 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
MedGEN-Bench: Contextually entangled benchmark for open-ended multimodal medical generation
Nov 18, 2025As Vision-Language Models (VLMs) increasingly gain traction in medical applications, clinicians are progressively expecting AI systems not only to generate textual diagnoses but also to produce corresponding medical images that integrate seamlessly into authentic clinical workflows. Despite the growing interest, existing medical visual benchmarks present notable limitations. They often rely on ambiguous queries that lack sufficient relevance to image content, oversimplify complex diagnostic reasoning into closed-ended shortcuts, and adopt a text-centric evaluation paradigm that overlooks the importance of image generation capabilities. To address these challenges, we introduce MedGEN-Bench, a comprehensive multimodal benchmark designed to advance medical AI research. MedGEN-Bench comprises 6,422 expert-validated image-text pairs spanning six imaging modalities, 16 clinical tasks, and 28 subtasks. It is structured into three distinct formats: Visual Question Answering, Image Editing, and Contextual Multimodal Generation. What sets MedGEN-Bench apart is its focus on contextually intertwined instructions that necessitate sophisticated cross-modal reasoning and open-ended generative outputs, moving beyond the constraints of multiple-choice formats. To evaluate the performance of existing systems, we employ a novel three-tier assessment framework that integrates pixel-level metrics, semantic text analysis, and expert-guided clinical relevance scoring. Using this framework, we systematically assess 10 compositional frameworks, 3 unified models, and 5 VLMs.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
A digital SRAM-based compute-in-memory macro for weight-stationary dynamic matrix multiplication in Transformer attention score computation
Nov 15, 2025



Compute-in-memory (CIM) techniques are widely employed in energy-efficient artificial intelligent (AI) processors. They alleviate power and latency bottlenecks caused by extensive data movements between compute and storage units. This work proposes a digital CIM macro to compute Transformer attention. To mitigate dynamic matrix multiplication that is unsuitable for the common weight-stationary CIM paradigm, we reformulate the attention score computation process based on a combined QK-weight matrix, so that inputs can be directly fed to CIM cells to obtain the score results. Moreover, the involved binomial matrix multiplication operation is decomposed into 4 groups of bit-serial shifting and additions, without costly physical multipliers in the CIM. We maximize the energy efficiency of the CIM circuit through zero-value bit-skipping, data-driven word line activation, read-write separate 6T cells and bit-alternating 14T/28T adders. The proposed CIM macro was implemented using a 65-nm process. It occupied only 0.35 mm2 area, and delivered a 42.27 GOPS peak performance with 1.24 mW power consumption at a 1.0 V power supply and a 100 MHz clock frequency, resulting in 34.1 TOPS/W energy efficiency and 120.77 GOPS/mm2 area efficiency. When compared to the CPU and GPU, our CIM macro is 25x and 13x more energy efficient on practical tasks, respectively. Compared with other Transformer-CIMs, our design exhibits at least 7x energy efficiency and at least 2x area efficiency improvements when scaled to the same technology node, showcasing its potential for edge-side intelligent applications.
NeuSpring: Neural Spring Fields for Reconstruction and Simulation of Deformable Objects from Videos
Nov 11, 2025In this paper, we aim to create physical digital twins of deformable objects under interaction. Existing methods focus more on the physical learning of current state modeling, but generalize worse to future prediction. This is because existing methods ignore the intrinsic physical properties of deformable objects, resulting in the limited physical learning in the current state modeling. To address this, we present NeuSpring, a neural spring field for the reconstruction and simulation of deformable objects from videos. Built upon spring-mass models for realistic physical simulation, our method consists of two major innovations: 1) a piecewise topology solution that efficiently models multi-region spring connection topologies using zero-order optimization, which considers the material heterogeneity of real-world objects. 2) a neural spring field that represents spring physical properties across different frames using a canonical coordinate-based neural network, which effectively leverages the spatial associativity of springs for physical learning. Experiments on real-world datasets demonstrate that our NeuSping achieves superior reconstruction and simulation performance for current state modeling and future prediction, with Chamfer distance improved by 20% and 25%, respectively.
ParaS2S: Benchmarking and Aligning Spoken Language Models for Paralinguistic-aware Speech-to-Speech Interaction
Nov 11, 2025Speech-to-Speech (S2S) models have shown promising dialogue capabilities, but their ability to handle paralinguistic cues--such as emotion, tone, and speaker attributes--and to respond appropriately in both content and style remains underexplored. Progress is further hindered by the scarcity of high-quality and expressive demonstrations. To address this, we introduce a novel reinforcement learning (RL) framework for paralinguistic-aware S2S, ParaS2S, which evaluates and optimizes both content and speaking style directly at the waveform level. We first construct ParaS2SBench, a benchmark comprehensively evaluates S2S models' output for content and style appropriateness from diverse and challenging input queries. It scores the fitness of input-output pairs and aligns well with human judgments, serving as an automatic judge for model outputs. With this scalable scoring feedback, we enable the model to explore and learn from diverse unlabeled speech via Group Relative Policy Optimization (GRPO). Experiments show that existing S2S models fail to respond appropriately to paralinguistic attributes, performing no better than pipeline-based baselines. Our RL approach achieves a 11% relative improvement in response content and style's appropriateness on ParaS2SBench over supervised fine-tuning (SFT), surpassing all prior models while requiring substantially fewer warm-up annotations than pure SFT.
LooGLE v2: Are LLMs Ready for Real World Long Dependency Challenges?
Oct 26, 2025Large language models (LLMs) are equipped with increasingly extended context windows recently, yet their long context understanding capabilities over long dependency tasks remain fundamentally limited and underexplored. This gap is especially significant in many real-world long-context applications that were rarely benchmarked. In this paper, we introduce LooGLE v2, a novel benchmark designed to evaluate LLMs' long context ability in real-world applications and scenarios. Our benchmark consists of automatically collected real-world long texts, ranging from 16k to 2M tokens, encompassing domains in law, finance, game and code. Accordingly, we delicately design 10 types of domain-specific long-dependency tasks and generate 1,934 QA instances with various diversity and complexity in a scalable data curation pipeline for further practical needs. We conduct a comprehensive assessment of 6 locally deployed and 4 API-based LLMs. The evaluation results show that even the best-performing model achieves only a 59.2% overall score on our benchmark. Despite the extensive context windows, popular LLMs are only capable of understanding a much shorter length of context than they claim to be, revealing significant limitations in their ability to handle real-world tasks with long dependencies and highlighting substantial room for model improvement in practical long-context understanding.
Omni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception
Oct 14, 2025Fine-grained perception of multimodal information is critical for advancing human-AI interaction. With recent progress in audio-visual technologies, Omni Language Models (OLMs), capable of processing audio and video signals in parallel, have emerged as a promising paradigm for achieving richer understanding and reasoning. However, their capacity to capture and describe fine-grained details remains limited explored. In this work, we present a systematic and comprehensive investigation of omni detailed perception from the perspectives of the data pipeline, models, and benchmark. We first identify an inherent "co-growth" between detail and hallucination in current OLMs. To address this, we propose Omni-Detective, an agentic data generation pipeline integrating tool-calling, to autonomously produce highly detailed yet minimally hallucinatory multimodal data. Based on the data generated with Omni-Detective, we train two captioning models: Audio-Captioner for audio-only detailed perception, and Omni-Captioner for audio-visual detailed perception. Under the cascade evaluation protocol, Audio-Captioner achieves the best performance on MMAU and MMAR among all open-source models, surpassing Gemini 2.5 Flash and delivering performance comparable to Gemini 2.5 Pro. On existing detailed captioning benchmarks, Omni-Captioner sets a new state-of-the-art on VDC and achieves the best trade-off between detail and hallucination on the video-SALMONN 2 testset. Given the absence of a dedicated benchmark for omni detailed perception, we design Omni-Cloze, a novel cloze-style evaluation for detailed audio, visual, and audio-visual captioning that ensures stable, efficient, and reliable assessment. Experimental results and analysis demonstrate the effectiveness of Omni-Detective in generating high-quality detailed captions, as well as the superiority of Omni-Cloze in evaluating such detailed captions.
AudioMarathon: A Comprehensive Benchmark for Long-Context Audio Understanding and Efficiency in Audio LLMs
Oct 08, 2025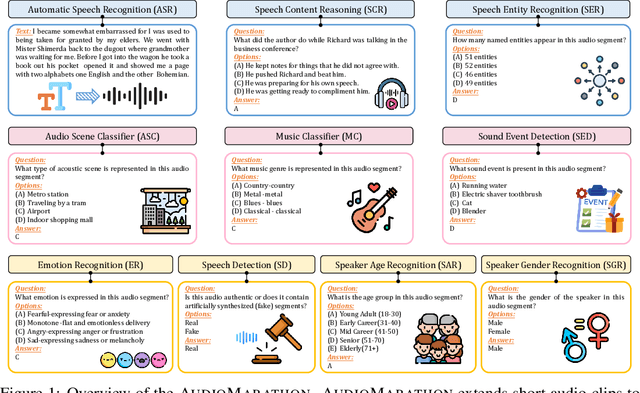
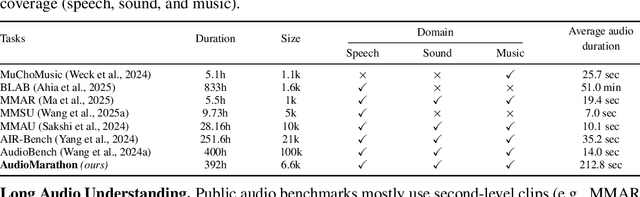
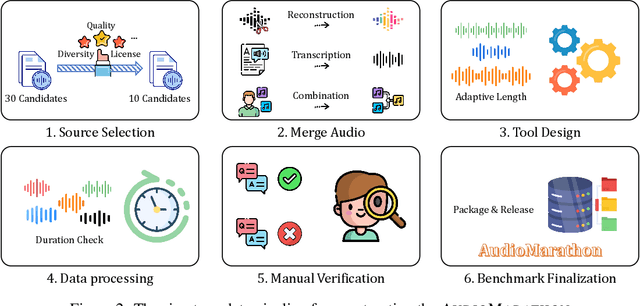

Processing long-form audio is a major challenge for Large Audio Language models (LALMs). These models struggle with the quadratic cost of attention ($O(N^2)$) and with modeling long-range temporal dependencies. Existing audio benchmarks are built mostly from short clips and do not evaluate models in realistic long context settings. To address this gap, we introduce AudioMarathon, a benchmark designed to evaluate both understanding and inference efficiency on long-form audio. AudioMarathon provides a diverse set of tasks built upon three pillars: long-context audio inputs with durations ranging from 90.0 to 300.0 seconds, which correspond to encoded sequences of 2,250 to 7,500 audio tokens, respectively, full domain coverage across speech, sound, and music, and complex reasoning that requires multi-hop inference. We evaluate state-of-the-art LALMs and observe clear performance drops as audio length grows. We also study acceleration techniques and analyze the trade-offs of token pruning and KV cache eviction. The results show large gaps across current LALMs and highlight the need for better temporal reasoning and memory-efficient architectures. We believe AudioMarathon will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
UltraHiT: A Hierarchical Transformer Architecture for Generalizable Internal Carotid Artery Robotic Ultrasonography
Sep 17, 2025Carotid ultrasound is crucial for the assessment of cerebrovascular health, particularly the internal carotid artery (ICA). While previous research has explored automating carotid ultrasound, none has tackled the challenging ICA. This is primarily due to its deep location, tortuous course, and significant individual variations, which greatly increase scanning complexity. To address this, we propose a Hierarchical Transformer-based decision architecture, namely UltraHiT, that integrates high-level variation assessment with low-level action decision. Our motivation stems from conceptualizing individual vascular structures as morphological variations derived from a standard vascular model. The high-level module identifies variation and switches between two low-level modules: an adaptive corrector for variations, or a standard executor for normal cases. Specifically, both the high-level module and the adaptive corrector are implemented as causal transformers that generate predictions based on the historical scanning sequence. To ensure generalizability, we collected the first large-scale ICA scanning dataset comprising 164 trajectories and 72K samples from 28 subjects of both genders. Based on the above innovations, our approach achieves a 95% success rate in locating the ICA on unseen individuals, outperforming baselines and demonstrating its effectiveness. Our code will be released after acceptance.