 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Recurrent Transformer: Architecture Exploration, Training Strategies, and Scaling Behavior
May 26, 2026We study Latent Recurrent Transformer (LRT), a lightweight augmentation of autoregressive transformers that reuses a high-level source-layer hidden state from the previous token as recurrent memory for the next token. Because this source state is already computed during ordinary decoding, LRT adds a cross-layer recurrent latent pathway across positions without inserting pause tokens or extra depth loops, and the standard attention mechanism and KV-cache interface are preserved. To pretrain this recurrence at scale without sequentially unrolling the transformer, we introduce interleaved parallel training: a single full-sequence initialization forward pass builds a shared buffer; then disjoint position subsets are refined in parallel and written back, so that all tokens receive recurrent-memory-aware supervision at roughly 2 times baseline compute. Across nanochat style backbones and a wide range of tokens-per-parameter budgets, LRT improves both language-modeling loss and in-context learning under matched effective compute while adding as little as 0.3% parameters.
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
Jul 09, 2025



Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
May 21, 2025Human cognition typically involves thinking through abstract, fluid concepts rather than strictly using discrete linguistic tokens. Current reasoning models, however, are constrained to reasoning within the boundaries of human language, processing discrete token embeddings that represent fixed points in the semantic space. This discrete constraint restricts the expressive power and upper potential of such reasoning models, often causing incomplete exploration of reasoning paths, as standard Chain-of-Thought (CoT) methods rely on sampling one token per step. In this work, we introduce Soft Thinking, a training-free method that emulates human-like "soft" reasoning by generating soft, abstract concept tokens in a continuous concept space. These concept tokens are created by the probability-weighted mixture of token embeddings, which form the continuous concept space, enabling smooth transitions and richer representations that transcend traditional discrete boundaries. In essence, each generated concept token encapsulates multiple meanings from related discrete tokens, implicitly exploring various reasoning paths to converge effectively toward the correct answer. Empirical evaluations on diverse mathematical and coding benchmarks consistently demonstrate the effectiveness and efficiency of Soft Thinking, improving pass@1 accuracy by up to 2.48 points while simultaneously reducing token usage by up to 22.4% compared to standard CoT. Qualitative analysis further reveals that Soft Thinking outputs remain highly interpretable and readable, highlighting the potential of Soft Thinking to break the inherent bottleneck of discrete language-based reasoning. Code is available at https://github.com/eric-ai-lab/Soft-Thinking.
Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math
Apr 30, 2025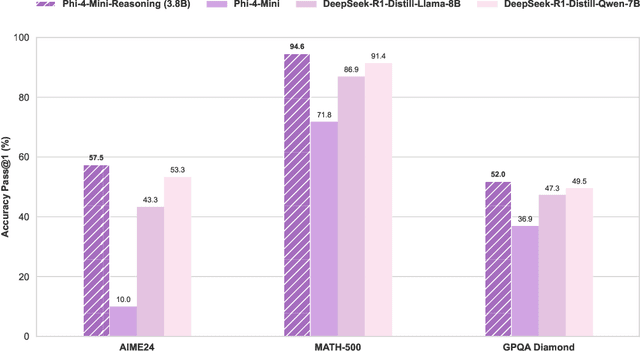
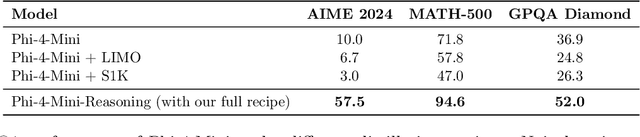
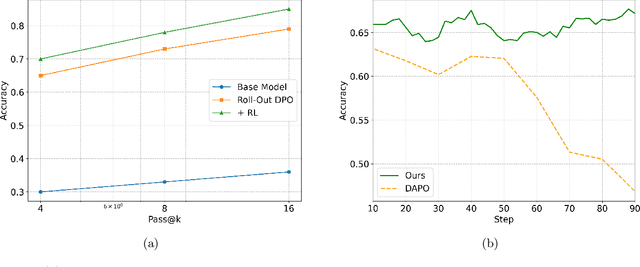
Chain-of-Thought (CoT) significantly enhances formal reasoning capabilities in Large Language Models (LLMs) by training them to explicitly generate intermediate reasoning steps. While LLMs readily benefit from such techniques, improving reasoning in Small Language Models (SLMs) remains challenging due to their limited model capacity. Recent work by Deepseek-R1 demonstrates that distillation from LLM-generated synthetic data can substantially improve the reasoning ability of SLM. However, the detailed modeling recipe is not disclosed. In this work, we present a systematic training recipe for SLMs that consists of four steps: (1) large-scale mid-training on diverse distilled long-CoT data, (2) supervised fine-tuning on high-quality long-CoT data, (3) Rollout DPO leveraging a carefully curated preference dataset, and (4) Reinforcement Learning (RL) with Verifiable Reward. We apply our method on Phi-4-Mini, a compact 3.8B-parameter model. The resulting Phi-4-Mini-Reasoning model exceeds, on math reasoning tasks, much larger reasoning models, e.g., outperforming DeepSeek-R1-Distill-Qwen-7B by 3.2 points and DeepSeek-R1-Distill-Llama-8B by 7.7 points on Math-500. Our results validate that a carefully designed training recipe, with large-scale high-quality CoT data, is effective to unlock strong reasoning capabilities even in resource-constrained small models.
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Apr 29, 2025



We show that reinforcement learning with verifiable reward using one training example (1-shot RLVR) is effective in incentivizing the math reasoning capabilities of large language models (LLMs). Applying RLVR to the base model Qwen2.5-Math-1.5B, we identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%, and improves the average performance across six common mathematical reasoning benchmarks from 17.6% to 35.7%. This result matches the performance obtained using the 1.2k DeepScaleR subset (MATH500: 73.6%, average: 35.9%), which includes the aforementioned example. Similar substantial improvements are observed across various models (Qwen2.5-Math-7B, Llama3.2-3B-Instruct, DeepSeek-R1-Distill-Qwen-1.5B), RL algorithms (GRPO and PPO), and different math examples (many of which yield approximately 30% or greater improvement on MATH500 when employed as a single training example). In addition, we identify some interesting phenomena during 1-shot RLVR, including cross-domain generalization, increased frequency of self-reflection, and sustained test performance improvement even after the training accuracy has saturated, a phenomenon we term post-saturation generalization. Moreover, we verify that the effectiveness of 1-shot RLVR primarily arises from the policy gradient loss, distinguishing it from the "grokking" phenomenon. We also show the critical role of promoting exploration (e.g., by adding entropy loss with an appropriate coefficient) in 1-shot RLVR training. As a bonus, we observe that applying entropy loss alone, without any outcome reward, significantly enhances Qwen2.5-Math-1.5B's performance on MATH500 by 27.4%. These findings can inspire future work on RLVR data efficiency and encourage a re-examination of both recent progress and the underlying mechanisms in RLVR. Our code, model, and data are open source at https://github.com/ypwang61/One-Shot-RLVR
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Is Your World Simulator a Good Story Presenter? A Consecutive Events-Based Benchmark for Future Long Video Generation
Dec 17, 2024



The current state-of-the-art video generative models can produce commercial-grade videos with highly realistic details. However, they still struggle to coherently present multiple sequential events in the stories specified by the prompts, which is foreseeable an essential capability for future long video generation scenarios. For example, top T2V generative models still fail to generate a video of the short simple story 'how to put an elephant into a refrigerator.' While existing detail-oriented benchmarks primarily focus on fine-grained metrics like aesthetic quality and spatial-temporal consistency, they fall short of evaluating models' abilities to handle event-level story presentation. To address this gap, we introduce StoryEval, a story-oriented benchmark specifically designed to assess text-to-video (T2V) models' story-completion capabilities. StoryEval features 423 prompts spanning 7 classes, each representing short stories composed of 2-4 consecutive events. We employ advanced vision-language models, such as GPT-4V and LLaVA-OV-Chat-72B, to verify the completion of each event in the generated videos, applying a unanimous voting method to enhance reliability. Our methods ensure high alignment with human evaluations, and the evaluation of 11 models reveals its challenge, with none exceeding an average story-completion rate of 50%. StoryEval provides a new benchmark for advancing T2V models and highlights the challenges and opportunities in developing next-generation solutions for coherent story-driven video generation.
Mojito: Motion Trajectory and Intensity Control for Video Generation
Dec 12, 2024



Recent advancements in diffusion models have shown great promise in producing high-quality video content. However, efficiently training diffusion models capable of integrating directional guidance and controllable motion intensity remains a challenging and under-explored area. This paper introduces Mojito, a diffusion model that incorporates both \textbf{Mo}tion tra\textbf{j}ectory and \textbf{i}ntensi\textbf{t}y contr\textbf{o}l for text to video generation. Specifically, Mojito features a Directional Motion Control module that leverages cross-attention to efficiently direct the generated object's motion without additional training, alongside a Motion Intensity Modulator that uses optical flow maps generated from videos to guide varying levels of motion intensity. Extensive experiments demonstrate Mojito's effectiveness in achieving precise trajectory and intensity control with high computational efficiency, generating motion patterns that closely match specified directions and intensities, providing realistic dynamics that align well with natural motion in real-world scenarios.
Temperature-Centric Investigation of Speculative Decoding with Knowledge Distillation
Oct 14, 2024Speculative decoding stands as a pivotal technique to expedite inference in autoregressive (large) language models. This method employs a smaller draft model to speculate a block of tokens, which the target model then evaluates for acceptance. Despite a wealth of studies aimed at increasing the efficiency of speculative decoding, the influence of generation configurations on the decoding process remains poorly understood, especially concerning decoding temperatures. This paper delves into the effects of decoding temperatures on speculative decoding's efficacy. Beginning with knowledge distillation (KD), we first highlight the challenge of decoding at higher temperatures, and demonstrate KD in a consistent temperature setting could be a remedy. We also investigate the effects of out-of-domain testing sets with out-of-range temperatures. Building upon these findings, we take an initial step to further the speedup for speculative decoding, particularly in a high-temperature generation setting. Our work offers new insights into how generation configurations drastically affect the performance of speculative decoding, and underscores the need for developing methods that focus on diverse decoding configurations. Code is publically available at https://github.com/ozyyshr/TempSpec.
LoRC: Low-Rank Compression for LLMs KV Cache with a Progressive Compression Strategy
Oct 04, 2024



The Key-Value (KV) cache is a crucial component in serving transformer-based autoregressive large language models (LLMs), enabling faster inference by storing previously computed KV vectors. However, its memory consumption scales linearly with sequence length and batch size, posing a significant bottleneck in LLM deployment. Existing approaches to mitigate this issue include: (1) efficient attention variants integrated in upcycling stages, which requires extensive parameter tuning thus unsuitable for pre-trained LLMs; (2) KV cache compression at test time, primarily through token eviction policies, which often overlook inter-layer dependencies and can be task-specific. This paper introduces an orthogonal approach to KV cache compression. We propose a low-rank approximation of KV weight matrices, allowing for plug-in integration with existing transformer-based LLMs without model retraining. To effectively compress KV cache at the weight level, we adjust for layerwise sensitivity and introduce a progressive compression strategy, which is supported by our theoretical analysis on how compression errors accumulate in deep networks. Our method is designed to function without model tuning in upcycling stages or task-specific profiling in test stages. Extensive experiments with LLaMA models ranging from 8B to 70B parameters across various tasks show that our approach significantly reduces the GPU memory footprint while maintaining performance.