 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectro-Temporal Interference Confounds Phase Encoding in Spatial Audio Foundation Models
Jun 12, 2026Recent spatial self supervised audio models achieve high performance on localization tasks, raising questions about their encoding of microsecond interaural phase fine structures. We propose a psychoacoustic benchmark based on the binaural masking level difference to evaluate this. Using an equalization cancellation baseline and a GCC PHAT positive control we evaluate nine frozen audio models spanning binaural SSL, monaural SSL, and neural audio codecs. Four monaural negative controls yield zero BMLD confirming binaural specificity. Two general purpose binaural SSL models exhibit minimal phase sensitivity while dedicated binaural spatial SSL models achieve BMLD comparable to the analytical baseline. Progressive physical ablations show that general purpose binaural SSL models rely on spectro temporal interference textures rather than cross channel phase computation. High detection rates in speech reflect a confounding reliance on broadband envelopes rather than genuine phase encoding.
Inside the Latent Flow: Causal Deciphering of Attention Dynamics in Audio Separation Foundation Models
Jun 08, 2026Flow-matching transformers achieve strong audio separation, yet their attention dynamics are opaque. We adapt established causal-intervention principles into a deterministic, inference-time probing protocol for SAM Audio. Orthogonal probing uncovers a dual-pathway text-conditioning mechanism: additive injections control semantic identity, while cross-attention refines acoustic structure. We observe an asynchronous layerwise convergence: stable layers build temporal scaffolds early, whereas fast layers continue resolving artifacts during sampling. The model also attenuates temporal segmentation cues to maintain continuous-flow stability. Using these insights, we propose Layer-Selective Attention Caching (LSAC), a training-free acceleration method that caches attention in stable layers. Across acoustic complexities, LSAC cuts self-attention computation by about ~25% with negligible quality loss and yields up to 6.7x higher quality retention than naive step reduction.
HeadRouter: Dynamic Head-Weight Routing for Task-Adaptive Audio Token Pruning in Large Audio Language Models
Apr 26, 2026Recent large audio language models (LALMs) demonstrate remarkable capabilities in processing extended multi-modal sequences, yet incur high inference costs. Token compression is an effective method that directly reduces redundant tokens in the sequence. Existing compression methods usually assume that all attention heads in LALMs contribute equally to various audio tasks and calculate token importance by averaging scores across all heads. However, our analysis demonstrates that attention heads exhibit distinct behaviors across diverse audio domains. We further reveal that only a sparse subset of attention heads actively responds to audio, with completely different performance when handling semantic and acoustic tasks. In light of this observation, we propose HeadRouter, a head-importance-aware token pruning method that perceives the varying importance of attention heads in different audio tasks to maximize the retention of crucial tokens. HeadRouter is training-free and can be applied to various LALMs. Extensive experiments on the AudioMarathon and MMAU-Pro benchmarks demonstrate that HeadRouter achieves state-of-the-art compression performance, exceeding the baseline model even when retaining 70% of the audio tokens and achieving 101.8% and 103.0% of the vanilla average on Qwen2.5-Omni-3B and Qwen2.5-Omni-7B, respectively.
UniWhisper: Efficient Continual Multi-task Training for Robust Universal Audio Representation
Feb 25, 2026A universal audio representation should capture fine-grained speech cues and high-level semantics for environmental sounds and music in a single encoder. Existing encoders often excel in one domain but degrade in others. We propose UniWhisper, an efficient continual multi-task training framework that casts heterogeneous audio tasks into a unified instruction and answer format. This enables standard next-token training without task-specific heads and losses. We train it on 38k hours of public audio and assess the encoder using shallow MLP probes and k-nearest neighbors (kNN) on 20 tasks spanning speech, environmental sound, and music. UniWhisper reaches normalized weighted averages of 0.81 with MLP probes and 0.61 with kNN, compared to 0.64 and 0.46 for Whisper, while retaining strong speech performance.
AudioMarathon: A Comprehensive Benchmark for Long-Context Audio Understanding and Efficiency in Audio LLMs
Oct 08, 2025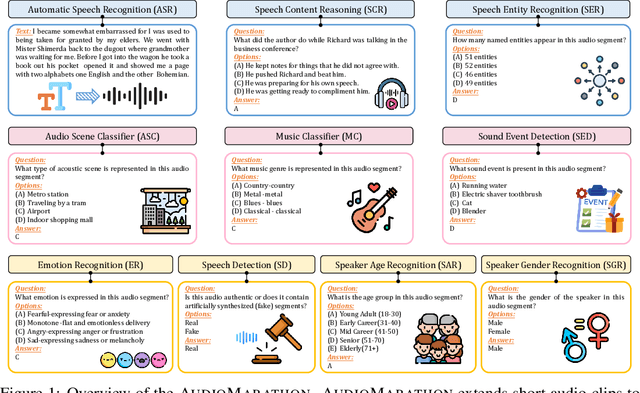
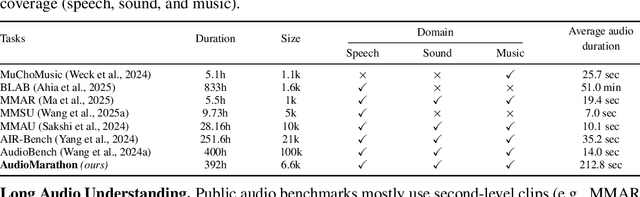
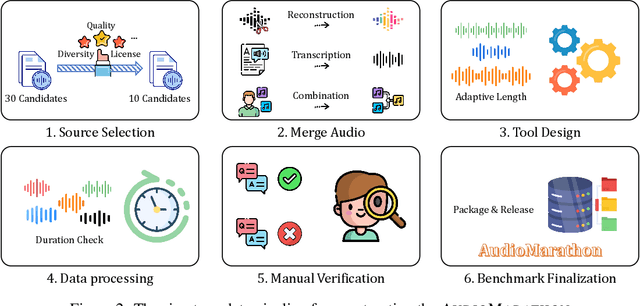

Processing long-form audio is a major challenge for Large Audio Language models (LALMs). These models struggle with the quadratic cost of attention ($O(N^2)$) and with modeling long-range temporal dependencies. Existing audio benchmarks are built mostly from short clips and do not evaluate models in realistic long context settings. To address this gap, we introduce AudioMarathon, a benchmark designed to evaluate both understanding and inference efficiency on long-form audio. AudioMarathon provides a diverse set of tasks built upon three pillars: long-context audio inputs with durations ranging from 90.0 to 300.0 seconds, which correspond to encoded sequences of 2,250 to 7,500 audio tokens, respectively, full domain coverage across speech, sound, and music, and complex reasoning that requires multi-hop inference. We evaluate state-of-the-art LALMs and observe clear performance drops as audio length grows. We also study acceleration techniques and analyze the trade-offs of token pruning and KV cache eviction. The results show large gaps across current LALMs and highlight the need for better temporal reasoning and memory-efficient architectures. We believe AudioMarathon will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.