 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Why Behind the Action: Unveiling Internal Drivers via Agentic Attribution
Jan 21, 2026Large Language Model (LLM)-based agents are widely used in real-world applications such as customer service, web navigation, and software engineering. As these systems become more autonomous and are deployed at scale, understanding why an agent takes a particular action becomes increasingly important for accountability and governance. However, existing research predominantly focuses on \textit{failure attribution} to localize explicit errors in unsuccessful trajectories, which is insufficient for explaining the reasoning behind agent behaviors. To bridge this gap, we propose a novel framework for \textbf{general agentic attribution}, designed to identify the internal factors driving agent actions regardless of the task outcome. Our framework operates hierarchically to manage the complexity of agent interactions. Specifically, at the \textit{component level}, we employ temporal likelihood dynamics to identify critical interaction steps; then at the \textit{sentence level}, we refine this localization using perturbation-based analysis to isolate the specific textual evidence. We validate our framework across a diverse suite of agentic scenarios, including standard tool use and subtle reliability risks like memory-induced bias. Experimental results demonstrate that the proposed framework reliably pinpoints pivotal historical events and sentences behind the agent behavior, offering a critical step toward safer and more accountable agentic systems.
LogicEnvGen: Task-Logic Driven Generation of Diverse Simulated Environments for Embodied AI
Jan 20, 2026Simulated environments play an essential role in embodied AI, functionally analogous to test cases in software engineering. However, existing environment generation methods often emphasize visual realism (e.g., object diversity and layout coherence), overlooking a crucial aspect: logical diversity from the testing perspective. This limits the comprehensive evaluation of agent adaptability and planning robustness in distinct simulated environments. To bridge this gap, we propose LogicEnvGen, a novel method driven by Large Language Models (LLMs) that adopts a top-down paradigm to generate logically diverse simulated environments as test cases for agents. Given an agent task, LogicEnvGen first analyzes its execution logic to construct decision-tree-structured behavior plans and then synthesizes a set of logical trajectories. Subsequently, it adopts a heuristic algorithm to refine the trajectory set, reducing redundant simulation. For each logical trajectory, which represents a potential task situation, LogicEnvGen correspondingly instantiates a concrete environment. Notably, it employs constraint solving for physical plausibility. Furthermore, we introduce LogicEnvEval, a novel benchmark comprising four quantitative metrics for environment evaluation. Experimental results verify the lack of logical diversity in baselines and demonstrate that LogicEnvGen achieves 1.04-2.61x greater diversity, significantly improving the performance in revealing agent faults by 4.00%-68.00%.
Teaching LLMs to Learn Tool Trialing and Execution through Environment Interaction
Jan 19, 2026Equipping Large Language Models (LLMs) with external tools enables them to solve complex real-world problems. However, the robustness of existing methods remains a critical challenge when confronting novel or evolving tools. Existing trajectory-centric paradigms primarily rely on memorizing static solution paths during training, which limits the ability of LLMs to generalize tool usage to newly introduced or previously unseen tools. In this paper, we propose ToolMaster, a framework that shifts tool use from imitating golden tool-calling trajectories to actively learning tool usage through interaction with the environment. To optimize LLMs for tool planning and invocation, ToolMaster adopts a trial-and-execution paradigm, which trains LLMs to first imitate teacher-generated trajectories containing explicit tool trials and self-correction, followed by reinforcement learning to coordinate the trial and execution phases jointly. This process enables agents to autonomously explore correct tool usage by actively interacting with environments and forming experiential knowledge that benefits tool execution. Experimental results demonstrate that ToolMaster significantly outperforms existing baselines in terms of generalization and robustness across unseen or unfamiliar tools. All code and data are available at https://github.com/NEUIR/ToolMaster.
From "Thinking" to "Justifying": Aligning High-Stakes Explainability with Professional Communication Standards
Jan 12, 2026Explainable AI (XAI) in high-stakes domains should help stakeholders trust and verify system outputs. Yet Chain-of-Thought methods reason before concluding, and logical gaps or hallucinations can yield conclusions that do not reliably align with their rationale. Thus, we propose "Result -> Justify", which constrains the output communication to present a conclusion before its structured justification. We introduce SEF (Structured Explainability Framework), operationalizing professional conventions (e.g., CREAC, BLUF) via six metrics for structure and grounding. Experiments across four tasks in three domains validate this approach: all six metrics correlate with correctness (r=0.20-0.42; p<0.001), and SEF achieves 83.9% accuracy (+5.3 over CoT). These results suggest structured justification can improve verifiability and may also improve reliability.
Beyond the Black Box: Theory and Mechanism of Large Language Models
Jan 06, 2026The rapid emergence of Large Language Models (LLMs) has precipitated a profound paradigm shift in Artificial Intelligence, delivering monumental engineering successes that increasingly impact modern society. However, a critical paradox persists within the current field: despite the empirical efficacy, our theoretical understanding of LLMs remains disproportionately nascent, forcing these systems to be treated largely as ``black boxes''. To address this theoretical fragmentation, this survey proposes a unified lifecycle-based taxonomy that organizes the research landscape into six distinct stages: Data Preparation, Model Preparation, Training, Alignment, Inference, and Evaluation. Within this framework, we provide a systematic review of the foundational theories and internal mechanisms driving LLM performance. Specifically, we analyze core theoretical issues such as the mathematical justification for data mixtures, the representational limits of various architectures, and the optimization dynamics of alignment algorithms. Moving beyond current best practices, we identify critical frontier challenges, including the theoretical limits of synthetic data self-improvement, the mathematical bounds of safety guarantees, and the mechanistic origins of emergent intelligence. By connecting empirical observations with rigorous scientific inquiry, this work provides a structured roadmap for transitioning LLM development from engineering heuristics toward a principled scientific discipline.
Reinforcement Learning for Follow-the-Leader Robotic Endoscopic Navigation via Synthetic Data
Jan 06, 2026Autonomous navigation is crucial for both medical and industrial endoscopic robots, enabling safe and efficient exploration of narrow tubular environments without continuous human intervention, where avoiding contact with the inner walls has been a longstanding challenge for prior approaches. We present a follow-the-leader endoscopic robot based on a flexible continuum structure designed to minimize contact between the endoscope body and intestinal walls, thereby reducing patient discomfort. To achieve this objective, we propose a vision-based deep reinforcement learning framework guided by monocular depth estimation. A realistic intestinal simulation environment was constructed in \textit{NVIDIA Omniverse} to train and evaluate autonomous navigation strategies. Furthermore, thousands of synthetic intraluminal images were generated using NVIDIA Replicator to fine-tune the Depth Anything model, enabling dense three-dimensional perception of the intestinal environment with a single monocular camera. Subsequently, we introduce a geometry-aware reward and penalty mechanism to enable accurate lumen tracking. Compared with the original Depth Anything model, our method improves $δ_{1}$ depth accuracy by 39.2% and reduces the navigation J-index by 0.67 relative to the second-best method, demonstrating the robustness and effectiveness of the proposed approach.
Voronoi-Assisted Diffusion for Computing Unsigned Distance Fields from Unoriented Points
Oct 14, 2025Unsigned Distance Fields (UDFs) provide a flexible representation for 3D shapes with arbitrary topology, including open and closed surfaces, orientable and non-orientable geometries, and non-manifold structures. While recent neural approaches have shown promise in learning UDFs, they often suffer from numerical instability, high computational cost, and limited controllability. We present a lightweight, network-free method, Voronoi-Assisted Diffusion (VAD), for computing UDFs directly from unoriented point clouds. Our approach begins by assigning bi-directional normals to input points, guided by two Voronoi-based geometric criteria encoded in an energy function for optimal alignment. The aligned normals are then diffused to form an approximate UDF gradient field, which is subsequently integrated to recover the final UDF. Experiments demonstrate that VAD robustly handles watertight and open surfaces, as well as complex non-manifold and non-orientable geometries, while remaining computationally efficient and stable.
OpenMoCap: Rethinking Optical Motion Capture under Real-world Occlusion
Aug 18, 2025Optical motion capture is a foundational technology driving advancements in cutting-edge fields such as virtual reality and film production. However, system performance suffers severely under large-scale marker occlusions common in real-world applications. An in-depth analysis identifies two primary limitations of current models: (i) the lack of training datasets accurately reflecting realistic marker occlusion patterns, and (ii) the absence of training strategies designed to capture long-range dependencies among markers. To tackle these challenges, we introduce the CMU-Occlu dataset, which incorporates ray tracing techniques to realistically simulate practical marker occlusion patterns. Furthermore, we propose OpenMoCap, a novel motion-solving model designed specifically for robust motion capture in environments with significant occlusions. Leveraging a marker-joint chain inference mechanism, OpenMoCap enables simultaneous optimization and construction of deep constraints between markers and joints. Extensive comparative experiments demonstrate that OpenMoCap consistently outperforms competing methods across diverse scenarios, while the CMU-Occlu dataset opens the door for future studies in robust motion solving. The proposed OpenMoCap is integrated into the MoSen MoCap system for practical deployment. The code is released at: https://github.com/qianchen214/OpenMoCap.
SpotVLM: Cloud-edge Collaborative Real-time VLM based on Context Transfer
Aug 18, 2025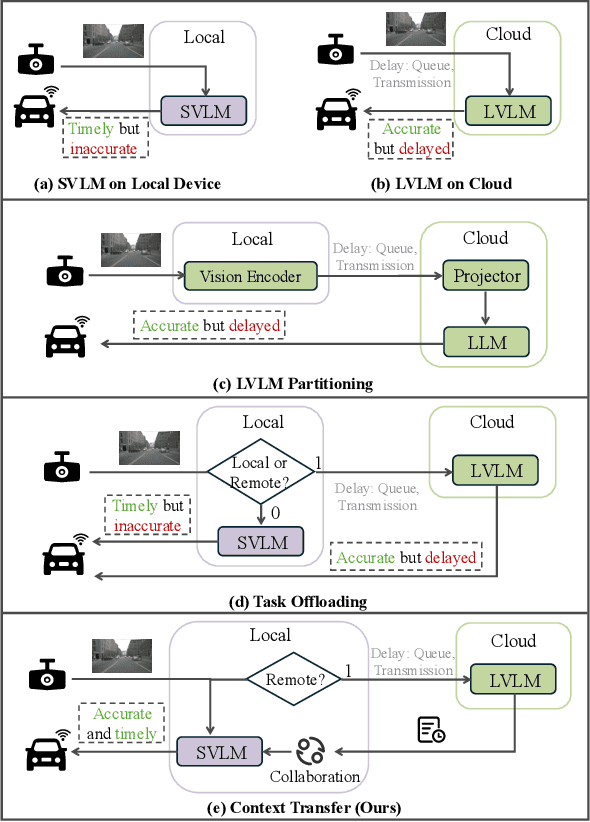
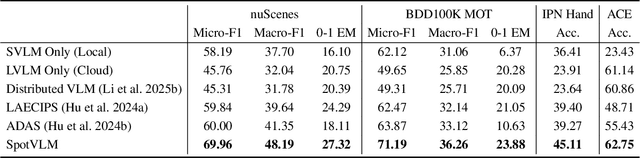
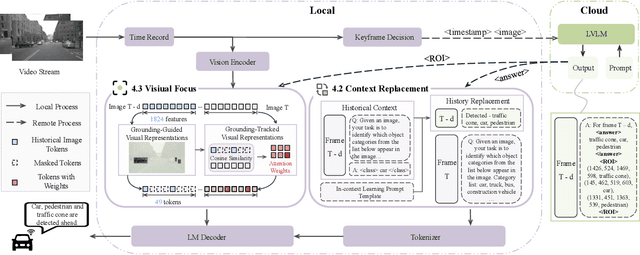
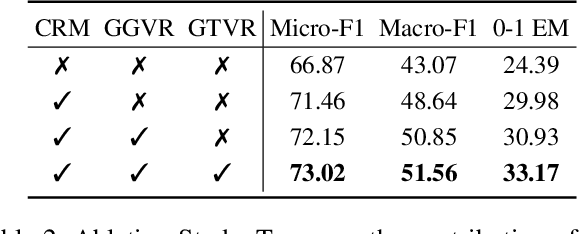
Vision-Language Models (VLMs) are increasingly deployed in real-time applications such as autonomous driving and human-computer interaction, which demand fast and reliable responses based on accurate perception. To meet these requirements, existing systems commonly employ cloud-edge collaborative architectures, such as partitioned Large Vision-Language Models (LVLMs) or task offloading strategies between Large and Small Vision-Language Models (SVLMs). However, these methods fail to accommodate cloud latency fluctuations and overlook the full potential of delayed but accurate LVLM responses. In this work, we propose a novel cloud-edge collaborative paradigm for VLMs, termed Context Transfer, which treats the delayed outputs of LVLMs as historical context to provide real-time guidance for SVLMs inference. Based on this paradigm, we design SpotVLM, which incorporates both context replacement and visual focus modules to refine historical textual input and enhance visual grounding consistency. Extensive experiments on three real-time vision tasks across four datasets demonstrate the effectiveness of the proposed framework. The new paradigm lays the groundwork for more effective and latency-aware collaboration strategies in future VLM systems.
Multi-module GRPO: Composing Policy Gradients and Prompt Optimization for Language Model Programs
Aug 06, 2025Group Relative Policy Optimization (GRPO) has proven to be an effective tool for post-training language models (LMs). However, AI systems are increasingly expressed as modular programs that mix together multiple LM calls with distinct prompt templates and other tools, and it is not clear how best to leverage GRPO to improve these systems. We begin to address this challenge by defining mmGRPO, a simple multi-module generalization of GRPO that groups LM calls by module across rollouts and handles variable-length and interrupted trajectories. We find that mmGRPO, composed with automatic prompt optimization, improves accuracy by 11% on average across classification, many-hop search, and privacy-preserving delegation tasks against the post-trained LM, and by 5% against prompt optimization on its own. We open-source mmGRPO in DSPy as the dspy.GRPO optimizer.