 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYufei Wang
Aligning Large Language Models with Human: A Survey
Jul 24, 2023
Large Language Models (LLMs) trained on extensive textual corpora have emerged as leading solutions for a broad array of Natural Language Processing (NLP) tasks. Despite their notable performance, these models are prone to certain limitations such as misunderstanding human instructions, generating potentially biased content, or factually incorrect (hallucinated) information. Hence, aligning LLMs with human expectations has become an active area of interest within the research community. This survey presents a comprehensive overview of these alignment technologies, including the following aspects. (1) Data collection: the methods for effectively collecting high-quality instructions for LLM alignment, including the use of NLP benchmarks, human annotations, and leveraging strong LLMs. (2) Training methodologies: a detailed review of the prevailing training methods employed for LLM alignment. Our exploration encompasses Supervised Fine-tuning, both Online and Offline human preference training, along with parameter-efficient training mechanisms. (3) Model Evaluation: the methods for evaluating the effectiveness of these human-aligned LLMs, presenting a multifaceted approach towards their assessment. In conclusion, we collate and distill our findings, shedding light on several promising future research avenues in the field. This survey, therefore, serves as a valuable resource for anyone invested in understanding and advancing the alignment of LLMs to better suit human-oriented tasks and expectations. An associated GitHub link collecting the latest papers is available at https://github.com/GaryYufei/AlignLLMHumanSurvey.
ExposureDiffusion: Learning to Expose for Low-light Image Enhancement
Jul 15, 2023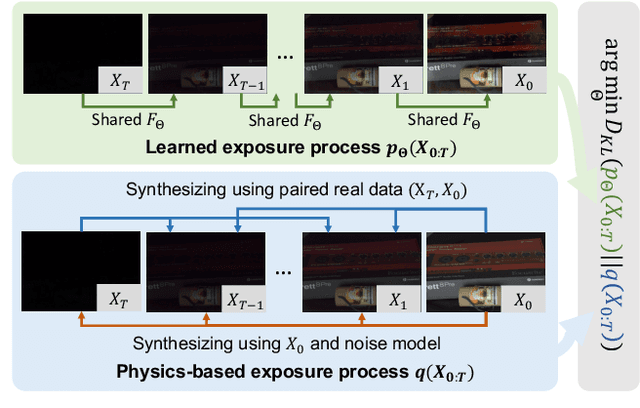

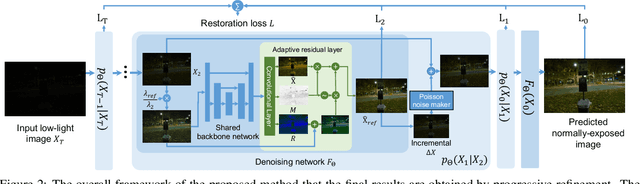
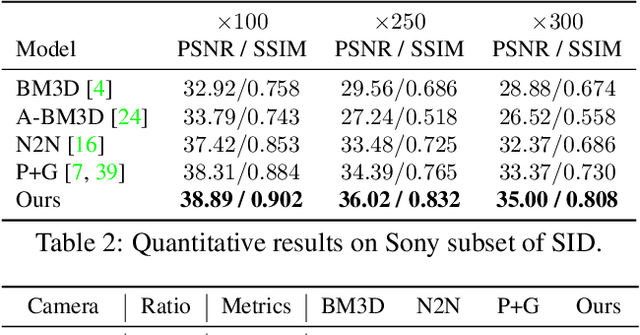
Previous raw image-based low-light image enhancement methods predominantly relied on feed-forward neural networks to learn deterministic mappings from low-light to normally-exposed images. However, they failed to capture critical distribution information, leading to visually undesirable results. This work addresses the issue by seamlessly integrating a diffusion model with a physics-based exposure model. Different from a vanilla diffusion model that has to perform Gaussian denoising, with the injected physics-based exposure model, our restoration process can directly start from a noisy image instead of pure noise. As such, our method obtains significantly improved performance and reduced inference time compared with vanilla diffusion models. To make full use of the advantages of different intermediate steps, we further propose an adaptive residual layer that effectively screens out the side-effect in the iterative refinement when the intermediate results have been already well-exposed. The proposed framework can work with both real-paired datasets, SOTA noise models, and different backbone networks. Note that, the proposed framework is compatible with real-paired datasets, real/synthetic noise models, and different backbone networks. We evaluate the proposed method on various public benchmarks, achieving promising results with consistent improvements using different exposure models and backbones. Besides, the proposed method achieves better generalization capacity for unseen amplifying ratios and better performance than a larger feedforward neural model when few parameters are adopted.
Separate-and-Aggregate: A Transformer-based Patch Refinement Model for Knowledge Graph Completion
Jul 11, 2023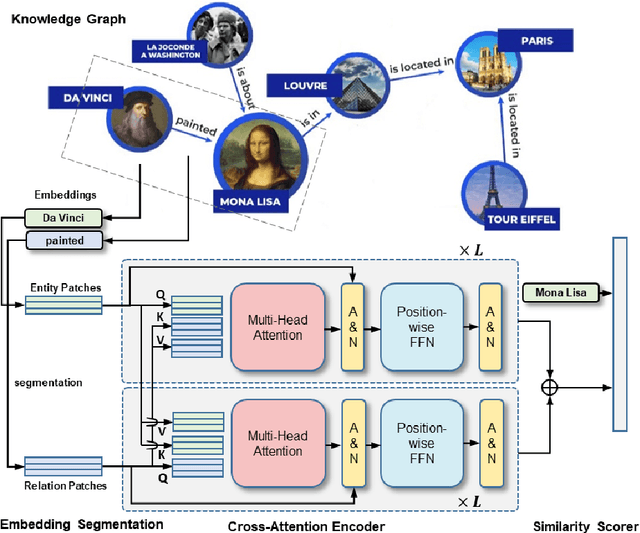
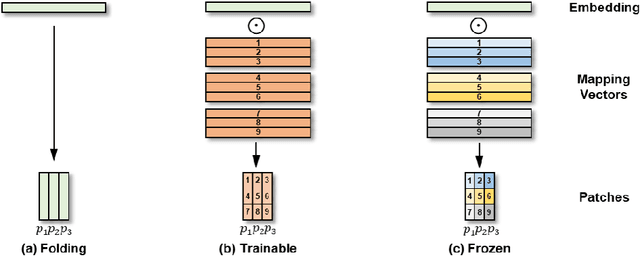
Knowledge graph completion (KGC) is the task of inferencing missing facts from any given knowledge graphs (KG). Previous KGC methods typically represent knowledge graph entities and relations as trainable continuous embeddings and fuse the embeddings of the entity $h$ (or $t$) and relation $r$ into hidden representations of query $(h, r, ?)$ (or $(?, r, t$)) to approximate the missing entities. To achieve this, they either use shallow linear transformations or deep convolutional modules. However, the linear transformations suffer from the expressiveness issue while the deep convolutional modules introduce unnecessary inductive bias, which could potentially degrade the model performance. Thus, we propose a novel Transformer-based Patch Refinement Model (PatReFormer) for KGC. PatReFormer first segments the embedding into a sequence of patches and then employs cross-attention modules to allow bi-directional embedding feature interaction between the entities and relations, leading to a better understanding of the underlying KG. We conduct experiments on four popular KGC benchmarks, WN18RR, FB15k-237, YAGO37 and DB100K. The experimental results show significant performance improvement from existing KGC methods on standard KGC evaluation metrics, e.g., MRR and H@n. Our analysis first verifies the effectiveness of our model design choices in PatReFormer. We then find that PatReFormer can better capture KG information from a large relation embedding dimension. Finally, we demonstrate that the strength of PatReFormer is at complex relation types, compared to other KGC models
Enhancing Low-Light Images Using Infrared-Encoded Images
Jul 09, 2023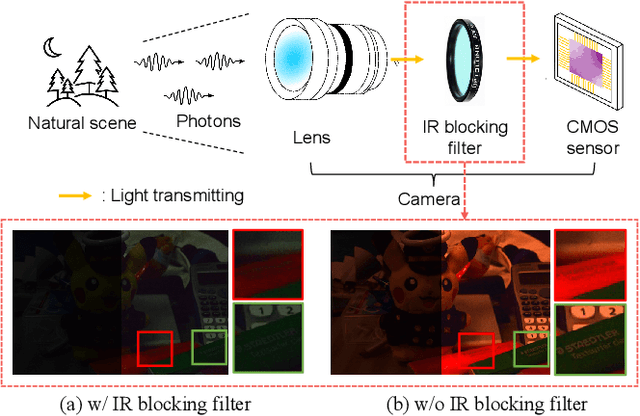
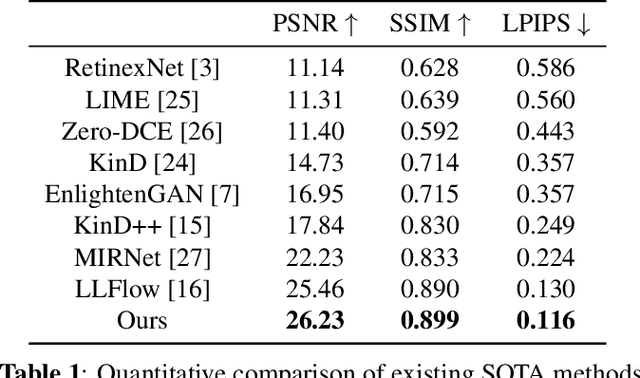

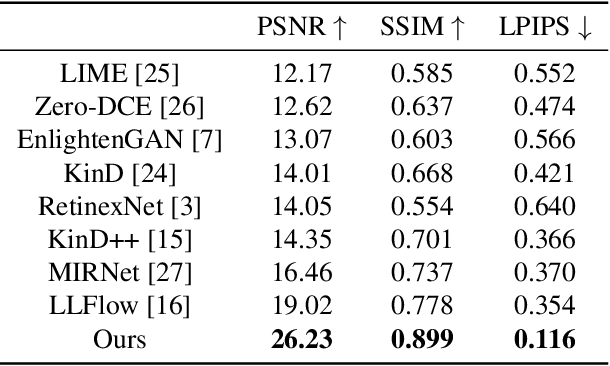
Low-light image enhancement task is essential yet challenging as it is ill-posed intrinsically. Previous arts mainly focus on the low-light images captured in the visible spectrum using pixel-wise loss, which limits the capacity of recovering the brightness, contrast, and texture details due to the small number of income photons. In this work, we propose a novel approach to increase the visibility of images captured under low-light environments by removing the in-camera infrared (IR) cut-off filter, which allows for the capture of more photons and results in improved signal-to-noise ratio due to the inclusion of information from the IR spectrum. To verify the proposed strategy, we collect a paired dataset of low-light images captured without the IR cut-off filter, with corresponding long-exposure reference images with an external filter. The experimental results on the proposed dataset demonstrate the effectiveness of the proposed method, showing better performance quantitatively and qualitatively. The dataset and code are publicly available at https://wyf0912.github.io/ELIEI/
Dipping PLMs Sauce: Bridging Structure and Text for Effective Knowledge Graph Completion via Conditional Soft Prompting
Jul 04, 2023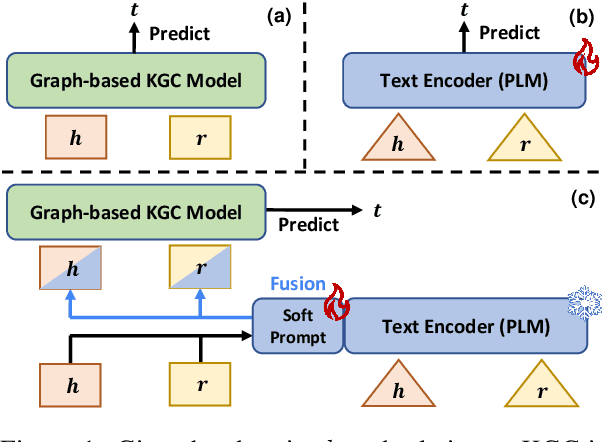
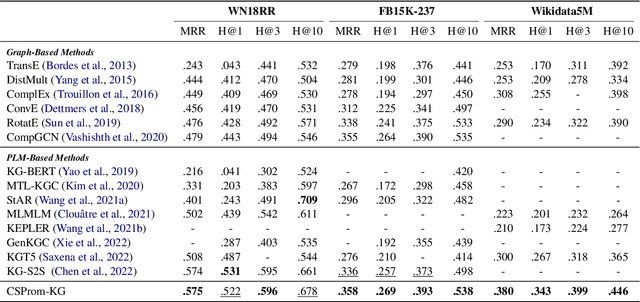
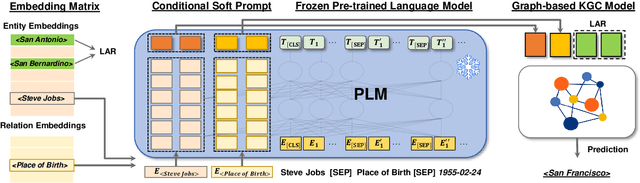
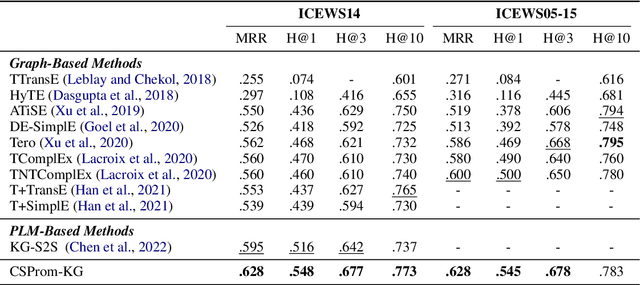
Knowledge Graph Completion (KGC) often requires both KG structural and textual information to be effective. Pre-trained Language Models (PLMs) have been used to learn the textual information, usually under the fine-tune paradigm for the KGC task. However, the fine-tuned PLMs often overwhelmingly focus on the textual information and overlook structural knowledge. To tackle this issue, this paper proposes CSProm-KG (Conditional Soft Prompts for KGC) which maintains a balance between structural information and textual knowledge. CSProm-KG only tunes the parameters of Conditional Soft Prompts that are generated by the entities and relations representations. We verify the effectiveness of CSProm-KG on three popular static KGC benchmarks WN18RR, FB15K-237 and Wikidata5M, and two temporal KGC benchmarks ICEWS14 and ICEWS05-15. CSProm-KG outperforms competitive baseline models and sets new state-of-the-art on these benchmarks. We conduct further analysis to show (i) the effectiveness of our proposed components, (ii) the efficiency of CSProm-KG, and (iii) the flexibility of CSProm-KG.
One Policy to Dress Them All: Learning to Dress People with Diverse Poses and Garments
Jun 21, 2023
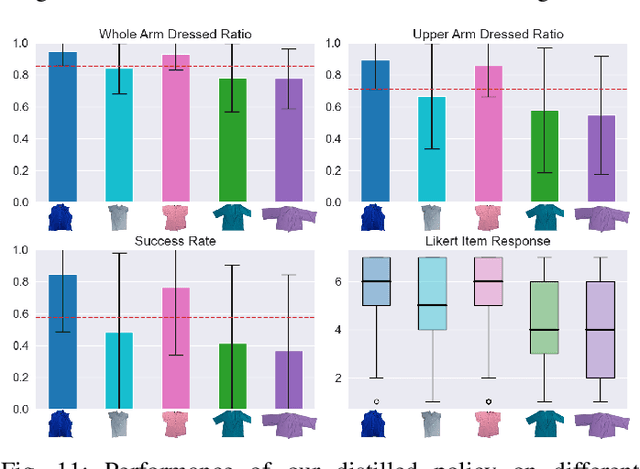
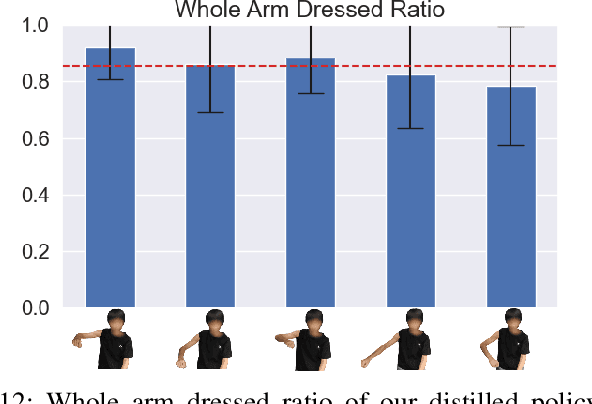
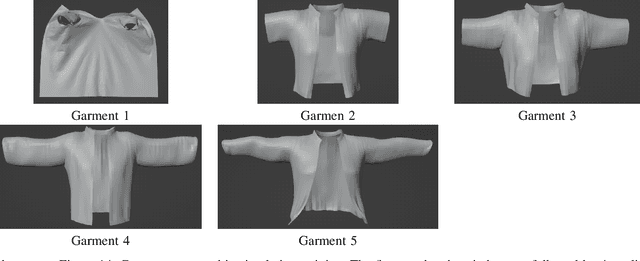
Robot-assisted dressing could benefit the lives of many people such as older adults and individuals with disabilities. Despite such potential, robot-assisted dressing remains a challenging task for robotics as it involves complex manipulation of deformable cloth in 3D space. Many prior works aim to solve the robot-assisted dressing task, but they make certain assumptions such as a fixed garment and a fixed arm pose that limit their ability to generalize. In this work, we develop a robot-assisted dressing system that is able to dress different garments on people with diverse poses from partial point cloud observations, based on a learned policy. We show that with proper design of the policy architecture and Q function, reinforcement learning (RL) can be used to learn effective policies with partial point cloud observations that work well for dressing diverse garments. We further leverage policy distillation to combine multiple policies trained on different ranges of human arm poses into a single policy that works over a wide range of different arm poses. We conduct comprehensive real-world evaluations of our system with 510 dressing trials in a human study with 17 participants with different arm poses and dressed garments. Our system is able to dress 86% of the length of the participants' arms on average. Videos can be found on our project webpage: https://sites.google.com/view/one-policy-dress.
Beyond Learned Metadata-based Raw Image Reconstruction
Jun 21, 2023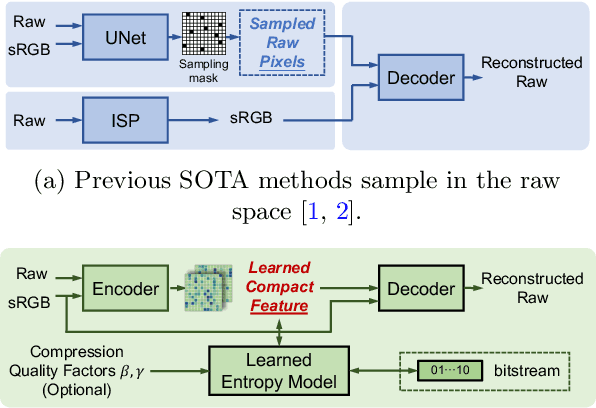
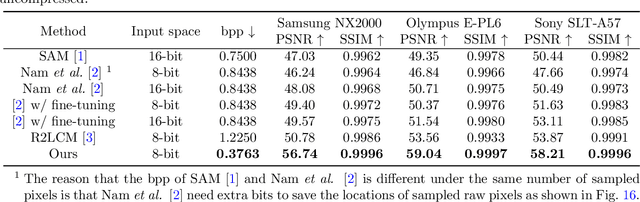
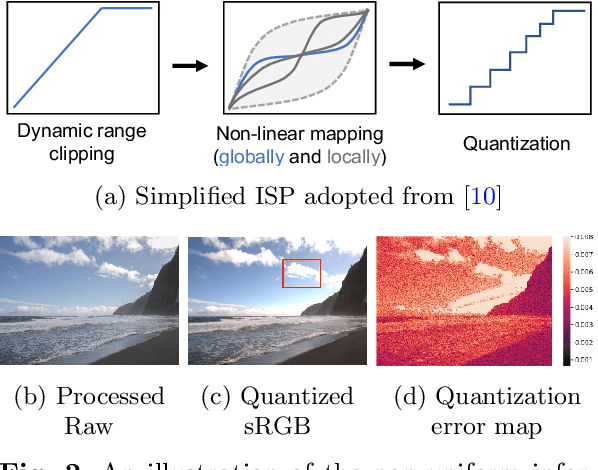
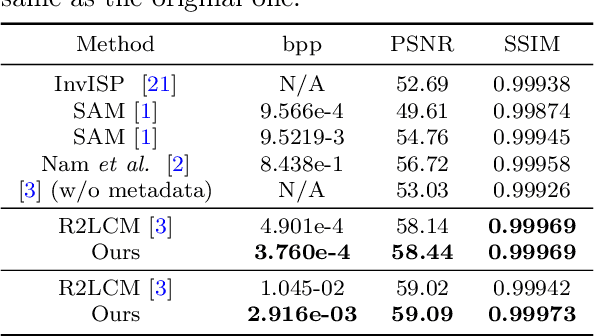
While raw images have distinct advantages over sRGB images, e.g., linearity and fine-grained quantization levels, they are not widely adopted by general users due to their substantial storage requirements. Very recent studies propose to compress raw images by designing sampling masks within the pixel space of the raw image. However, these approaches often leave space for pursuing more effective image representations and compact metadata. In this work, we propose a novel framework that learns a compact representation in the latent space, serving as metadata, in an end-to-end manner. Compared with lossy image compression, we analyze the intrinsic difference of the raw image reconstruction task caused by rich information from the sRGB image. Based on the analysis, a novel backbone design with asymmetric and hybrid spatial feature resolutions is proposed, which significantly improves the rate-distortion performance. Besides, we propose a novel design of the context model, which can better predict the order masks of encoding/decoding based on both the sRGB image and the masks of already processed features. Benefited from the better modeling of the correlation between order masks, the already processed information can be better utilized. Moreover, a novel sRGB-guided adaptive quantization precision strategy, which dynamically assigns varying levels of quantization precision to different regions, further enhances the representation ability of the model. Finally, based on the iterative properties of the proposed context model, we propose a novel strategy to achieve variable bit rates using a single model. This strategy allows for the continuous convergence of a wide range of bit rates. Extensive experimental results demonstrate that the proposed method can achieve better reconstruction quality with a smaller metadata size.
Unifying Large Language Models and Knowledge Graphs: A Roadmap
Jun 20, 2023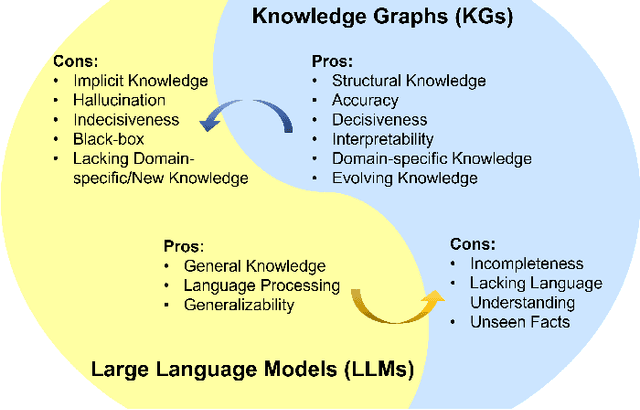
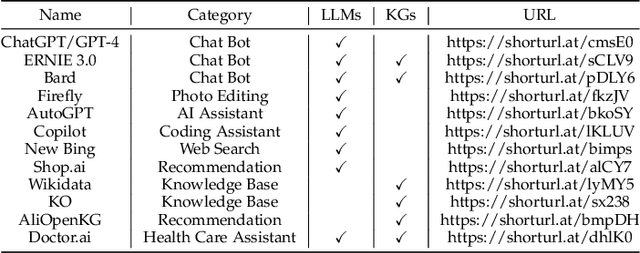
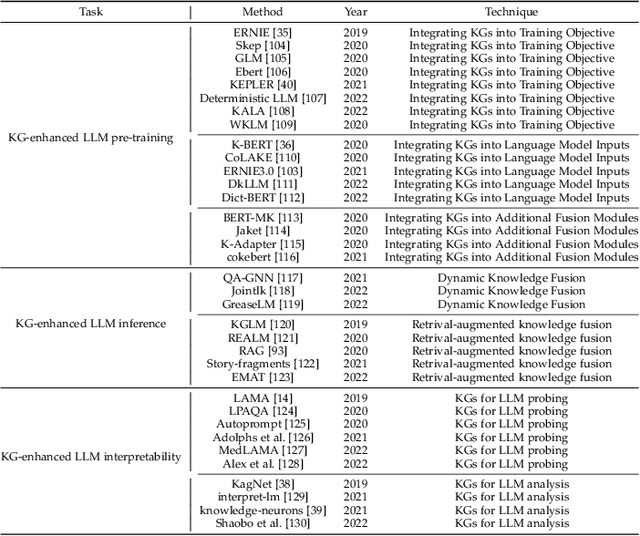
Large language models (LLMs), such as ChatGPT and GPT4, are making new waves in the field of natural language processing and artificial intelligence, due to their emergent ability and generalizability. However, LLMs are black-box models, which often fall short of capturing and accessing factual knowledge. In contrast, Knowledge Graphs (KGs), Wikipedia and Huapu for example, are structured knowledge models that explicitly store rich factual knowledge. KGs can enhance LLMs by providing external knowledge for inference and interpretability. Meanwhile, KGs are difficult to construct and evolving by nature, which challenges the existing methods in KGs to generate new facts and represent unseen knowledge. Therefore, it is complementary to unify LLMs and KGs together and simultaneously leverage their advantages. In this article, we present a forward-looking roadmap for the unification of LLMs and KGs. Our roadmap consists of three general frameworks, namely, 1) KG-enhanced LLMs, which incorporate KGs during the pre-training and inference phases of LLMs, or for the purpose of enhancing understanding of the knowledge learned by LLMs; 2) LLM-augmented KGs, that leverage LLMs for different KG tasks such as embedding, completion, construction, graph-to-text generation, and question answering; and 3) Synergized LLMs + KGs, in which LLMs and KGs play equal roles and work in a mutually beneficial way to enhance both LLMs and KGs for bidirectional reasoning driven by both data and knowledge. We review and summarize existing efforts within these three frameworks in our roadmap and pinpoint their future research directions.
Data Augmentation Approaches for Source Code Models: A Survey
Jun 12, 2023
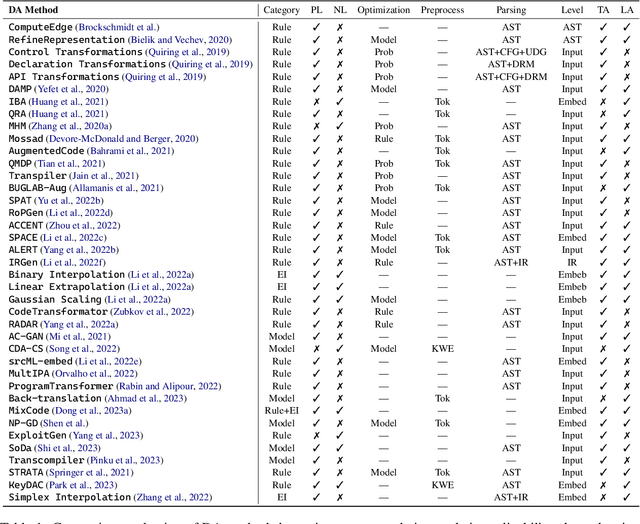

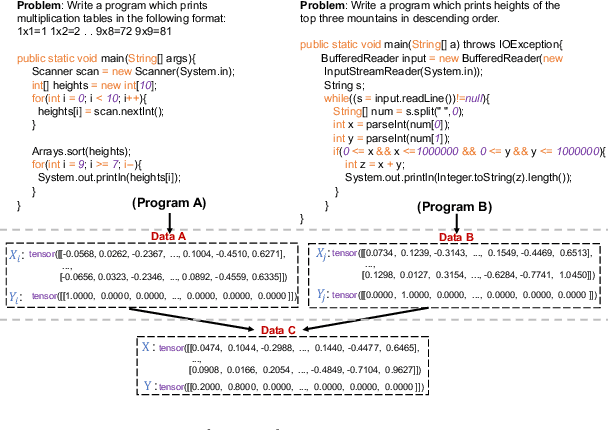
The increasingly popular adoption of source code in many critical tasks motivates the development of data augmentation (DA) techniques to enhance training data and improve various capabilities (e.g., robustness and generalizability) of these models. Although a series of DA methods have been proposed and tailored for source code models, there lacks a comprehensive survey and examination to understand their effectiveness and implications. This paper fills this gap by conducting a comprehensive and integrative survey of data augmentation for source code, wherein we systematically compile and encapsulate existing literature to provide a comprehensive overview of the field. We start by constructing a taxonomy of DA for source code models model approaches, followed by a discussion on prominent, methodologically illustrative approaches. Next, we highlight the general strategies and techniques to optimize the DA quality. Subsequently, we underscore techniques that find utility in widely-accepted source code scenarios and downstream tasks. Finally, we outline the prevailing challenges and potential opportunities for future research. In essence, this paper endeavors to demystify the corpus of existing literature on DA for source code models, and foster further exploration in this sphere. Complementing this, we present a continually updated GitHub repository that hosts a list of update-to-date papers on DA for source code models, accessible at \url{https://github.com/terryyz/DataAug4Code}.