increasing short-horizon expert reuse, ReMoE reduces expert fetches from storage without adding inference-time computation. Experiments on DeepSeek and Qwen models show that ReMoE improves expert reuse by 26% while maintaining downstream task performance. Real-system evaluations further confirm these benefits, improving output throughput by 8.4% under vLLM GPU-CPU expert offloading and reducing TPOT by 43.6-49.8% under llama.cpp on Jetson Orin NX, corresponding to a 1.77-1.99$\times$ decode speedup across diverse workloads. Checkpoints and usage instructions are available at https://github.com/BUAA-OSCAR/ReMoE.
Bridging the Know-Act Gap via Task-Level Autoregressive Reasoning
Mar 23, 2026LLMs often generate seemingly valid answers to flawed or ill-posed inputs. This is not due to missing knowledge: under discriminative prompting, the same models can mostly identify such issues, yet fail to reflect this in standard generative responses. This reveals a fundamental know-act gap between discriminative recognition and generative behavior. Prior work largely characterizes this issue in narrow settings, such as math word problems or question answering, with limited focus on how to integrate these two modes. In this work, we present a comprehensive analysis using FaultyScience, a newly constructed large-scale, cross-disciplinary benchmark of faulty scientific questions. We show that the gap is pervasive and stems from token-level autoregression, which entangles task selection (validate vs. answer) with content generation, preventing discriminative knowledge from being utilized. To address this, we propose DeIllusionLLM, a task-level autoregressive framework that explicitly models this decision. Through self-distillation, the model unifies discriminative judgment and generative reasoning within a single backbone. Empirically, DeIllusionLLM substantially reduces answer-despite-error failures under natural prompting while maintaining general reasoning performance, demonstrating that self-distillation is an effective and scalable solution for bridging the discriminative-generative know-act gap
QuantLRM: Quantization of Large Reasoning Models via Fine-Tuning Signals
Jan 31, 2026Weight-only quantization is important for compressing Large Language Models (LLMs). Inspired by the spirit of classical magnitude pruning, we study whether the magnitude of weight updates during reasoning-incentivized fine-tuning can provide valuable signals for quantizing Large Reasoning Models (LRMs). We hypothesize that the smallest and largest weight updates during fine-tuning are more important than those of intermediate magnitude, a phenomenon we term "protecting both ends". Upon hypothesis validation, we introduce QuantLRM, which stands for weight quantization of LRMs via fine-tuning signals. We fit simple restricted quadratic functions on weight updates to protect both ends. By multiplying the average quadratic values with the count of zero weight updates of channels, we compute channel importance that is more effective than using activation or second-order information. We run QuantLRM to quantize various fine-tuned models (including supervised, direct preference optimization, and reinforcement learning fine-tuning) over four reasoning benchmarks (AIME-120, FOLIO, temporal sequences, and GPQA-Diamond) and empirically find that QuantLRM delivers a consistent improvement for LRMs quantization, with an average improvement of 6.55% on a reinforcement learning fine-tuned model. Also supporting non-fine-tuned LRMs, QuantLRM gathers effective signals via pseudo-fine-tuning, which greatly enhances its applicability.
Beyond Randomness: Understand the Order of the Noise in Diffusion
Nov 11, 2025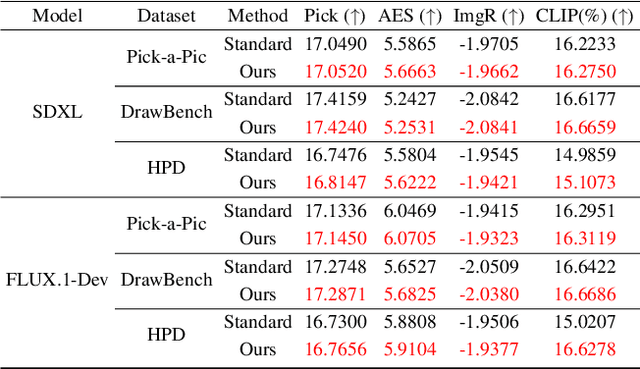
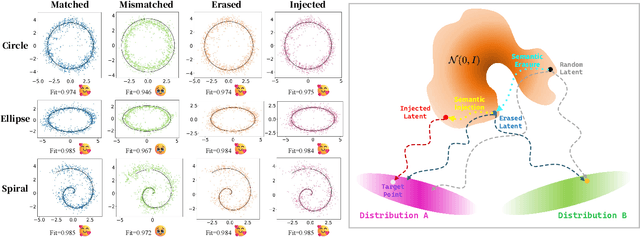


In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.
Break Stylistic Sophon: Are We Really Meant to Confine the Imagination in Style Transfer?
Jun 18, 2025In this pioneering study, we introduce StyleWallfacer, a groundbreaking unified training and inference framework, which not only addresses various issues encountered in the style transfer process of traditional methods but also unifies the framework for different tasks. This framework is designed to revolutionize the field by enabling artist level style transfer and text driven stylization. First, we propose a semantic-based style injection method that uses BLIP to generate text descriptions strictly aligned with the semantics of the style image in CLIP space. By leveraging a large language model to remove style-related descriptions from these descriptions, we create a semantic gap. This gap is then used to fine-tune the model, enabling efficient and drift-free injection of style knowledge. Second, we propose a data augmentation strategy based on human feedback, incorporating high-quality samples generated early in the fine-tuning process into the training set to facilitate progressive learning and significantly reduce its overfitting. Finally, we design a training-free triple diffusion process using the fine-tuned model, which manipulates the features of self-attention layers in a manner similar to the cross-attention mechanism. Specifically, in the generation process, the key and value of the content-related process are replaced with those of the style-related process to inject style while maintaining text control over the model. We also introduce query preservation to mitigate disruptions to the original content. Under such a design, we have achieved high-quality image-driven style transfer and text-driven stylization, delivering artist-level style transfer results while preserving the original image content. Moreover, we achieve image color editing during the style transfer process for the first time.
Enhance Multimodal Consistency and Coherence for Text-Image Plan Generation
Jun 13, 2025People get informed of a daily task plan through diverse media involving both texts and images. However, most prior research only focuses on LLM's capability of textual plan generation. The potential of large-scale models in providing text-image plans remains understudied. Generating high-quality text-image plans faces two main challenges: ensuring consistent alignment between two modalities and keeping coherence among visual steps. To address these challenges, we propose a novel framework that generates and refines text-image plans step-by-step. At each iteration, our framework (1) drafts the next textual step based on the prediction history; (2) edits the last visual step to obtain the next one; (3) extracts PDDL-like visual information; and (4) refines the draft with the extracted visual information. The textual and visual step produced in stage (4) and (2) will then serve as inputs for the next iteration. Our approach offers a plug-and-play improvement to various backbone models, such as Mistral-7B, Gemini-1.5, and GPT-4o. To evaluate the effectiveness of our approach, we collect a new benchmark consisting of 1,100 tasks and their text-image pair solutions covering 11 daily topics. We also design and validate a new set of metrics to evaluate the multimodal consistency and coherence in text-image plans. Extensive experiment results show the effectiveness of our approach on a range of backbone models against competitive baselines. Our code and data are available at https://github.com/psunlpgroup/MPlanner.
Training Step-Level Reasoning Verifiers with Formal Verification Tools
May 21, 2025



Process Reward Models (PRMs), which provide step-by-step feedback on the reasoning generated by Large Language Models (LLMs), are receiving increasing attention. However, two key research gaps remain: collecting accurate step-level error labels for training typically requires costly human annotation, and existing PRMs are limited to math reasoning problems. In response to these gaps, this paper aims to address the challenges of automatic dataset creation and the generalization of PRMs to diverse reasoning tasks. To achieve this goal, we propose FoVer, an approach for training PRMs on step-level error labels automatically annotated by formal verification tools, such as Z3 for formal logic and Isabelle for theorem proof, which provide automatic and accurate verification for symbolic tasks. Using this approach, we synthesize a training dataset with error labels on LLM responses for formal logic and theorem proof tasks without human annotation. Although this data synthesis is feasible only for tasks compatible with formal verification, we observe that LLM-based PRMs trained on our dataset exhibit cross-task generalization, improving verification across diverse reasoning tasks. Specifically, PRMs trained with FoVer significantly outperform baseline PRMs based on the original LLMs and achieve competitive or superior results compared to state-of-the-art PRMs trained on labels annotated by humans or stronger models, as measured by step-level verification on ProcessBench and Best-of-K performance across 12 reasoning benchmarks, including MATH, AIME, ANLI, MMLU, and BBH. The datasets, models, and code are provided at https://github.com/psunlpgroup/FoVer.
NeuroGen: Neural Network Parameter Generation via Large Language Models
May 18, 2025Acquiring the parameters of neural networks (NNs) has been one of the most important problems in machine learning since the inception of NNs. Traditional approaches, such as backpropagation and forward-only optimization, acquire parameters via iterative data fitting to gradually optimize them. This paper aims to explore the feasibility of a new direction: acquiring NN parameters via large language model generation. We propose NeuroGen, a generalized and easy-to-implement two-stage approach for NN parameter generation conditioned on descriptions of the data, task, and network architecture. Stage one is Parameter Reference Knowledge Injection, where LLMs are pretrained on NN checkpoints to build foundational understanding of parameter space, whereas stage two is Context-Enhanced Instruction Tuning, enabling LLMs to adapt to specific tasks through enriched, task-aware prompts. Experimental results demonstrate that NeuroGen effectively generates usable NN parameters. Our findings highlight the feasibility of LLM-based NN parameter generation and suggest a promising new paradigm where LLMs and lightweight NNs can coexist synergistically
HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding?
Apr 29, 2025



High-resolution image (HRI) understanding aims to process images with a large number of pixels, such as pathological images and agricultural aerial images, both of which can exceed 1 million pixels. Vision Large Language Models (VLMs) can allegedly handle HRIs, however, there is a lack of a comprehensive benchmark for VLMs to evaluate HRI understanding. To address this gap, we introduce HRScene, a novel unified benchmark for HRI understanding with rich scenes. HRScene incorporates 25 real-world datasets and 2 synthetic diagnostic datasets with resolutions ranging from 1,024 $\times$ 1,024 to 35,503 $\times$ 26,627. HRScene is collected and re-annotated by 10 graduate-level annotators, covering 25 scenarios, ranging from microscopic to radiology images, street views, long-range pictures, and telescope images. It includes HRIs of real-world objects, scanned documents, and composite multi-image. The two diagnostic evaluation datasets are synthesized by combining the target image with the gold answer and distracting images in different orders, assessing how well models utilize regions in HRI. We conduct extensive experiments involving 28 VLMs, including Gemini 2.0 Flash and GPT-4o. Experiments on HRScene show that current VLMs achieve an average accuracy of around 50% on real-world tasks, revealing significant gaps in HRI understanding. Results on synthetic datasets reveal that VLMs struggle to effectively utilize HRI regions, showing significant Regional Divergence and lost-in-middle, shedding light on future research.