 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Vision-Language-Action Model Fine-Tuning with Structured Stage and Keyframe Supervision
Jun 25, 2026Vision-Language-Action (VLA) models have shown strong potential for generalizable robotic manipulation. During fine-tuning, however, action supervision applies equally across all timesteps, without structured supervision on which manipulation stage the robot is in or what the next gripper-event target should be. This causes failures to concentrate around challenging gripper-event transitions. To address this, we propose StaKe, a plug-in auxiliary supervision framework that automatically derives two complementary signals from demonstration gripper states without manual annotation: a stage classifier that identifies the current manipulation stage, and a keyframe predictor that estimates the target joint action at the next gripper transition. Both are modeled as lightweight auxiliary heads that enrich the learned representations during training, while leaving the base VLA policy architecture and inference loop unchanged. Experiments on bimanual simulation and single-arm Franka real-robot tasks show that StaKe consistently improves success rates (relative gains of 14% and 56%, respectively), with larger improvements on longer-horizon tasks that involve more gripper-event transitions. Ablation studies validate each design choice, and qualitative analysis confirms that the learned representations faithfully track manipulation stages. These results indicate that structured supervision is an effective and general strategy for enhancing VLA fine-tuning in long-horizon manipulation. Project website: https://hi-yuanxu.github.io/StaKe-Web/
When Seeing Is Not Believing -- A Benchmark for Search-Grounded Video Misinformation Detection
Jun 02, 2026Video misinformation increasingly operates at the semantic and evidential level: authentic footage may be selectively edited, temporally reordered, spliced across sources, or augmented with AI-generated content to construct false narratives. Such evidence-dependent manipulations cannot be reliably verified from the input video alone, because the missing, reordered, replaced, or recontextualized evidence lies outside the video itself. We introduce \textbf{EVID-Bench}, a benchmark for search-grounded video misinformation detection, where a system must search the open web for related videos and identify what information is false through cross-video comparison. EVID-Bench comprises 222 videos spanning 9 manipulation types across 3 categories: AI generation, single-source editing, and multi-source editing. All samples are verified to be undetectable by frontier models through visual inspection alone. We evaluate nine frontier multimodal models using a retrieval-augmented verification baseline. The best system achieves only 61.43\% point-level accuracy and 43.24\% video-level accuracy, while AI-generated manipulations remain especially challenging. Error analysis reveals recurring challenges: models fixate on irrelevant anchors, misattribute synthetic content to editorial splicing, and terminate search prematurely before fully explaining the manipulation.
SKIP: Sparse Keyframe Interpolation Paradigm for Efficient Embodied World Models
May 30, 2026Embodied world models have emerged as a promising paradigm in robotics by predicting how robot actions affect the surrounding scene. However, the rollout inference remains computationally expensive in pixel space, as long-horizon manipulation videos typically have to be generated frame by frame. This cost cannot be easily reduced by indiscriminately dropping frames, since downstream policies rely on complete preservation of sparse task-relevant events such as approach, contact, grasp, and release. To address this challenge, we propose Sparse Keyframe Interpolation Paradigm (SKIP), an event-preserving sparse-to-dense framework that avoids dense frame-by-frame generation. SKIP first identifies task-relevant keyframes by leveraging robot-aware multimodal features. It then synthesizes only these keyframes with a sparse video diffusion model. A learned gap predictor and an action-conditioned interpolator subsequently reconstruct the missing intervals according to the robot actions. On LIBERO, SKIP generates dense rollouts $4.16\times$ faster than a dense baseline while improving visual fidelity and reducing aggregate FVD by $89.0\%$. Importantly, SKIP-generated videos are effective policy-training data. Even when they fully replace real demonstrations, $π_{0.5}$ success drops only $1.3$ pp in LIBERO simulation and $6.7$ pp on the real robot, whereas fully dense frame-by-frame generation collapses by $48$ to $58$ pp.
Multi-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model
Apr 03, 2026Robotic manipulation requires understanding both the 3D spatial structure of the environment and its temporal evolution, yet most existing policies overlook one or both. They typically rely on 2D visual observations and backbones pretrained on static image--text pairs, resulting in high data requirements and limited understanding of environment dynamics. To address this, we introduce MV-VDP, a multi-view video diffusion policy that jointly models the 3D spatio-temporal state of the environment. The core idea is to simultaneously predict multi-view heatmap videos and RGB videos, which 1) align the representation format of video pretraining with action finetuning, and 2) specify not only what actions the robot should take, but also how the environment is expected to evolve in response to those actions. Extensive experiments show that MV-VDP enables data-efficient, robust, generalizable, and interpretable manipulation. With only ten demonstration trajectories and without additional pretraining, MV-VDP successfully performs complex real-world tasks, demonstrates strong robustness across a range of model hyperparameters, generalizes to out-of-distribution settings, and predicts realistic future videos. Experiments on Meta-World and real-world robotic platforms demonstrate that MV-VDP consistently outperforms video-prediction--based, 3D-based, and vision--language--action models, establishing a new state of the art in data-efficient multi-task manipulation.
Beyond Closed-Pool Video Retrieval: A Benchmark and Agent Framework for Real-World Video Search and Moment Localization
Feb 10, 2026Traditional video retrieval benchmarks focus on matching precise descriptions to closed video pools, failing to reflect real-world searches characterized by fuzzy, multi-dimensional memories on the open web. We present \textbf{RVMS-Bench}, a comprehensive system for evaluating real-world video memory search. It consists of \textbf{1,440 samples} spanning \textbf{20 diverse categories} and \textbf{four duration groups}, sourced from \textbf{real-world open-web videos}. RVMS-Bench utilizes a hierarchical description framework encompassing \textbf{Global Impression, Key Moment, Temporal Context, and Auditory Memory} to mimic realistic multi-dimensional search cues, with all samples strictly verified via a human-in-the-loop protocol. We further propose \textbf{RACLO}, an agentic framework that employs abductive reasoning to simulate the human ``Recall-Search-Verify'' cognitive process, effectively addressing the challenge of searching for videos via fuzzy memories in the real world. Experiments reveal that existing MLLMs still demonstrate insufficient capabilities in real-world Video Retrieval and Moment Localization based on fuzzy memories. We believe this work will facilitate the advancement of video retrieval robustness in real-world unstructured scenarios.
PaperX: A Unified Framework for Multimodal Academic Presentation Generation with Scholar DAG
Feb 05, 2026Transforming scientific papers into multimodal presentation content is essential for research dissemination but remains labor intensive. Existing automated solutions typically treat each format as an isolated downstream task, leading to redundant processing and semantic inconsistency. We introduce PaperX, a unified framework that models academic presentation generation as a structural transformation and rendering process. Central to our approach is the Scholar DAG, an intermediate representation that decouples the paper's logical structure from its final presentation syntax. By applying adaptive graph traversal strategies, PaperX generates diverse, high quality outputs from a single source. Comprehensive evaluations demonstrate that our framework achieves the state of the art performance in content fidelity and aesthetic quality while significantly improving cost efficiency compared to specialized single task agents.
BridgeV2W: Bridging Video Generation Models to Embodied World Models via Embodiment Masks
Feb 03, 2026Embodied world models have emerged as a promising paradigm in robotics, most of which leverage large-scale Internet videos or pretrained video generation models to enrich visual and motion priors. However, they still face key challenges: a misalignment between coordinate-space actions and pixel-space videos, sensitivity to camera viewpoint, and non-unified architectures across embodiments. To this end, we present BridgeV2W, which converts coordinate-space actions into pixel-aligned embodiment masks rendered from the URDF and camera parameters. These masks are then injected into a pretrained video generation model via a ControlNet-style pathway, which aligns the action control signals with predicted videos, adds view-specific conditioning to accommodate camera viewpoints, and yields a unified world model architecture across embodiments. To mitigate overfitting to static backgrounds, BridgeV2W further introduces a flow-based motion loss that focuses on learning dynamic and task-relevant regions. Experiments on single-arm (DROID) and dual-arm (AgiBot-G1) datasets, covering diverse and challenging conditions with unseen viewpoints and scenes, show that BridgeV2W improves video generation quality compared to prior state-of-the-art methods. We further demonstrate the potential of BridgeV2W on downstream real-world tasks, including policy evaluation and goal-conditioned planning. More results can be found on our project website at https://BridgeV2W.github.io .
ShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
ToolWeaver: Weaving Collaborative Semantics for Scalable Tool Use in Large Language Models
Jan 29, 2026Prevalent retrieval-based tool-use pipelines struggle with a dual semantic challenge: their retrievers often employ encoders that fail to capture complex semantics, while the Large Language Model (LLM) itself lacks intrinsic tool knowledge from its natural language pretraining. Generative methods offer a powerful alternative by unifying selection and execution, tasking the LLM to directly learn and generate tool identifiers. However, the common practice of mapping each tool to a unique new token introduces substantial limitations: it creates a scalability and generalization crisis, as the vocabulary size explodes and each tool is assigned a semantically isolated token. This approach also creates a semantic bottleneck that hinders the learning of collaborative tool relationships, as the model must infer them from sparse co-occurrences of monolithic tool IDs within a vast library. To address these limitations, we propose ToolWeaver, a novel generative tool learning framework that encodes tools into hierarchical sequences. This approach makes vocabulary expansion logarithmic to the number of tools. Crucially, it enables the model to learn collaborative patterns from the dense co-occurrence of shared codes, rather than the sparse co-occurrence of monolithic tool IDs. We generate these structured codes through a novel tokenization process designed to weave together a tool's intrinsic semantics with its extrinsic co-usage patterns. These structured codes are then integrated into the LLM through a generative alignment stage, where the model is fine-tuned to produce the hierarchical code sequences. Evaluation results with nearly 47,000 tools show that ToolWeaver significantly outperforms state-of-the-art methods, establishing a more scalable, generalizable, and semantically-aware foundation for advanced tool-augmented agents.
AudioMarathon: A Comprehensive Benchmark for Long-Context Audio Understanding and Efficiency in Audio LLMs
Oct 08, 2025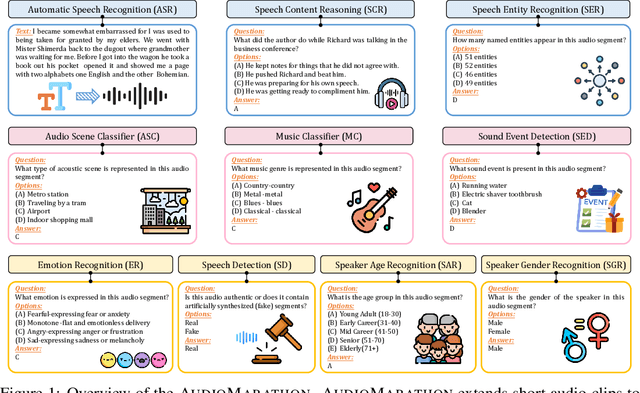
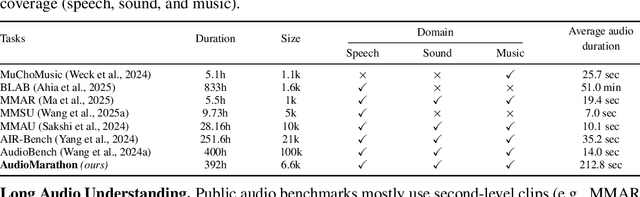
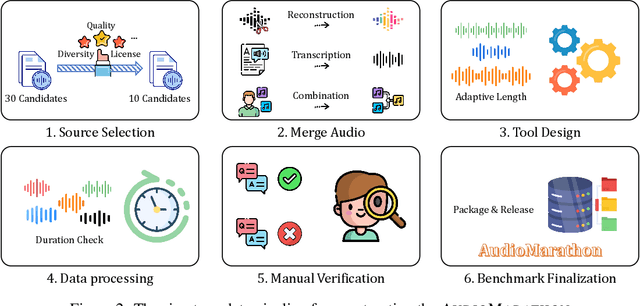

Processing long-form audio is a major challenge for Large Audio Language models (LALMs). These models struggle with the quadratic cost of attention ($O(N^2)$) and with modeling long-range temporal dependencies. Existing audio benchmarks are built mostly from short clips and do not evaluate models in realistic long context settings. To address this gap, we introduce AudioMarathon, a benchmark designed to evaluate both understanding and inference efficiency on long-form audio. AudioMarathon provides a diverse set of tasks built upon three pillars: long-context audio inputs with durations ranging from 90.0 to 300.0 seconds, which correspond to encoded sequences of 2,250 to 7,500 audio tokens, respectively, full domain coverage across speech, sound, and music, and complex reasoning that requires multi-hop inference. We evaluate state-of-the-art LALMs and observe clear performance drops as audio length grows. We also study acceleration techniques and analyze the trade-offs of token pruning and KV cache eviction. The results show large gaps across current LALMs and highlight the need for better temporal reasoning and memory-efficient architectures. We believe AudioMarathon will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.