 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraStar: Semantic-Aware Star Graph Modeling for Echocardiography Navigation
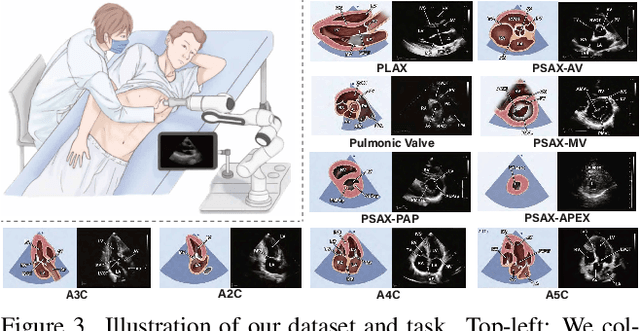
Mar 02, 2026Echocardiography is critical for diagnosing cardiovascular diseases, yet the shortage of skilled sonographers hinders timely patient care, due to high operational difficulties. Consequently, research on automated probe navigation has significant clinical potential. To achieve robust navigation, it is essential to leverage historical scanning information, mimicking how experts rely on past feedback to adjust subsequent maneuvers. Practical scanning data collected from sonographers typically consists of noisy trajectories inherently generated through trial-and-error exploration. However, existing methods typically model this history as a sequential chain, forcing models to overfit these noisy paths, leading to performance degradation on long sequences. In this paper, we propose UltraStar, which reformulates probe navigation from path regression to anchor-based global localization. By establishing a Star Graph, UltraStar treats historical keyframes as spatial anchors connected directly to the current view, explicitly modeling geometric constraints for precise positioning. We further enhance the Star Graph with a semantic-aware sampling strategy that actively selects the representative landmarks from massive history logs, reducing redundancy for accurate anchoring. Extensive experiments on a dataset with over 1.31 million samples demonstrate that UltraStar outperforms baselines and scales better with longer input lengths, revealing a more effective topology for history modeling under noisy exploration.
MOSAIC: Bridging the Sim-to-Real Gap in Generalist Humanoid Motion Tracking and Teleoperation with Rapid Residual Adaptation
Feb 09, 2026Generalist humanoid motion trackers have recently achieved strong simulation metrics by scaling data and training, yet often remain brittle on hardware during sustained teleoperation due to interface- and dynamics-induced errors. We present MOSAIC, an open-source, full-stack system for humanoid motion tracking and whole-body teleoperation across multiple interfaces. MOSAIC first learns a teleoperation-oriented general motion tracker via RL on a multi-source motion bank with adaptive resampling and rewards that emphasize world-frame motion consistency, which is critical for mobile teleoperation. To bridge the sim-to-real interface gap without sacrificing generality, MOSAIC then performs rapid residual adaptation: an interface-specific policy is trained using minimal interface-specific data, and then distilled into the general tracker through an additive residual module, outperforming naive fine-tuning or continual learning. We validate MOSAIC with systematic ablations, out-of-distribution benchmarking, and real-robot experiments demonstrating robust offline motion replay and online long-horizon teleoperation under realistic latency and noise.
DECO: Decoupled Multimodal Diffusion Transformer for Bimanual Dexterous Manipulation with a Plugin Tactile Adapter
Feb 05, 2026Overview of the Proposed DECO Framework.} DECO is a DiT-based policy that decouples multimodal conditioning. Image and action tokens interact via joint self attention, while proprioceptive states and optional conditions are injected through adaptive layer normalization. Tactile signals are injected via cross attention, while a lightweight LoRA-based adapter is used to efficiently fine-tune the pretrained policy. DECO is also accompanied by DECO-50, a bimanual dexterous manipulation dataset with tactile sensing, consisting of 4 scenarios and 28 sub-tasks, covering more than 50 hours of data, approximately 5 million frames, and 8,000 successful trajectories.
Emulating Human-like Adaptive Vision for Efficient and Flexible Machine Visual Perception
Sep 18, 2025Human vision is highly adaptive, efficiently sampling intricate environments by sequentially fixating on task-relevant regions. In contrast, prevailing machine vision models passively process entire scenes at once, resulting in excessive resource demands scaling with spatial-temporal input resolution and model size, yielding critical limitations impeding both future advancements and real-world application. Here we introduce AdaptiveNN, a general framework aiming to drive a paradigm shift from 'passive' to 'active, adaptive' vision models. AdaptiveNN formulates visual perception as a coarse-to-fine sequential decision-making process, progressively identifying and attending to regions pertinent to the task, incrementally combining information across fixations, and actively concluding observation when sufficient. We establish a theory integrating representation learning with self-rewarding reinforcement learning, enabling end-to-end training of the non-differentiable AdaptiveNN without additional supervision on fixation locations. We assess AdaptiveNN on 17 benchmarks spanning 9 tasks, including large-scale visual recognition, fine-grained discrimination, visual search, processing images from real driving and medical scenarios, language-driven embodied AI, and side-by-side comparisons with humans. AdaptiveNN achieves up to 28x inference cost reduction without sacrificing accuracy, flexibly adapts to varying task demands and resource budgets without retraining, and provides enhanced interpretability via its fixation patterns, demonstrating a promising avenue toward efficient, flexible, and interpretable computer vision. Furthermore, AdaptiveNN exhibits closely human-like perceptual behaviors in many cases, revealing its potential as a valuable tool for investigating visual cognition. Code is available at https://github.com/LeapLabTHU/AdaptiveNN.
UltraHiT: A Hierarchical Transformer Architecture for Generalizable Internal Carotid Artery Robotic Ultrasonography
Sep 17, 2025Carotid ultrasound is crucial for the assessment of cerebrovascular health, particularly the internal carotid artery (ICA). While previous research has explored automating carotid ultrasound, none has tackled the challenging ICA. This is primarily due to its deep location, tortuous course, and significant individual variations, which greatly increase scanning complexity. To address this, we propose a Hierarchical Transformer-based decision architecture, namely UltraHiT, that integrates high-level variation assessment with low-level action decision. Our motivation stems from conceptualizing individual vascular structures as morphological variations derived from a standard vascular model. The high-level module identifies variation and switches between two low-level modules: an adaptive corrector for variations, or a standard executor for normal cases. Specifically, both the high-level module and the adaptive corrector are implemented as causal transformers that generate predictions based on the historical scanning sequence. To ensure generalizability, we collected the first large-scale ICA scanning dataset comprising 164 trajectories and 72K samples from 28 subjects of both genders. Based on the above innovations, our approach achieves a 95% success rate in locating the ICA on unseen individuals, outperforming baselines and demonstrating its effectiveness. Our code will be released after acceptance.
EchoWorld: Learning Motion-Aware World Models for Echocardiography Probe Guidance
Apr 17, 2025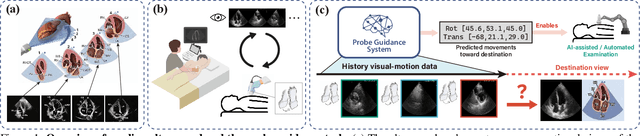


Echocardiography is crucial for cardiovascular disease detection but relies heavily on experienced sonographers. Echocardiography probe guidance systems, which provide real-time movement instructions for acquiring standard plane images, offer a promising solution for AI-assisted or fully autonomous scanning. However, developing effective machine learning models for this task remains challenging, as they must grasp heart anatomy and the intricate interplay between probe motion and visual signals. To address this, we present EchoWorld, a motion-aware world modeling framework for probe guidance that encodes anatomical knowledge and motion-induced visual dynamics, while effectively leveraging past visual-motion sequences to enhance guidance precision. EchoWorld employs a pre-training strategy inspired by world modeling principles, where the model predicts masked anatomical regions and simulates the visual outcomes of probe adjustments. Built upon this pre-trained model, we introduce a motion-aware attention mechanism in the fine-tuning stage that effectively integrates historical visual-motion data, enabling precise and adaptive probe guidance. Trained on more than one million ultrasound images from over 200 routine scans, EchoWorld effectively captures key echocardiographic knowledge, as validated by qualitative analysis. Moreover, our method significantly reduces guidance errors compared to existing visual backbones and guidance frameworks, excelling in both single-frame and sequential evaluation protocols. Code is available at https://github.com/LeapLabTHU/EchoWorld.
Sequence-aware Pre-training for Echocardiography Probe Guidance
Aug 27, 2024Cardiac ultrasound probe guidance aims to help novices adjust the 6-DOF probe pose to obtain high-quality sectional images. Cardiac ultrasound faces two major challenges: (1) the inherently complex structure of the heart, and (2) significant individual variations. Previous works have only learned the population-averaged 2D and 3D structures of the heart rather than personalized cardiac structural features, leading to a performance bottleneck. Clinically, we observed that sonographers adjust their understanding of a patient's cardiac structure based on prior scanning sequences, thereby modifying their scanning strategies. Inspired by this, we propose a sequence-aware self-supervised pre-training method. Specifically, our approach learns personalized 2D and 3D cardiac structural features by predicting the masked-out images and actions in a scanning sequence. We hypothesize that if the model can predict the missing content it has acquired a good understanding of the personalized cardiac structure. In the downstream probe guidance task, we also introduced a sequence modeling approach that models individual cardiac structural information based on the images and actions from historical scan data, enabling more accurate navigation decisions. Experiments on a large-scale dataset with 1.36 million samples demonstrated that our proposed sequence-aware paradigm can significantly reduce navigation errors, with translation errors decreasing by 15.90% to 36.87% and rotation errors decreasing by 11.13% to 20.77%, compared to state-of-the-art methods.
Structure-aware World Model for Probe Guidance via Large-scale Self-supervised Pre-train
Jun 28, 2024



The complex structure of the heart leads to significant challenges in echocardiography, especially in acquisition cardiac ultrasound images. Successful echocardiography requires a thorough understanding of the structures on the two-dimensional plane and the spatial relationships between planes in three-dimensional space. In this paper, we innovatively propose a large-scale self-supervised pre-training method to acquire a cardiac structure-aware world model. The core innovation lies in constructing a self-supervised task that requires structural inference by predicting masked structures on a 2D plane and imagining another plane based on pose transformation in 3D space. To support large-scale pre-training, we collected over 1.36 million echocardiograms from ten standard views, along with their 3D spatial poses. In the downstream probe guidance task, we demonstrate that our pre-trained model consistently reduces guidance errors across the ten most common standard views on the test set with 0.29 million samples from 74 routine clinical scans, indicating that structure-aware pre-training benefits the scanning.
Cardiac Copilot: Automatic Probe Guidance for Echocardiography with World Model
Jun 19, 2024



Echocardiography is the only technique capable of real-time imaging of the heart and is vital for diagnosing the majority of cardiac diseases. However, there is a severe shortage of experienced cardiac sonographers, due to the heart's complex structure and significant operational challenges. To mitigate this situation, we present a Cardiac Copilot system capable of providing real-time probe movement guidance to assist less experienced sonographers in conducting freehand echocardiography. This system can enable non-experts, especially in primary departments and medically underserved areas, to perform cardiac ultrasound examinations, potentially improving global healthcare delivery. The core innovation lies in proposing a data-driven world model, named Cardiac Dreamer, for representing cardiac spatial structures. This world model can provide structure features of any cardiac planes around the current probe position in the latent space, serving as an precise navigation map for autonomous plane localization. We train our model with real-world ultrasound data and corresponding probe motion from 110 routine clinical scans with 151K sample pairs by three certified sonographers. Evaluations on three standard planes with 37K sample pairs demonstrate that the world model can reduce navigation errors by up to 33\% and exhibit more stable performance.
LocalGCL: Local-aware Contrastive Learning for Graphs
Feb 27, 2024Graph representation learning (GRL) makes considerable progress recently, which encodes graphs with topological structures into low-dimensional embeddings. Meanwhile, the time-consuming and costly process of annotating graph labels manually prompts the growth of self-supervised learning (SSL) techniques. As a dominant approach of SSL, Contrastive learning (CL) learns discriminative representations by differentiating between positive and negative samples. However, when applied to graph data, it overemphasizes global patterns while neglecting local structures. To tackle the above issue, we propose \underline{Local}-aware \underline{G}raph \underline{C}ontrastive \underline{L}earning (\textbf{\methnametrim}), a self-supervised learning framework that supplementarily captures local graph information with masking-based modeling compared with vanilla contrastive learning. Extensive experiments validate the superiority of \methname against state-of-the-art methods, demonstrating its promise as a comprehensive graph representation learner.