 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Outlier Tokens in Diffusion Transformers
May 06, 2026We study outlier tokens in Diffusion Transformers (DiTs) for image generation. Prior work has shown that Vision Transformers (ViTs) can produce a small number of high-norm tokens that attract disproportionate attention while carrying limited local information, but their role in generative models remains underexplored. We show that this phenomenon appears in both the encoder and denoiser of modern Representation Autoencoder (RAE)-DiT pipelines: pretrained ViT encoders can produce outlier representations, and DiTs themselves can develop internal outlier tokens, especially in intermediate layers. Moreover, simply masking high-norm tokens does not improve performance, indicating that the problem is not only caused by a few extreme values, but is more closely related to corrupted local patch semantics. To address this issue, we introduce Dual-Stage Registers (DSR), a register-based intervention for both components: trained registers when available, recursive test-time registers otherwise, and diffusion registers for the denoiser. Across ImageNet and large-scale text-to-image generation, these interventions consistently reduce outlier artifacts and improve generation quality. Our results highlight outlier-token control as an important ingredient in building stronger DiTs.
Proactive Agent Research Environment: Simulating Active Users to Evaluate Proactive Assistants
Apr 01, 2026Proactive agents that anticipate user needs and autonomously execute tasks hold great promise as digital assistants, yet the lack of realistic user simulation frameworks hinders their development. Existing approaches model apps as flat tool-calling APIs, failing to capture the stateful and sequential nature of user interaction in digital environments and making realistic user simulation infeasible. We introduce Proactive Agent Research Environment (Pare), a framework for building and evaluating proactive agents in digital environments. Pare models applications as finite state machines with stateful navigation and state-dependent action space for the user simulator, enabling active user simulation. Building on this foundation, we present Pare-Bench, a benchmark of 143 diverse tasks spanning communication, productivity, scheduling, and lifestyle apps, designed to test context observation, goal inference, intervention timing, and multi-app orchestration.
Learning Structured Reasoning via Tractable Trajectory Control
Mar 02, 2026Large language models can exhibit emergent reasoning behaviors, often manifested as recurring lexical patterns (e.g., "wait," indicating verification). However, complex reasoning trajectories remain sparse in unconstrained sampling, and standard RL often fails to guarantee the acquisition of diverse reasoning behaviors. We propose a systematic discovery and reinforcement of diverse reasoning patterns through structured reasoning, a paradigm that requires targeted exploration of specific reasoning patterns during the RL process. To this end, we propose Ctrl-R, a framework for learning structured reasoning via tractable trajectory control that actively guides the rollout process, incentivizing the exploration of diverse reasoning patterns that are critical for complex problem-solving. The resulting behavior policy enables accurate importance-sampling estimation, supporting unbiased on-policy optimization. We further introduce a power-scaling factor on the importance-sampling weights, allowing the policy to selectively learn from exploratory, out-of-distribution trajectories while maintaining stable optimization. Experiments demonstrate that Ctrl-R enables effective exploration and internalization of previously unattainable reasoning patterns, yielding consistent improvements across language and vision-language models on mathematical reasoning tasks.
UniGen-1.5: Enhancing Image Generation and Editing through Reward Unification in Reinforcement Learning
Nov 18, 2025We present UniGen-1.5, a unified multimodal large language model (MLLM) for advanced image understanding, generation and editing. Building upon UniGen, we comprehensively enhance the model architecture and training pipeline to strengthen the image understanding and generation capabilities while unlocking strong image editing ability. Especially, we propose a unified Reinforcement Learning (RL) strategy that improves both image generation and image editing jointly via shared reward models. To further enhance image editing performance, we propose a light Edit Instruction Alignment stage that significantly improves the editing instruction comprehension that is essential for the success of the RL training. Experimental results show that UniGen-1.5 demonstrates competitive understanding and generation performance. Specifically, UniGen-1.5 achieves 0.89 and 4.31 overall scores on GenEval and ImgEdit that surpass the state-of-the-art models such as BAGEL and reaching performance comparable to proprietary models such as GPT-Image-1.
Pico-Banana-400K: A Large-Scale Dataset for Text-Guided Image Editing
Oct 22, 2025Recent advances in multimodal models have demonstrated remarkable text-guided image editing capabilities, with systems like GPT-4o and Nano-Banana setting new benchmarks. However, the research community's progress remains constrained by the absence of large-scale, high-quality, and openly accessible datasets built from real images. We introduce Pico-Banana-400K, a comprehensive 400K-image dataset for instruction-based image editing. Our dataset is constructed by leveraging Nano-Banana to generate diverse edit pairs from real photographs in the OpenImages collection. What distinguishes Pico-Banana-400K from previous synthetic datasets is our systematic approach to quality and diversity. We employ a fine-grained image editing taxonomy to ensure comprehensive coverage of edit types while maintaining precise content preservation and instruction faithfulness through MLLM-based quality scoring and careful curation. Beyond single turn editing, Pico-Banana-400K enables research into complex editing scenarios. The dataset includes three specialized subsets: (1) a 72K-example multi-turn collection for studying sequential editing, reasoning, and planning across consecutive modifications; (2) a 56K-example preference subset for alignment research and reward model training; and (3) paired long-short editing instructions for developing instruction rewriting and summarization capabilities. By providing this large-scale, high-quality, and task-rich resource, Pico-Banana-400K establishes a robust foundation for training and benchmarking the next generation of text-guided image editing models.
DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search
Oct 14, 2025Multimodal Large Language Models (MLLMs) in real-world applications require access to external knowledge sources and must remain responsive to the dynamic and ever-changing real-world information in order to address information-seeking and knowledge-intensive user queries. Existing approaches, such as retrieval augmented generation (RAG) methods, search agents, and search equipped MLLMs, often suffer from rigid pipelines, excessive search calls, and poorly constructed search queries, which result in inefficiencies and suboptimal outcomes. To address these limitations, we present DeepMMSearch-R1, the first multimodal LLM capable of performing on-demand, multi-turn web searches and dynamically crafting queries for both image and text search tools. Specifically, DeepMMSearch-R1 can initiate web searches based on relevant crops of the input image making the image search more effective, and can iteratively adapt text search queries based on retrieved information, thereby enabling self-reflection and self-correction. Our approach relies on a two-stage training pipeline: a cold start supervised finetuning phase followed by an online reinforcement learning optimization. For training, we introduce DeepMMSearchVQA, a novel multimodal VQA dataset created through an automated pipeline intermixed with real-world information from web search tools. This dataset contains diverse, multi-hop queries that integrate textual and visual information, teaching the model when to search, what to search for, which search tool to use and how to reason over the retrieved information. We conduct extensive experiments across a range of knowledge-intensive benchmarks to demonstrate the superiority of our approach. Finally, we analyze the results and provide insights that are valuable for advancing multimodal web-search.
Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025



Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
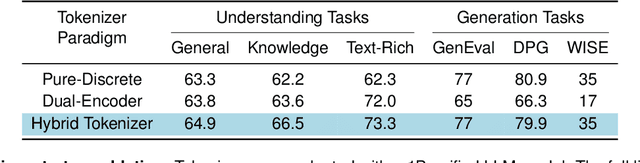
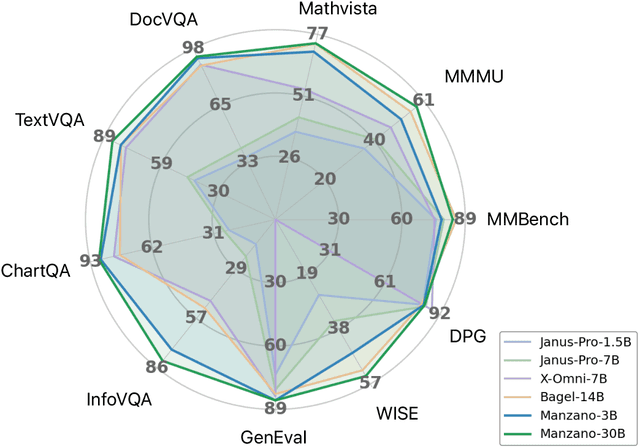
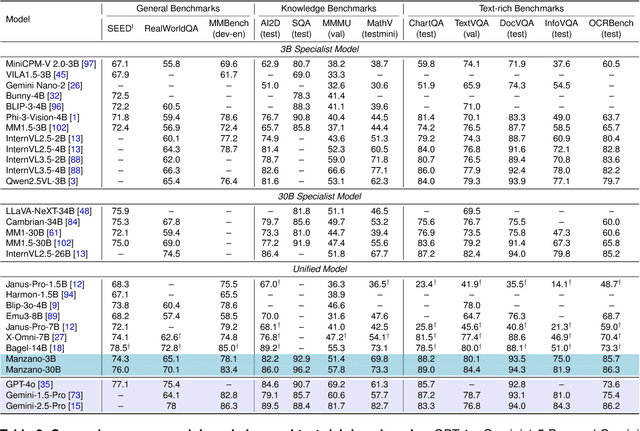
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
GIE-Bench: Towards Grounded Evaluation for Text-Guided Image Editing
May 16, 2025



Editing images using natural language instructions has become a natural and expressive way to modify visual content; yet, evaluating the performance of such models remains challenging. Existing evaluation approaches often rely on image-text similarity metrics like CLIP, which lack precision. In this work, we introduce a new benchmark designed to evaluate text-guided image editing models in a more grounded manner, along two critical dimensions: (i) functional correctness, assessed via automatically generated multiple-choice questions that verify whether the intended change was successfully applied; and (ii) image content preservation, which ensures that non-targeted regions of the image remain visually consistent using an object-aware masking technique and preservation scoring. The benchmark includes over 1000 high-quality editing examples across 20 diverse content categories, each annotated with detailed editing instructions, evaluation questions, and spatial object masks. We conduct a large-scale study comparing GPT-Image-1, the latest flagship in the text-guided image editing space, against several state-of-the-art editing models, and validate our automatic metrics against human ratings. Results show that GPT-Image-1 leads in instruction-following accuracy, but often over-modifies irrelevant image regions, highlighting a key trade-off in the current model behavior. GIE-Bench provides a scalable, reproducible framework for advancing more accurate evaluation of text-guided image editing.
SlowFast-LLaVA-1.5: A Family of Token-Efficient Video Large Language Models for Long-Form Video Understanding
Mar 27, 2025We introduce SlowFast-LLaVA-1.5 (abbreviated as SF-LLaVA-1.5), a family of video large language models (LLMs) offering a token-efficient solution for long-form video understanding. We incorporate the two-stream SlowFast mechanism into a streamlined training pipeline, and perform joint video-image training on a carefully curated data mixture of only publicly available datasets. Our primary focus is on highly efficient model scales (1B and 3B), demonstrating that even relatively small Video LLMs can achieve state-of-the-art performance on video understanding, meeting the demand for mobile-friendly models. Experimental results demonstrate that SF-LLaVA-1.5 achieves superior performance on a wide range of video and image tasks, with robust results at all model sizes (ranging from 1B to 7B). Notably, SF-LLaVA-1.5 achieves state-of-the-art results in long-form video understanding (e.g., LongVideoBench and MLVU) and excels at small scales across various video benchmarks.