 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Second Challenge on Real-World Face Restoration at NTIRE 2026: Methods and Results
Apr 12, 2026This paper provides a review of the NTIRE 2026 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural and realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. Performance is evaluated using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 96 registrants, with 10 teams submitting valid models; ultimately, 9 teams achieved valid scores in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Index-ASR Technical Report
Dec 31, 2025Automatic speech recognition (ASR) has witnessed remarkable progress in recent years, largely driven by the emergence of LLM-based ASR paradigm. Despite their strong performance on a variety of open-source benchmarks, existing LLM-based ASR systems still suffer from two critical limitations. First, they are prone to hallucination errors, often generating excessively long and repetitive outputs that are not well grounded in the acoustic input. Second, they provide limited support for flexible and fine-grained contextual customization. To address these challenges, we propose Index-ASR, a large-scale LLM-based ASR system designed to simultaneously enhance robustness and support customizable hotword recognition. The core idea of Index-ASR lies in the integration of LLM and large-scale training data enriched with background noise and contextual information. Experimental results show that our Index-ASR achieves strong performance on both open-source benchmarks and in-house test sets, highlighting its robustness and practicality for real-world ASR applications.
JoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
Rethinking Langevin Thompson Sampling from A Stochastic Approximation Perspective
Oct 06, 2025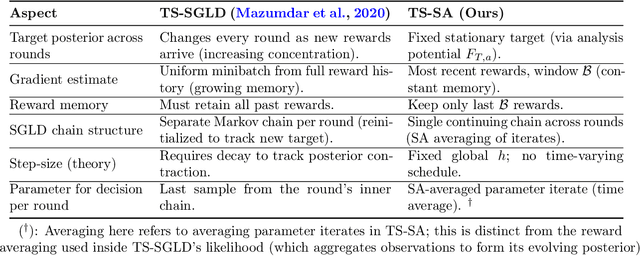
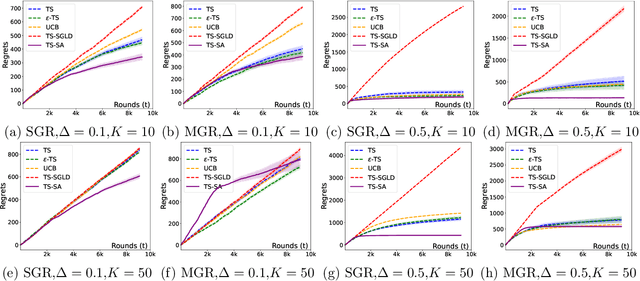

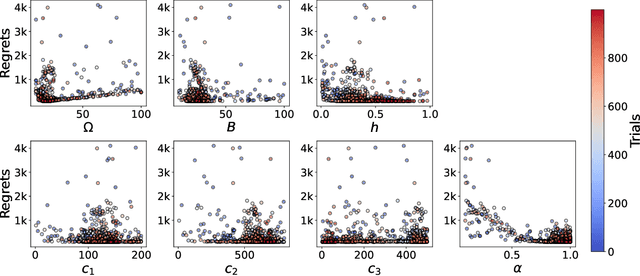
Most existing approximate Thompson Sampling (TS) algorithms for multi-armed bandits use Stochastic Gradient Langevin Dynamics (SGLD) or its variants in each round to sample from the posterior, relaxing the need for conjugacy assumptions between priors and reward distributions in vanilla TS. However, they often require approximating a different posterior distribution in different round of the bandit problem. This requires tricky, round-specific tuning of hyperparameters such as dynamic learning rates, causing challenges in both theoretical analysis and practical implementation. To alleviate this non-stationarity, we introduce TS-SA, which incorporates stochastic approximation (SA) within the TS framework. In each round, TS-SA constructs a posterior approximation only using the most recent reward(s), performs a Langevin Monte Carlo (LMC) update, and applies an SA step to average noisy proposals over time. This can be interpreted as approximating a stationary posterior target throughout the entire algorithm, which further yields a fixed step-size, a unified convergence analysis framework, and improved posterior estimates through temporal averaging. We establish near-optimal regret bounds for TS-SA, with a simplified and more intuitive theoretical analysis enabled by interpreting the entire algorithm as a simulation of a stationary SGLD process. Our empirical results demonstrate that even a single-step Langevin update with certain warm-up outperforms existing methods substantially on bandit tasks.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Optimal Stochastic Trace Estimation in Generative Modeling
Feb 26, 2025



Hutchinson estimators are widely employed in training divergence-based likelihoods for diffusion models to ensure optimal transport (OT) properties. However, this estimator often suffers from high variance and scalability concerns. To address these challenges, we investigate Hutch++, an optimal stochastic trace estimator for generative models, designed to minimize training variance while maintaining transport optimality. Hutch++ is particularly effective for handling ill-conditioned matrices with large condition numbers, which commonly arise when high-dimensional data exhibits a low-dimensional structure. To mitigate the need for frequent and costly QR decompositions, we propose practical schemes that balance frequency and accuracy, backed by theoretical guarantees. Our analysis demonstrates that Hutch++ leads to generations of higher quality. Furthermore, this method exhibits effective variance reduction in various applications, including simulations, conditional time series forecasts, and image generation.
IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System
Feb 08, 2025



Recently, large language model (LLM) based text-to-speech (TTS) systems have gradually become the mainstream in the industry due to their high naturalness and powerful zero-shot voice cloning capabilities.Here, we introduce the IndexTTS system, which is mainly based on the XTTS and Tortoise model. We add some novel improvements. Specifically, in Chinese scenarios, we adopt a hybrid modeling method that combines characters and pinyin, making the pronunciations of polyphonic characters and long-tail characters controllable. We also performed a comparative analysis of the Vector Quantization (VQ) with Finite-Scalar Quantization (FSQ) for codebook utilization of acoustic speech tokens. To further enhance the effect and stability of voice cloning, we introduce a conformer-based speech conditional encoder and replace the speechcode decoder with BigVGAN2. Compared with XTTS, it has achieved significant improvements in naturalness, content consistency, and zero-shot voice cloning. As for the popular TTS systems in the open-source, such as Fish-Speech, CosyVoice2, FireRedTTS and F5-TTS, IndexTTS has a relatively simple training process, more controllable usage, and faster inference speed. Moreover, its performance surpasses that of these systems. Our demos are available at https://index-tts.github.io.
Variational Schrödinger Momentum Diffusion
Jan 28, 2025



The momentum Schr\"odinger Bridge (mSB) has emerged as a leading method for accelerating generative diffusion processes and reducing transport costs. However, the lack of simulation-free properties inevitably results in high training costs and affects scalability. To obtain a trade-off between transport properties and scalability, we introduce variational Schr\"odinger momentum diffusion (VSMD), which employs linearized forward score functions (variational scores) to eliminate the dependence on simulated forward trajectories. Our approach leverages a multivariate diffusion process with adaptively transport-optimized variational scores. Additionally, we apply a critical-damping transform to stabilize training by removing the need for score estimations for both velocity and samples. Theoretically, we prove the convergence of samples generated with optimal variational scores and momentum diffusion. Empirical results demonstrate that VSMD efficiently generates anisotropic shapes while maintaining transport efficacy, outperforming overdamped alternatives, and avoiding complex denoising processes. Our approach also scales effectively to real-world data, achieving competitive results in time series and image generation.
Denoising Fisher Training For Neural Implicit Samplers
Nov 03, 2024



Efficient sampling from un-normalized target distributions is pivotal in scientific computing and machine learning. While neural samplers have demonstrated potential with a special emphasis on sampling efficiency, existing neural implicit samplers still have issues such as poor mode covering behavior, unstable training dynamics, and sub-optimal performances. To tackle these issues, in this paper, we introduce Denoising Fisher Training (DFT), a novel training approach for neural implicit samplers with theoretical guarantees. We frame the training problem as an objective of minimizing the Fisher divergence by deriving a tractable yet equivalent loss function, which marks a unique theoretical contribution to assessing the intractable Fisher divergences. DFT is empirically validated across diverse sampling benchmarks, including two-dimensional synthetic distribution, Bayesian logistic regression, and high-dimensional energy-based models (EBMs). Notably, in experiments with high-dimensional EBMs, our best one-step DFT neural sampler achieves results on par with MCMC methods with up to 200 sampling steps, leading to a substantially greater efficiency over 100 times higher. This result not only demonstrates the superior performance of DFT in handling complex high-dimensional sampling but also sheds light on efficient sampling methodologies across broader applications.
Recurrent Interpolants for Probabilistic Time Series Prediction
Sep 18, 2024



Sequential models such as recurrent neural networks or transformer-based models became \textit{de facto} tools for multivariate time series forecasting in a probabilistic fashion, with applications to a wide range of datasets, such as finance, biology, medicine, etc. Despite their adeptness in capturing dependencies, assessing prediction uncertainty, and efficiency in training, challenges emerge in modeling high-dimensional complex distributions and cross-feature dependencies. To tackle these issues, recent works delve into generative modeling by employing diffusion or flow-based models. Notably, the integration of stochastic differential equations or probability flow successfully extends these methods to probabilistic time series imputation and forecasting. However, scalability issues necessitate a computational-friendly framework for large-scale generative model-based predictions. This work proposes a novel approach by blending the computational efficiency of recurrent neural networks with the high-quality probabilistic modeling of the diffusion model, which addresses challenges and advances generative models' application in time series forecasting. Our method relies on the foundation of stochastic interpolants and the extension to a broader conditional generation framework with additional control features, offering insights for future developments in this dynamic field.