 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSCNet: Transformer-Based Multimodal Fusion with Segmentation Guidance for Urolithiasis Classification
Apr 08, 2026Kidney stone disease ranks among the most prevalent conditions in urology, and understanding the composition of these stones is essential for creating personalized treatment plans and preventing recurrence. Current methods for analyzing kidney stones depend on postoperative specimens, which prevents rapid classification before surgery. To overcome this limitation, we introduce a new approach called the Urinary Stone Segmentation and Classification Network (USCNet). This innovative method allows for precise preoperative classification of kidney stones by integrating Computed Tomography (CT) images with clinical data from Electronic Health Records (EHR). USCNet employs a Transformer-based multimodal fusion framework with CT-EHR attention and segmentation-guided attention modules for accurate classification. Moreover, a dynamic loss function is introduced to effectively balance the dual objectives of segmentation and classification. Experiments on an in-house kidney stone dataset show that USCNet demonstrates outstanding performance across all evaluation metrics, with its classification efficacy significantly surpassing existing mainstream methods. This study presents a promising solution for the precise preoperative classification of kidney stones, offering substantial clinical benefits. The source code has been made publicly available: https://github.com/ZhangSongqi0506/KidneyStone.
MedGEN-Bench: Contextually entangled benchmark for open-ended multimodal medical generation
Nov 18, 2025As Vision-Language Models (VLMs) increasingly gain traction in medical applications, clinicians are progressively expecting AI systems not only to generate textual diagnoses but also to produce corresponding medical images that integrate seamlessly into authentic clinical workflows. Despite the growing interest, existing medical visual benchmarks present notable limitations. They often rely on ambiguous queries that lack sufficient relevance to image content, oversimplify complex diagnostic reasoning into closed-ended shortcuts, and adopt a text-centric evaluation paradigm that overlooks the importance of image generation capabilities. To address these challenges, we introduce MedGEN-Bench, a comprehensive multimodal benchmark designed to advance medical AI research. MedGEN-Bench comprises 6,422 expert-validated image-text pairs spanning six imaging modalities, 16 clinical tasks, and 28 subtasks. It is structured into three distinct formats: Visual Question Answering, Image Editing, and Contextual Multimodal Generation. What sets MedGEN-Bench apart is its focus on contextually intertwined instructions that necessitate sophisticated cross-modal reasoning and open-ended generative outputs, moving beyond the constraints of multiple-choice formats. To evaluate the performance of existing systems, we employ a novel three-tier assessment framework that integrates pixel-level metrics, semantic text analysis, and expert-guided clinical relevance scoring. Using this framework, we systematically assess 10 compositional frameworks, 3 unified models, and 5 VLMs.
Semi-supervised Medical Image Segmentation Method Based on Cross-pseudo Labeling Leveraging Strong and Weak Data Augmentation Strategies
Feb 17, 2024



Traditional supervised learning methods have historically encountered certain constraints in medical image segmentation due to the challenging collection process, high labeling cost, low signal-to-noise ratio, and complex features characterizing biomedical images. This paper proposes a semi-supervised model, DFCPS, which innovatively incorporates the Fixmatch concept. This significantly enhances the model's performance and generalizability through data augmentation processing, employing varied strategies for unlabeled data. Concurrently, the model design gives appropriate emphasis to the generation, filtration, and refinement processes of pseudo-labels. The novel concept of cross-pseudo-supervision is introduced, integrating consistency learning with self-training. This enables the model to fully leverage pseudo-labels from multiple perspectives, thereby enhancing training diversity. The DFCPS model is compared with both baseline and advanced models using the publicly accessible Kvasir-SEG dataset. Across all four subdivisions containing different proportions of unlabeled data, our model consistently exhibits superior performance. Our source code is available at https://github.com/JustlfC03/DFCPS.
* 5 pages, 2 figures, accept ISBI2024
FedPDC:Federated Learning for Public Dataset Correction
Feb 24, 2023



As people pay more and more attention to privacy protection, Federated Learning (FL), as a promising distributed machine learning paradigm, is receiving more and more attention. However, due to the biased distribution of data on devices in real life, federated learning has lower classification accuracy than traditional machine learning in Non-IID scenarios. Although there are many optimization algorithms, the local model aggregation in the parameter server is still relatively traditional. In this paper, a new algorithm FedPDC is proposed to optimize the aggregation mode of local models and the loss function of local training by using the shared data sets in some industries. In many benchmark experiments, FedPDC can effectively improve the accuracy of the global model in the case of extremely unbalanced data distribution, while ensuring the privacy of the client data. At the same time, the accuracy improvement of FedPDC does not bring additional communication costs.
On the Feasibility of Distributed Kernel Regression for Big Data
May 05, 2015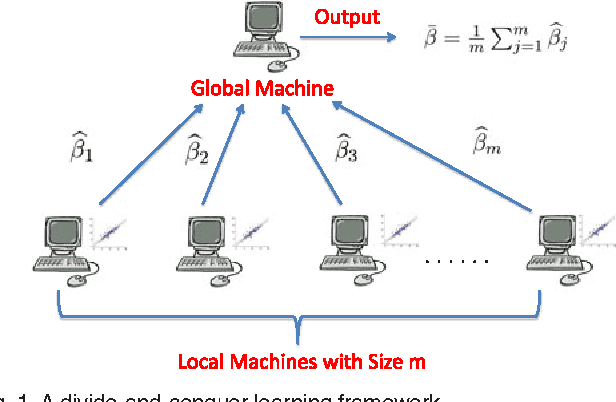
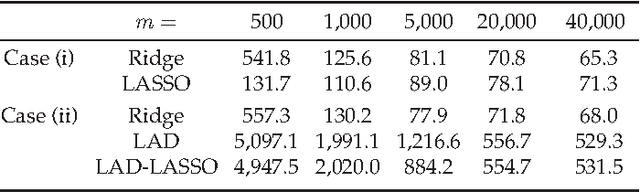
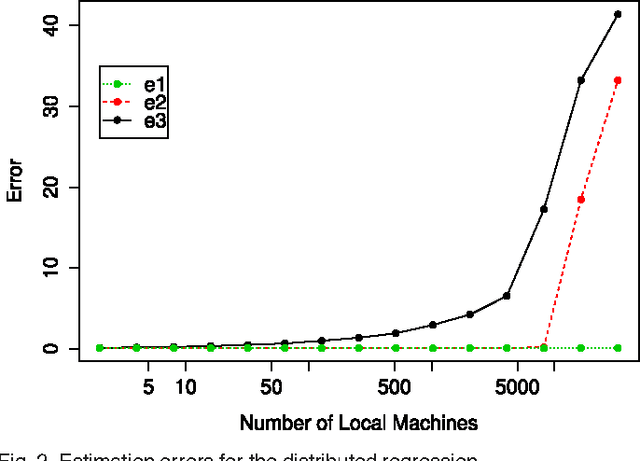

In modern scientific research, massive datasets with huge numbers of observations are frequently encountered. To facilitate the computational process, a divide-and-conquer scheme is often used for the analysis of big data. In such a strategy, a full dataset is first split into several manageable segments; the final output is then averaged from the individual outputs of the segments. Despite its popularity in practice, it remains largely unknown that whether such a distributive strategy provides valid theoretical inferences to the original data. In this paper, we address this fundamental issue for the distributed kernel regression (DKR), where the algorithmic feasibility is measured by the generalization performance of the resulting estimator. To justify DKR, a uniform convergence rate is needed for bounding the generalization error over the individual outputs, which brings new and challenging issues in the big data setup. Under mild conditions, we show that, with a proper number of segments, DKR leads to an estimator that is generalization consistent to the unknown regression function. The obtained results justify the method of DKR and shed light on the feasibility of using other distributed algorithms for processing big data. The promising preference of the method is supported by both simulation and real data examples.