 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWestWorld: A Knowledge-Encoded Scalable Trajectory World Model for Diverse Robotic Systems
Mar 15, 2026Trajectory world models play a crucial role in robotic dynamics learning, planning, and control. While recent works have explored trajectory world models for diverse robotic systems, they struggle to scale to a large number of distinct system dynamics and overlook domain knowledge of physical structures. To address these limitations, we introduce WestWorld, a knoWledge-Encoded Scalable Trajectory World model for diverse robotic systems. To tackle the scalability challenge, we propose a novel system-aware Mixture-of-Experts (Sys-MoE) that dynamically combines and routes specialized experts for different robotic systems via a learnable system embedding. To further enhance zero-shot generalization, we incorporate domain knowledge of robot physical structures by introducing a structural embedding that aligns trajectory representations with morphological information. After pretraining on 89 complex environments spanning diverse morphologies across both simulation and real-world settings, WestWorld achieves significant improvements over competitive baselines in zero- and few-shot trajectory prediction. Additionally, it shows strong scalability across a wide range of robotic environments and significantly improves performance on downstream model-based control for different robots. Finally, we deploy our model on a real-world Unitree Go1, where it demonstrates stable locomotion performance (see our demo on the website: https://westworldrobot.github.io/). The code will be available upon publication.
ODESteer: A Unified ODE-Based Steering Framework for LLM Alignment
Feb 19, 2026Activation steering, or representation engineering, offers a lightweight approach to align large language models (LLMs) by manipulating their internal activations at inference time. However, current methods suffer from two key limitations: \textit{(i)} the lack of a unified theoretical framework for guiding the design of steering directions, and \textit{(ii)} an over-reliance on \textit{one-step steering} that fail to capture complex patterns of activation distributions. In this work, we propose a unified ordinary differential equations (ODEs)-based \textit{theoretical} framework for activation steering in LLM alignment. We show that conventional activation addition can be interpreted as a first-order approximation to the solution of an ODE. Based on this ODE perspective, identifying a steering direction becomes equivalent to designing a \textit{barrier function} from control theory. Derived from this framework, we introduce ODESteer, a kind of ODE-based steering guided by barrier functions, which shows \textit{empirical} advancement in LLM alignment. ODESteer identifies steering directions by defining the barrier function as the log-density ratio between positive and negative activations, and employs it to construct an ODE for \textit{multi-step and adaptive} steering. Compared to state-of-the-art activation steering methods, ODESteer achieves consistent empirical improvements on diverse LLM alignment benchmarks, a notable $5.7\%$ improvement over TruthfulQA, $2.5\%$ over UltraFeedback, and $2.4\%$ over RealToxicityPrompts. Our work establishes a principled new view of activation steering in LLM alignment by unifying its theoretical foundations via ODEs, and validating it empirically through the proposed ODESteer method.
Towards Comprehensive Benchmarking Infrastructure for LLMs In Software Engineering
Jan 28, 2026Large language models for code are advancing fast, yet our ability to evaluate them lags behind. Current benchmarks focus on narrow tasks and single metrics, which hide critical gaps in robustness, interpretability, fairness, efficiency, and real-world usability. They also suffer from inconsistent data engineering practices, limited software engineering context, and widespread contamination issues. To understand these problems and chart a path forward, we combined an in-depth survey of existing benchmarks with insights gathered from a dedicated community workshop. We identified three core barriers to reliable evaluation: the absence of software-engineering-rich datasets, overreliance on ML-centric metrics, and the lack of standardized, reproducible data pipelines. Building on these findings, we introduce BEHELM, a holistic benchmarking infrastructure that unifies software-scenario specification with multi-metric evaluation. BEHELM provides a structured way to assess models across tasks, languages, input and output granularities, and key quality dimensions. Our goal is to reduce the overhead currently required to construct benchmarks while enabling a fair, realistic, and future-proof assessment of LLMs in software engineering.
* Short paper from bechmarking for software engineering workshop FSE2025
P3SL: Personalized Privacy-Preserving Split Learning on Heterogeneous Edge Devices
Jul 23, 2025



Split Learning (SL) is an emerging privacy-preserving machine learning technique that enables resource constrained edge devices to participate in model training by partitioning a model into client-side and server-side sub-models. While SL reduces computational overhead on edge devices, it encounters significant challenges in heterogeneous environments where devices vary in computing resources, communication capabilities, environmental conditions, and privacy requirements. Although recent studies have explored heterogeneous SL frameworks that optimize split points for devices with varying resource constraints, they often neglect personalized privacy requirements and local model customization under varying environmental conditions. To address these limitations, we propose P3SL, a Personalized Privacy-Preserving Split Learning framework designed for heterogeneous, resource-constrained edge device systems. The key contributions of this work are twofold. First, we design a personalized sequential split learning pipeline that allows each client to achieve customized privacy protection and maintain personalized local models tailored to their computational resources, environmental conditions, and privacy needs. Second, we adopt a bi-level optimization technique that empowers clients to determine their own optimal personalized split points without sharing private sensitive information (i.e., computational resources, environmental conditions, privacy requirements) with the server. This approach balances energy consumption and privacy leakage risks while maintaining high model accuracy. We implement and evaluate P3SL on a testbed consisting of 7 devices including 4 Jetson Nano P3450 devices, 2 Raspberry Pis, and 1 laptop, using diverse model architectures and datasets under varying environmental conditions.
Probability Estimation and Scheduling Optimization for Battery Swap Stations via LRU-Enhanced Genetic Algorithm and Dual-Factor Decision System
Apr 10, 2025To address the challenges of limited Battery Swap Stations datasets, high operational costs, and fluctuating user charging demand, this research proposes a probability estimation model based on charging pile data and constructs nine scenario-specific battery swap demand datasets. In addition, this study combines Least Recently Used strategy with Genetic Algorithm and incorporates a guided search mechanism, which effectively enhances the global optimization capability. Thus, a dual-factor decision-making based charging schedule optimization system is constructed. Experimental results show that the constructed datasets exhibit stable trend characteristics, adhering to 24-hour and 168-hour periodicity patterns, with outlier ratios consistently below 3.26%, confirming data validity. Compared to baseline, the improved algorithm achieves better fitness individuals in 80% of test regions under the same iterations. When benchmarked against immediate swap-and-charge strategy, our algorithm achieves a peak cost reduction of 13.96%. Moreover, peak user satisfaction reaches 98.57%, while the average iteration time remains below 0.6 seconds, demonstrating good computational efficiency. The complete datasets and optimization algorithm are open-sourced at https://github.com/qingshufan/GA-EVLRU.
Lens: A Foundation Model for Network Traffic in Cybersecurity
Feb 09, 2024Network traffic refers to the amount of data being sent and received over the internet or any system that connects computers. Analyzing and understanding network traffic is vital for improving network security and management. However, the analysis of network traffic is challenging due to the diverse nature of data packets, which often feature heterogeneous headers and encrypted payloads lacking semantics. To capture the latent semantics of traffic, a few studies have adopted pre-training techniques based on the Transformer encoder or decoder to learn the representations from massive traffic data. However, these methods typically excel in traffic understanding (classification) or traffic generation tasks. To address this issue, we develop Lens, a foundation model for network traffic that leverages the T5 architecture to learn the pre-trained representations from large-scale unlabeled data. Harnessing the strength of the encoder-decoder framework, which captures the global information while preserving the generative ability, our model can better learn the representations from raw data. To further enhance pre-training effectiveness, we design a novel loss that combines three distinct tasks: Masked Span Prediction (MSP), Packet Order Prediction (POP), and Homologous Traffic Prediction (HTP). Evaluation results across various benchmark datasets demonstrate that the proposed Lens outperforms the baselines in most downstream tasks related to both traffic understanding and generation. Notably, it also requires much less labeled data for fine-tuning compared to current methods.
Discovering Traveling Companions using Autoencoders
Jul 23, 2020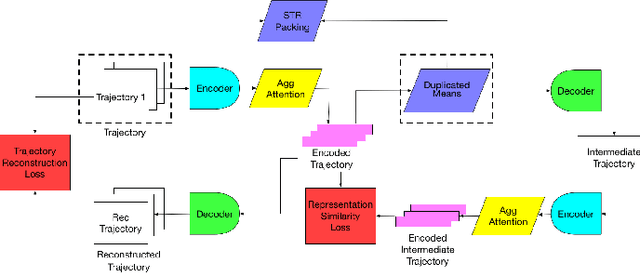
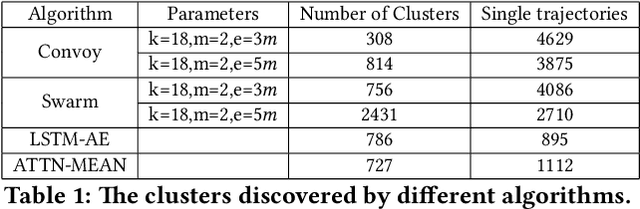
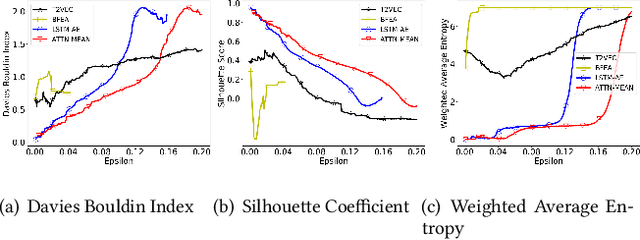
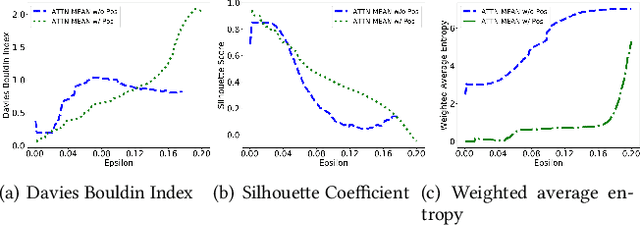
With the wide adoption of mobile devices, today's location tracking systems such as satellites, cellular base stations and wireless access points are continuously producing tremendous amounts of location data of moving objects. The ability to discover moving objects that travel together, i.e., traveling companions, from their trajectories is desired by many applications such as intelligent transportation systems and location-based services. Existing algorithms are either based on pattern mining methods that define a particular pattern of traveling companions or based on representation learning methods that learn similar representations for similar trajectories. The former methods suffer from the pairwise point-matching problem and the latter often ignore the temporal proximity between trajectories. In this work, we propose a generic deep representation learning model using autoencoders, namely, ATTN-MEAN, for the discovery of traveling companions. ATTN-MEAN collectively injects spatial and temporal information into its input embeddings using skip-gram, positional encoding techniques, respectively. Besides, our model further encourages trajectories to learn from their neighbours by leveraging the Sort-Tile-Recursive algorithm, mean operation and global attention mechanism. After obtaining the representations from the encoders, we run DBSCAN to cluster the representations to find travelling companion. The corresponding trajectories in the same cluster are considered as traveling companions. Experimental results suggest that ATTN-MEAN performs better than the state-of-the-art algorithms on finding traveling companions.