 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoWorld-VLA: Thinking in a Multi-Expert World Model for Autonomous Driving
May 11, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for end-to-end autonomous driving. However, existing reasoning mechanisms still struggle to provide planning-oriented intermediate representations: textual Chain-of-Thought (CoT) fails to preserve continuous spatiotemporal structure, while latent world reasoning remains difficult to use as a direct condition for action generation. In this paper, we propose CoWorld-VLA, a multi-expert world reasoning framework for autonomous driving, where world representations serve as explicit conditions to guide action planning. CoWorld-VLA extracts complementary world information through multi-source supervision and encodes it into expert tokens within the VLA, thereby providing planner-accessible conditioning signals. Specifically, we construct four types of tokens: semantic interaction, geometric structure, dynamic evolution, and ego trajectory tokens, which respectively model interaction intent, spatial structure, future temporal dynamics, and behavioral goals. During action generation, CoWorld-VLA employs a diffusion-based hierarchical multi-expert fusion planner, which is coupled with scene context throughout the joint denoising process to generate continuous ego trajectories. Experiments show that CoWorld-VLA achieves competitive results in both future scene generation and planning on the NAVSIM v1 benchmark, demonstrating strong performance in collision avoidance and trajectory accuracy. Ablation studies further validate the complementarity of expert tokens and their effectiveness as planning conditions for action generation. Code will be available at https://github.com/potatochip1211/CoWorld-VLA.
EvoStreaming: Your Offline Video Model Is a Natively Streaming Assistant
May 11, 2026Streaming video understanding demands more than watching longer videos: assistants must decide when to speak in real time, balancing responsiveness against verbosity. Yet most video-language models (VideoLLMs) are trained for offline inference, and existing streaming benchmarks externalize this timing decision to the evaluator. We address this gap with RealStreamEval, a frame-level multi-turn evaluation protocol that exposes models to sequential observations and penalizes unnecessary responses. Under this protocol, we observed that strong offline VideoLLMs retain useful visual understanding but lack an interaction policy for deciding when to respond. Motivated by this observation, we propose EvoStreaming, a self-evolved streaming adaptation framework in which the base model itself acts as data generator, relevance annotator, and roll-out policy to synthesize streaming trajectories without external supervision. With only $1{,}000$ self-generated samples ($139\times$ less than the leading streaming instruction-tuning approach) and no architectural changes, EvoStreaming consistently improves the overall RealStreamEval score by up to $10.8$ points across five open VideoLLM backbones (Qwen2/2.5/3-VL, InternVL-3.5, MiniCPM-V4.5) while largely preserving offline video performance. These results suggest that data-efficient interaction tuning is a practical path for adapting existing VideoLLMs to streaming assistants.
AudioMarathon: A Comprehensive Benchmark for Long-Context Audio Understanding and Efficiency in Audio LLMs
Oct 08, 2025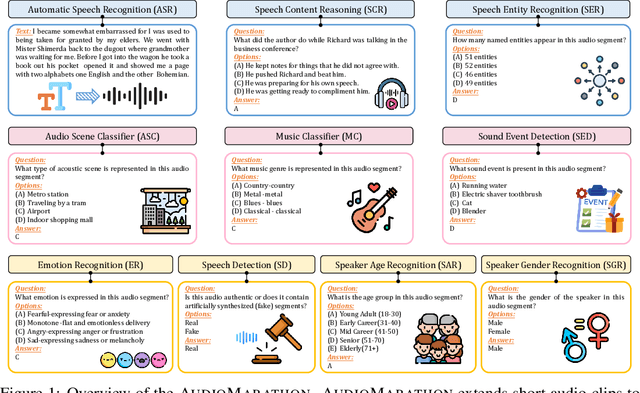
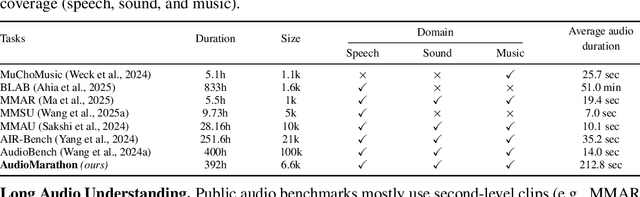
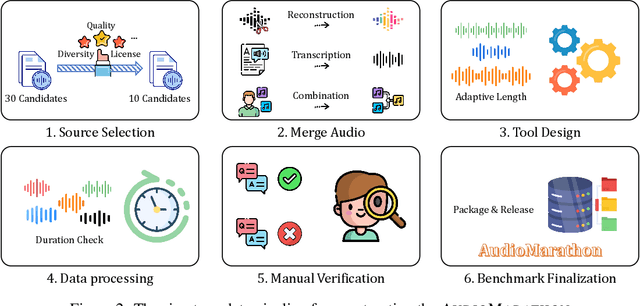

Processing long-form audio is a major challenge for Large Audio Language models (LALMs). These models struggle with the quadratic cost of attention ($O(N^2)$) and with modeling long-range temporal dependencies. Existing audio benchmarks are built mostly from short clips and do not evaluate models in realistic long context settings. To address this gap, we introduce AudioMarathon, a benchmark designed to evaluate both understanding and inference efficiency on long-form audio. AudioMarathon provides a diverse set of tasks built upon three pillars: long-context audio inputs with durations ranging from 90.0 to 300.0 seconds, which correspond to encoded sequences of 2,250 to 7,500 audio tokens, respectively, full domain coverage across speech, sound, and music, and complex reasoning that requires multi-hop inference. We evaluate state-of-the-art LALMs and observe clear performance drops as audio length grows. We also study acceleration techniques and analyze the trade-offs of token pruning and KV cache eviction. The results show large gaps across current LALMs and highlight the need for better temporal reasoning and memory-efficient architectures. We believe AudioMarathon will drive the audio and multimodal research community to develop more advanced audio understanding models capable of solving complex audio tasks.
Adaptive Query Prompting for Multi-Domain Landmark Detection
Apr 01, 2024



Medical landmark detection is crucial in various medical imaging modalities and procedures. Although deep learning-based methods have achieve promising performance, they are mostly designed for specific anatomical regions or tasks. In this work, we propose a universal model for multi-domain landmark detection by leveraging transformer architecture and developing a prompting component, named as Adaptive Query Prompting (AQP). Instead of embedding additional modules in the backbone network, we design a separate module to generate prompts that can be effectively extended to any other transformer network. In our proposed AQP, prompts are learnable parameters maintained in a memory space called prompt pool. The central idea is to keep the backbone frozen and then optimize prompts to instruct the model inference process. Furthermore, we employ a lightweight decoder to decode landmarks from the extracted features, namely Light-MLD. Thanks to the lightweight nature of the decoder and AQP, we can handle multiple datasets by sharing the backbone encoder and then only perform partial parameter tuning without incurring much additional cost. It has the potential to be extended to more landmark detection tasks. We conduct experiments on three widely used X-ray datasets for different medical landmark detection tasks. Our proposed Light-MLD coupled with AQP achieves SOTA performance on many metrics even without the use of elaborate structural designs or complex frameworks.