 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTaR-KV: Spatio-Temporal Adaptive Re-weighting for KV Cache Compression in GUI Vision-Language Models
Jun 01, 2026Vision-language-model-based graphical user interface (GUI) agents have shown broad automation capabilities, yet deployment is bottlenecked by a key-value (KV) cache that grows linearly with interaction steps. For instance, UI-TARS-1.5-7B consumes 76 GB of GPU memory on merely five screenshots, approaching the capacity of mainstream 80 GB accelerators. Existing KV compression methods share two structural assumptions: aggregating visual-token importance into a single shared saliency map, and applying a fixed top-B cutoff to the fused score distribution. Pilot measurements refute both: spatial specialization lives at the attention-subspace level and migrates across layers, while the score distribution drifts in shape along a trajectory. We propose STaR-KV (Spatio-Temporal Adaptive Re-weighting), a training-free KV cache compression framework that calibrates token importance along three axes: (i) subspace-aware scoring driven by online spatial mutual information; (ii) a temporal stability discount that suppresses redundant cache entries from persistently attended subspaces; and (iii) an entropy-derived temperature that adaptively reshapes the score distribution. Across four GUI benchmarks, STaR-KV achieves the strongest average accuracy among state-of-the-art KV compression methods (e.g., GUIKV, SnapKV) at matched budgets, with no compression-stage FLOPs overhead (-0.07%) and cutting peak GPU memory by nearly 40% at a 20% KV-cache budget. Code is available at https://github.com/kawhiiiileo/STaR-KV.
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Oct 30, 2025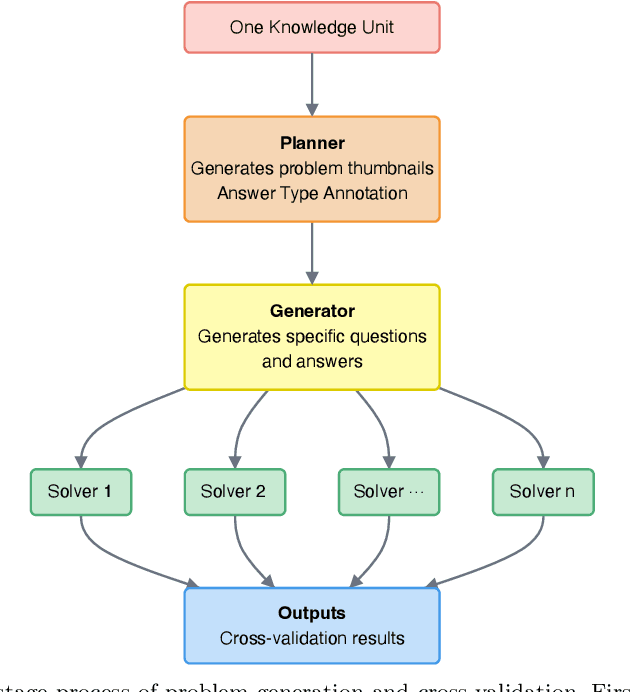
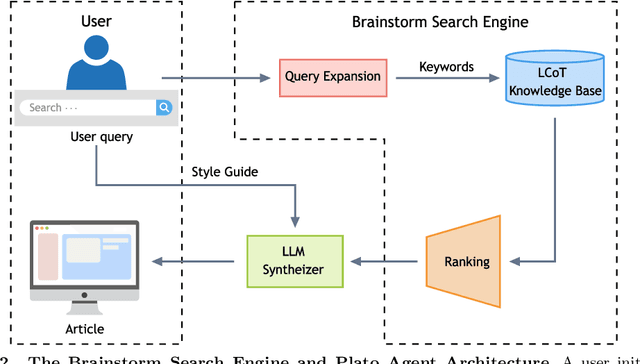
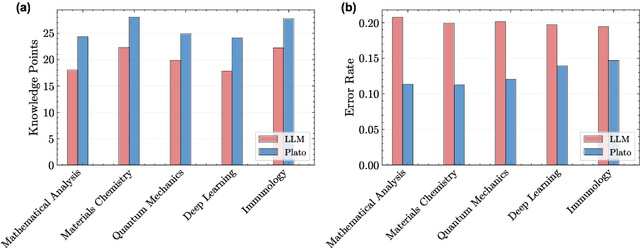
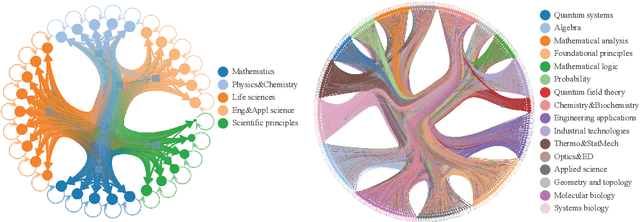
Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.
AudioMarathon: A Comprehensive Benchmark for Long-Context Audio Understanding and Efficiency in Audio LLMs
Oct 08, 2025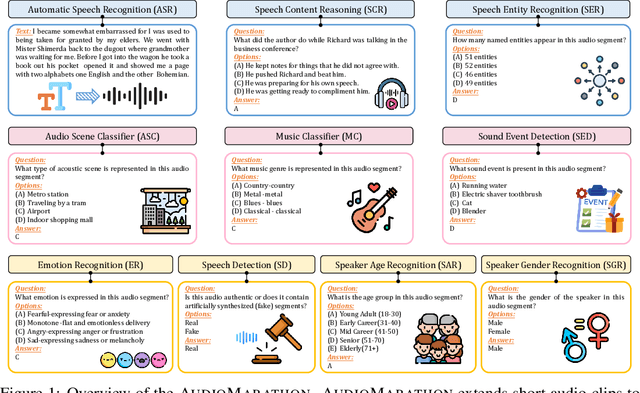
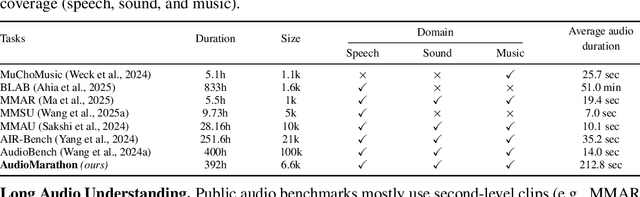
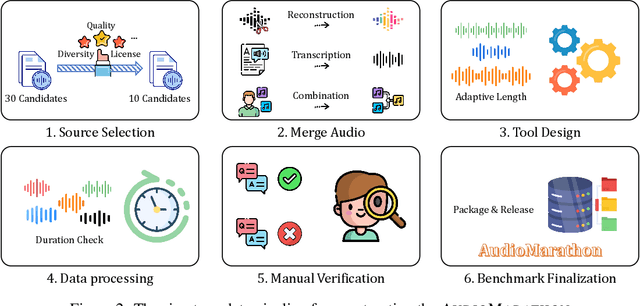

Processing long-form audio is a major challenge for Large Audio Language models (LALMs). These models struggle with the quadratic cost of attention ($O(N^2)$) and with modeling long-range temporal dependencies. Existing audio benchmarks are built mostly from short clips and do not evaluate models in realistic long context settings. To address this gap, we introduce AudioMarathon, a benchmark designed to evaluate both understanding and inference efficiency on long-form audio. AudioMarathon provides a diverse set of tasks built upon three pillars: long-context audio inputs with durations ranging from 90.0 to 300.0 seconds, which correspond to encoded sequences of 2,250 to 7,500 audio tokens, respectively, full domain coverage across speech, sound, and music, and complex reasoning that requires multi-hop inference. We evaluate state-of-the-art LALMs and observe clear performance drops as audio length grows. We also study acceleration techniques and analyze the trade-offs of token pruning and KV cache eviction. The results show large gaps across current LALMs and highlight the need for better temporal reasoning and memory-efficient architectures. We believe AudioMarathon will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
Shifting AI Efficiency From Model-Centric to Data-Centric Compression
May 25, 2025The rapid advancement of large language models (LLMs) and multi-modal LLMs (MLLMs) has historically relied on model-centric scaling through increasing parameter counts from millions to hundreds of billions to drive performance gains. However, as we approach hardware limits on model size, the dominant computational bottleneck has fundamentally shifted to the quadratic cost of self-attention over long token sequences, now driven by ultra-long text contexts, high-resolution images, and extended videos. In this position paper, \textbf{we argue that the focus of research for efficient AI is shifting from model-centric compression to data-centric compression}. We position token compression as the new frontier, which improves AI efficiency via reducing the number of tokens during model training or inference. Through comprehensive analysis, we first examine recent developments in long-context AI across various domains and establish a unified mathematical framework for existing model efficiency strategies, demonstrating why token compression represents a crucial paradigm shift in addressing long-context overhead. Subsequently, we systematically review the research landscape of token compression, analyzing its fundamental benefits and identifying its compelling advantages across diverse scenarios. Furthermore, we provide an in-depth analysis of current challenges in token compression research and outline promising future directions. Ultimately, our work aims to offer a fresh perspective on AI efficiency, synthesize existing research, and catalyze innovative developments to address the challenges that increasing context lengths pose to the AI community's advancement.
Data Whisperer: Efficient Data Selection for Task-Specific LLM Fine-Tuning via Few-Shot In-Context Learning
May 18, 2025Fine-tuning large language models (LLMs) on task-specific data is essential for their effective deployment. As dataset sizes grow, efficiently selecting optimal subsets for training becomes crucial to balancing performance and computational costs. Traditional data selection methods often require fine-tuning a scoring model on the target dataset, which is time-consuming and resource-intensive, or rely on heuristics that fail to fully leverage the model's predictive capabilities. To address these challenges, we propose Data Whisperer, an efficient, training-free, attention-based method that leverages few-shot in-context learning with the model to be fine-tuned. Comprehensive evaluations were conducted on both raw and synthetic datasets across diverse tasks and models. Notably, Data Whisperer achieves superior performance compared to the full GSM8K dataset on the Llama-3-8B-Instruct model, using just 10% of the data, and outperforms existing methods with a 3.1-point improvement and a 7.4$\times$ speedup.